标签:联合 科学家 目的 into cti 结构 mat 误差 nal
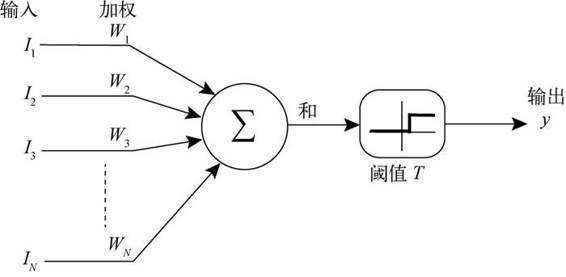
人工神经网络

|
算法名称
|
算法描述
|
|---|---|
| ANFIS自适应神经网络 | 神经网络镶嵌在一个全部模糊的结果之中,在不知不觉中向训练数据学习,自动生产,修正并高度概括出最佳的输入与输出变量的隶属函数以及模糊规则;另外,神经网络的各层结构于参数也都具有了明确的,易于理解的物理意义. |
| BP神经网络 | 是一种按误差逆传播算法训练的多层前馈网络,学习算法是δ学习规则,是目前应用最广泛的神经网络模型之一 |
| FNN神经网络 | FNN模糊神经网络是具有模糊权系数或者输入信号是模糊量的神经网络,是模糊系统与神经网络项结合的产物,它汇聚了神经网络与模糊系统的优点,集联想,识别,自适应及模糊信息处理于一体. |
| GMDH神经网络 | GMGH网络也称为多项式网络,它是前馈神经网络中常用的一种用于预测的神经网络,它的特点是网络结构不固定,而且在训练过程中不断改变 |
| LM神经网络 | 是基于梯度下降法和牛顿法结合的多层前馈网络,特点:迭代次数少,收敛速度快,精确度高 |
| RBF径向基神经网络 |
RBF网络能够以任意精度逼近任意连续函数,从输入层到隐含层的变换是非线性的,而从隐含层到输出层的变换是线性的,特别适合于解决分类问题 |
# -*- coding:utf-8 -*- import sys reload(sys) sys.setdefaultencoding("utf-8") """ 使用神经网络算法预测销量高低 """ # 参数初始化 import pandas as pd data = pd.read_csv("./sales.csv", header=None, sep="\t", names=["date", "sale", "item1", "item2", "item3", "item4"]) # 根据类别表前转化成数据 data[data["item1"] == u"好"] = 1 data[data["item1"] != u"好"] = 0 data[data["item2"] == u"好"] = 1 data[data["item2"] != u"好"] = 0 data[data["item3"] == u"好"] = 1 data[data["item3"] != u"好"] = 0 data[data["item4"] == u"好"] = 1 data[data["item4"] != u"好"] = 0 x = data.iloc[:, :3].as_matrix().astype(int) # 转化称int y = data.iloc[:3].as_matrix().astype(int) # 转化成int from keras.models import Sequential from keras.layers.core import Dense, Activation model = Sequential() # 建立模型 model.add(Dense(3, 10)) model.add(Activation(‘relu‘)) # 用relu函数作为激活函数,能够大幅提供精准度 model.add(Dense(10, 1)) model.add(Activation(‘sigmoid‘)) # 由于是0-1输出,用sigmoid函数作为激活函数 model.compile(loss=‘binary_crossentropy‘,optimizer=‘adam‘, class_mode=‘binary‘) # 编译 模型,由于做的是二元分类,所以指定损失函数为binary_crossentropy,以及模式为binary # 另外常见的损失函数还有mean_squared_error,categorical_crossentropy等, model.fit(x,y, nb_epoch=1000, batch_size=10) # 训练模型 # 学习1000次 yp = model.predict_classes(x).reshape(len(y)) # 分类预测
标签:联合 科学家 目的 into cti 结构 mat 误差 nal
原文地址:https://www.cnblogs.com/ljc-0923/p/11785574.html