标签:测试 情况下 否则 成本 优先 编号 互联网 统计 目标
目录
随着用户不断下单,DB订单表和订单附属表的单表记录数过大,影响到前端和管理系统拉取订单列表的性能。单表最大多少行合适与具体业务有关,难以下定论,但一般推荐不要超过1千万行,之后单表的性能下降会比较明显。
本文档整理了数据库大表优化的一些常用思路的原理,最后针对订单表提出优化方案。
什么是分区?
就是将一张表的单个大文件,按一定逻辑拆分成多个物理的区块文件。对于应用程序来说,还是一张整表;但底层实际上是由多个物理区块组成。目前主流的DB如Oracle、MySql等都有成熟的方案支持分区
MySql支持哪些分区类型?
MySql的分区限制?
MySql如何对现有表分区或修改分区参数?
分区的优势?
接下来我们来具体思考针对订单表,如何优化:
示例一:以用户ID做HASH分区
之前runner指出用户对订单表的查询,都基于用户ID的,每个用户只能拉取自己的订单信息。所以对于订单表,可以以用户ID作为分区字段将订单表分区打散;这就要求原有的主键(自增ID)和唯一索引(订单ID)都修改为组合索引,分别是自增ID+用户ID、订单ID+用户ID。保留原有的用户ID的普通索引。比如我们创建4个分区。
示例二:组合分区,range自增ID,hash用户ID
这个方案可以进一步打散数据,比如range出4个分区,每个range分区再做4个hash子分区。
采用此方案,主键和唯一索引需要扩展到3个字段。
示例三:组合分区,list订单ID,hash用户ID
电商的订单展示,有个特点,分待付款、待发货、待收货及全部订单等,很多时候用户是单独拉取待发货、待收货的订单页面的,这时我们可以将订单表按状态做一次list分区,再以用户ID hash出子分区。
同方案二,采用此方案也需要将主键和唯一索引扩展到3个字段。
分表的一个应用场景是替代分区,预先创建多个表名不同但表结构一致的表,并给每个表编号,应用程序在写或读之前先用ID取模等方式得到表编号,从而实现单表分区。
本章我们侧重于用分表来扩展分区的功能,我们来看某金融交易平台的实际案例,将订单表划分成多个小表来分散不同的业务请求:
针对电商的订单表,我们也可以有类似的思路,比如用户拉取订单数据时往往分待付款、待发货、待收货、全部订单等,除了全部订单列表外,前端是按不同阶段来拉取和展示订单的,所以我们可以将不同阶段的订单移到不同的表中,降低单表的记录数来提高查询效率。
再比如历史表,前端拉取1个月前甚至1年前的已完成订单的机会是不多的,可以将一定时间以前的记录移到历史表去。
随着业务量进一步增长,单个DB实例已经无法支撑大量的用户请求时,可以考虑根据业务分库,甚至是对单个业务进行细粒度的分库,将不同的请求分散到不同的库去处理,硬件成本换性能。目前我们平台后台与前端业务部门的后台系统DB是分离的,这就是个分库的案例。
有了前面的分区、分表,分库的思路应该很好理解,就目前而言,我暂时没有看到我们有进一步分库的需求,线上业务都在公有云,一般的性能增长需求可以先通过快速的单库扩容实现。如果后续需要,可以先考虑将商品中心、用户中心等强业务相关的子系统分离;业务量继续增长时,还可以考虑更细粒度的,比如就订单表而言,也可以将各个子表分离到不同的DB去。当然,这些操作对我们的应用开发提出更高的适配要求,业界也有成熟的如mycat等中间件方案。
读写分离和DB集群是互联网架构常用的方案,我们也已经实现了一部分,这种方案主要是为了解决读远大于写的情况,可以是一主一从、一主多从、多主多从等,本质上是将数据拷贝多份,由多个DB实例同时负载前端应用,以硬件成本换性能。该方案在提升读的性能、HA等方面效果明显,但并未真正解决订单表单表过大的问题,这里就不展开说了。
一个高性价比的缓存设计,适合更新少、读取多的数据,比如商品,大量的用户请求会拉取商品信息,真正下单的会少很多,缓存商品信息可以拦截下大量的重复的请求。至于订单信息,每个用户只能拉取自己的订单,每个订单被访问到的次数是很少的,所以为订单创建缓存的性价比就显得很低。这里也不展开讨论了。
参考Fylos推荐的这篇博文:http://www.sohu.com/a/327627159_315839
京东到家的订单系统主要依赖ES集群来承担订单查询的压力,目前支撑10亿文档数和5亿的日均查询量。
这是订单业务涉及的主要表的关系图,图中我整理了select/update涉及的where的主要条件字段(索引),其中Ux表示唯一索引,Ix表示普通索引:
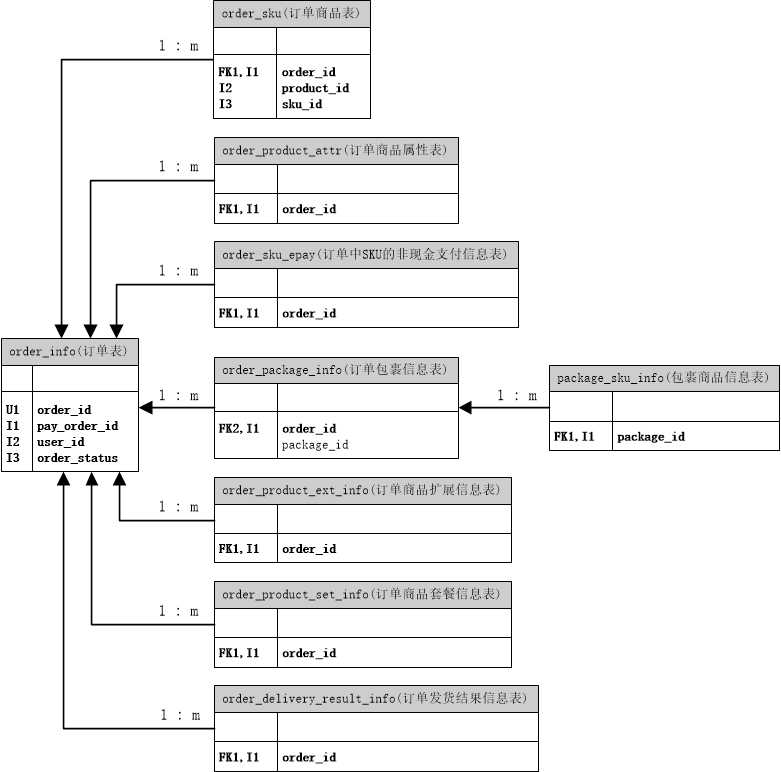
目前我们的订单表记录数不到500万,远没到需要分库、建集群才能支撑性能的地步;而订单的查询频率并不高,性能主要受单表数据量太大限制,所以建缓存的意义也不大;至于用ES来代替DB查询,引入了新的数据节点和数据同步的需要,在分区和分表能解决问题的情况下,使用ES属于过度优化,没这必要。
所以接下来我们直接讨论怎么分区、分表。此外,分区对业务代码是无感知的,分表需要修改业务逻辑,所以推荐优先选择分区。
| 序号 | 表名 | 记录数 |
|---|---|---|
| 1 | order_info | 4507745 |
| 2 | order_sku | 4885235 |
| 3 | order_product_attr | 25450856 |
| 4 | order_sku_epay | 5772024 |
| 5 | order_product_ext_info | 2927387 |
| 6 | order_product_set_info | 14677 |
| 7 | order_package_info | 1139441 |
| 8 | package_sku_info | 213238 |
从上表来看,前4张表的记录数比较大,也是大部分请求集中的表,需要优化。
分区思路:以order_id为分区键;以当前数据量为基础,每个分区记录数50万以内。
| 表名 | 分区数 | 每个分区的平均记录数 |
|---|---|---|
| order_sku | 16 | 30.5万 |
| order_product_attr | 64 | 39.8万 |
| order_sku_epay | 16 | 36.1万 |
这个分区设计下,即使在我们的业务增长10倍之后,每个分区的记录数在400万左右,也能很好的支撑。当然,后面我们可能得考虑一些分表、分库的设计了。
存在的问题:管理系统单独以product_id/sku_id筛选时,无法锁定分区。考虑到这个请求不是很多,可以走普通索引。
order_info表的业务特点:
结合上述业务特点,可以将order_info拆分为主表order_info和历史表order_info_his,同时order_info_his表可以按user_id分区,保证用户端拉取的速度。
主表order_info:
历史表order_info_his:
代码逻辑变更:
标签:测试 情况下 否则 成本 优先 编号 互联网 统计 目标
原文地址:https://www.cnblogs.com/JoZSM/p/11784078.html