标签:输入 问题 str 矩阵 介绍 解码 div 之间 预测
2.Attention Mechanism原理
要介绍Attention Mechanism结构和原理,首先需要介绍下Seq2Seq模型的结构。Seq2Seq模型,想要解决的主要问题是,如何把机器翻译中,变长的输入X映射到一个变长输出Y的问题,其主要结构如图3所示。
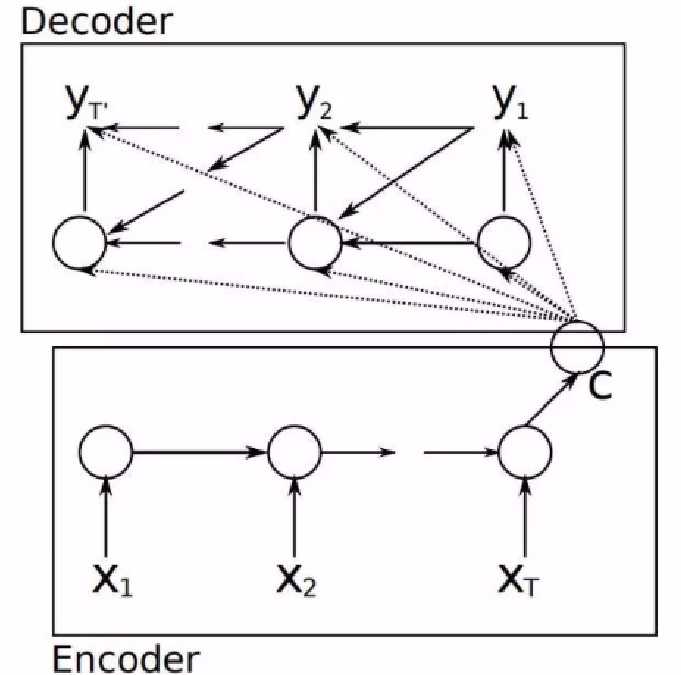
图3 传统的Seq2Seq结构
从图中可以看出,seq2seq模型分为两个阶段:编码阶段和解码阶段。
编码阶段:
把一个变长的输入序列x1,x2,x3....xt输入RNN,LSTM或GRU模型,然后将得到各个隐藏层的输出进行汇总,生成语义向量:
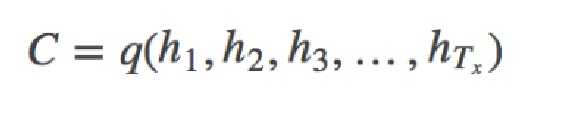
也可以将最后的一层隐藏层的输出作为语义向量C :
这里的语义向量c有两个作用:1、做为decoder模型预测y1的初始向量。2、做为语义向量,指导y序列中每一个step的y的产出。
解码阶段:
Decoder主要是基于语义向量c和上一步的输出yi-1解码得到该时刻t的输出yi:
yi=g(yi-1,Si,C)
其中Si为隐藏层的输出。其中g代表的是非线性激活函数。
直到碰到结束标志(<EOS>),解码结束。
以上就是seq2seq的编码解码阶段。从上面可以看出,该模型存在两个明显的问题:
1、把输入X的所有信息有压缩到一个固定长度的隐向量C。当输入句子长度很长,特别是比训练集中最初的句子长度还长时,模型的性能急剧下降。
2、把输入X编码成一个固定的长度,对于句子中每个词都赋予相同的权重,这样做是不合理的,比如,在机器翻译里,输入的句子与输出句子之间,往往是输入一个或几个词对应于输出的一个或几个词。因此,对输入的每个词赋予相同权重,这样做没有区分度,往往是模型性能下降。
因此,需要引入Attention Mechanism来解决这个问题。
我们将解码yi时的公式改为如下形式:
yi=g(yi-1,Si,Ci)
即不同时刻的输出y使用不同的语义向量。
其中,si是decoder中RNN在在i时刻的隐状态,其计算公式为:
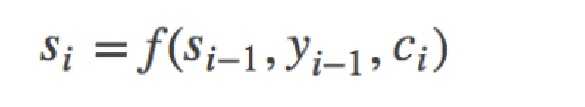
这里的语义向量ci的计算方式,与传统的Seq2Seq模型直接累加的计算方式不一样,这里的ci是一个权重化(Weighted)之后的值,其表达式如公式5所示:
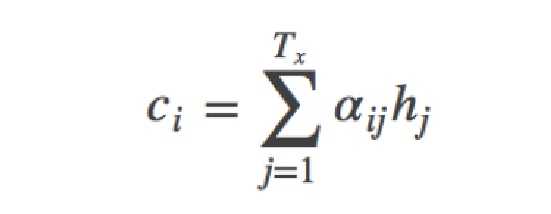
其中,i表示decoder端的第i个词,hj表示encoder端的第j个词的隐向量,aij表示encoder端的第j个词与decoder端的第i个词之间的权值,表示源端第j个词对目标端第i个词的影响程度,aij的计算公式如公式6所示:
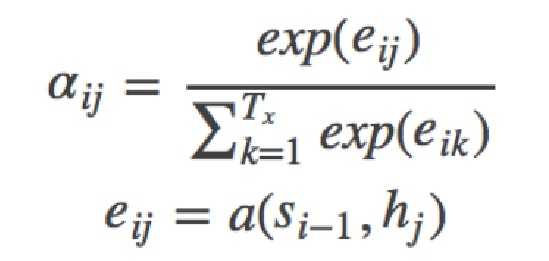
在公式6中,aij是一个softmax模型输出,概率值的和为1。eij用于衡量encoder端的位置j个词,对于decoder端的位置i个词的影响程度,换句话说:decoder端生成位置i的词时,有多少程度受encoder端的位置j的词影响。eij的计算方式有很多种,不同的计算方式,代表不同的Attention模型,最简单且最常用的的对齐模型是dot product乘积矩阵,即把解码端的输出隐状态ht与编码端的输出隐状态hs进行矩阵乘。常见的对齐计算方式如下:
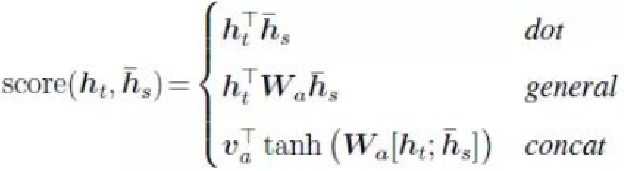
常见的计算方式有以上几种方式。点乘(Dot product),权值网络映射(General)和concat映射几种方式。
标签:输入 问题 str 矩阵 介绍 解码 div 之间 预测
原文地址:https://www.cnblogs.com/yangyanfen/p/11785964.html