标签:之间 遇到 语言 附加 有一个 排除 自己 算法 原来
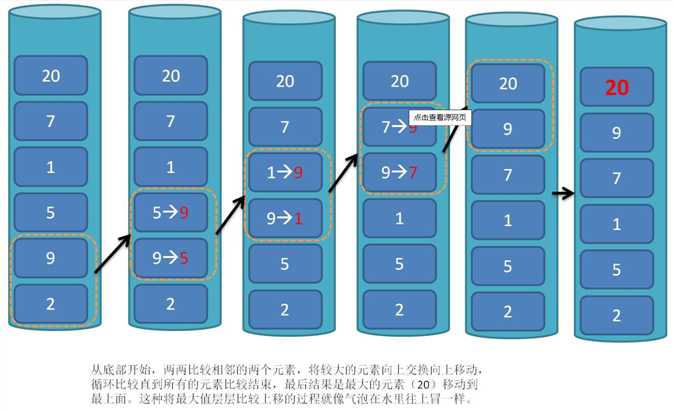
-插入排序就是将队列里一个又一个的值,插入到已经排序的子序列,如下面序列
20 18 23 21 20 19 11 02 21 14 55又大到小,先比较前两个,20>18,所以序列不懂,再提取出23,与实现比较的那个两个序列先比较,发现23>20,所以23就在20、18的前面,后面数字以此类推,最后我们就可以得到序列的结果了!个人认为插入排序可以保证算法的稳定性(现对于选择排序来说)

int aFunc(int n) {
for(int i = 0; i<n; i++) { // 需要执行 (n + 1) 次
printf("Hello, World!\n"); // 需要执行 n 次
}
return 0; // 需要执行 1 次
}这个代码需要执行n+1+n+1次,即2n+2次运算,那它的大o记数法又是多少?由大一的高数学习我们知道,随着循环次数的增加,常数项对函数的影响并不大,而n的一次项的影响又会若雨n的二次项,所以当函数中只有常数项时,大o计数法就是O(1),如果是有n的一次项,如上图所示的话,大O计数法就是O(n),有n的二次方,大O技术法就是:O(n^2)如下面的代码所示
void aFunc(int n) {
for(int i = 0; i < n; i++) { // 循环次数为 n
for(int j = 0; j < n; j++) { // 循环次数为 n
printf("Hello, World!\n"); // 循环体时间复杂度为 O(1)
}
}
}运算次数为n(n+1)。
当中,对于顺利执行的语句算法,总的时间复杂度,等于其中最大的时间复杂度如下面代码
void aFunc(int n) {
// 第一部分时间复杂度为 O(n^2)
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
printf("Hello, World!\n");
}
}
// 第二部分时间复杂度为 O(n)
for(int j = 0; j < n; j++) {
printf("Hello, World!\n");
}
}此时时间复杂度为 max(O(n^2), O(n)),即 O(n^2)。
<快速排序1》
由上图可知,我们设置两个指针,一个指向末尾,一个指向队头,设末尾的low所在的数为基准数,则大于基准数的放右边,小于基准数的放左边,这样就可以找到基准数正确位置
《快速排序2》
3
4
5
low和high相等的时候我们结束循环,这样就是找到了第一个基数的正确位置,照此多运行几轮,我们就会发现快速排序确实会比其他算法的速度快得很多,它先定义一个分界数,将左侧小于它,右侧大于它,再对两侧进行再次划分,如此重复,极大的加快了算法的运行速度。
如下为快速排序代码
private static int getIndex(int[] arr, int low, int high) {
// 基准数据
int tmp = arr[low];
while (low < high) {
// 当队尾的元素大于等于基准数据时,向前挪动high指针
while (low < high && arr[high] >= tmp) {
high--;
}
// 如果队尾元素小于tmp了,需要将其赋值给low
arr[low] = arr[high];
// 当队首元素小于等于tmp时,向前挪动low指针
while (low < high && arr[low] <= tmp) {
low++;
}
// 当队首元素大于tmp时,需要将其赋值给high
arr[high] = arr[low];
}
// 跳出循环时low和high相等,此时的low或high就是tmp的正确索引位置
// 由原理部分可以很清楚的知道low位置的值并不是tmp,所以需要将tmp赋值给arr[low]
arr[low] = tmp;
return low; // 返回tmp的正确位置
}
}问题3:什么是归并排序?如何实现归并排序?
问题3解决方法:
归并排序如下图所有演示一般
归并排序1
有了图以后,上面的都很好理解,那么应该如何合并归并排序的数组呢?我们有下面的方法
归并排序2
有了这两张图就很清晰的解释清楚归并排序是如何实现的了,代码如下
public static void mergeSort(int[] arr) {
sort(arr, 0, arr.length - 1);
}
public static void sort(int[] arr, int L, int R) {
if(L == R) {
return;
}
int mid = L + ((R - L) >> 1);
sort(arr, L, mid);
sort(arr, mid + 1, R);
merge(arr, L, mid, R);
}
public static void merge(int[] arr, int L, int mid, int R) {
int[] temp = new int[R - L + 1];
int i = 0;
int p1 = L;
int p2 = mid + 1;
// 比较左右两部分的元素,哪个小,把那个元素填入temp中
while(p1 <= mid && p2 <= R) {
temp[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
}
// 上面的循环退出后,把剩余的元素依次填入到temp中
// 以下两个while只有一个会执行
while(p1 <= mid) {
temp[i++] = arr[p1++];
}
while(p2 <= R) {
temp[i++] = arr[p2++];
}
// 把最终的排序的结果复制给原数组
for(i = 0; i < temp.length; i++) {
arr[L + i] = temp[i];
}
} Comparebale tree = new Comparebale(b);
Comparebale head =new Comparebale(-1);
head.setNext(tree);
for(int i=1;i<n.length;i++)
{
int num =Integer.parseInt(n[i]);
tree = head.getNext();
while (tree!= null)
{
if(tree.geti()<num)
tree = tree.getNext();
else if(tree.geti()>num)
tree = tree.getSecondnext();
}
tree = new Comparebale(num);
}
tree = head.getNext();
boolean i = searching.erchashu(tree,target);
System.out.println(i);我们通过dubug发现,树头的树枝被砍断了,所以才会找不到数字1,即head.getnext原本是想让tree这个指针回到树头的,但是谁曾想到,它居然把连起来的tree的树枝给砍断了,导致tree19的下两个节点全部都是null,我们通过与之前写的链表的代码进行了对比研究初步怀疑,此类构建数的是否只能在类里的方法才能实现,于是编写了一下代码来构建二叉树
package newwork;
public class erchashu {
Comparebale tree = new Comparebale(-1);
Comparebale head = new Comparebale(-1);
int[] a = new int[12];
public erchashu()
{
head.setNext(tree);
}
public void s(int[] b)
{
tree.setI(b[0]);
for(int i=1;i<b.length;i++)
{
Comparebale c = new Comparebale(b[i]);
tree = head.getNext();
while (tree.geti()!=b[i])
{
if(tree.geti()<b[i]&&(tree.getNext()!=null))
{
tree = tree.getNext();
}
else if(tree.geti()<b[i]&&tree.getNext()==null)
{
tree.setNext(c);
tree=c;
}
else if(tree.geti()>b[i]&&tree.getSecondnext()!=null)
tree = tree.getSecondnext();
else if(tree.geti()>b[i]&&tree.getSecondnext()==null)
{
tree.setSecondnext(c);
tree = c;
}
}
}
}
public Comparebale get()
{
return head.getNext();
}
}
由以上的代码看,我们改进了好几个方面,在循环里创建了一个变量c,利用添加元素进链表里的方法,将数给连接起来,然后运行看看
《二叉树运行图》
由图可看出,我们的运行成功了,方法有效,但是具体为什么在类中树枝不会被砍断,这发面还是要再研究研究
我进过debug查找,发现原因有几个:
1、在链中插入新的节点的时候只能a[i1]就跳到下面的节点去了,然后回不来,而用头指针的时候又再次出现了砍断数枝的问题
2、判定条件设置的不对,应当利用的是我们上面二叉树的判定条件,当当前节点不为空,其下一个节点也不为空的时候才可以跳入到下一个节点中去。
之前的问题都好解决,设计附加条件就好了,但是对于如何处理头被砍掉的问题,盛世难搞,我认为树枝没连上的话,应该是用前面几张中的链表连接的方法连接,但是对于回到头链表就被砍断了的问题,还需要研究研究。
经过改进,此代码目前只能连续插入两到三个数字,无法插入的更多(尽力了。。。。)
package newwork;
import java.util.Scanner;
public class haxilianbiao {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
Comparebale[] data = new Comparebale[12];
Comparebale target ;
Searching searching = new Searching();
String s = "19 14 23 1 68 20 84 27 55 11 10 79";
String[] n = s.split("\\s");
System.out.println("请输入你想要查找的数(哈希链表查找)");
int a = scan.nextInt();
target = new Comparebale(a);
/* for(int i =0 ; i<data.length;i++)//哈希链表
{
data[i] = new Comparebale(-1);
}*/
for(int i = 0;i<n.length;i++)
{
int num = Integer.parseInt(n[i]);
int i1 = num%11;
if(data[i1]==null)
data[i1]= new Comparebale(num);
if (data[i1]!=null)
{
Comparebale c = new Comparebale(num);
data[i1].setNext(c);
}
/*if(data[i1]==null)
data[i1] = new Comparebale(num);*/
}
boolean i = searching.lianbiao(data,target);
if(i)
System.out.println("数字存在已找到");
else
System.out.println("数字不存在找不到");
}
}
《哈希链表查找运行结果》
由图中可以看出,循环根本没有进行,直接就跳出去了。是啥原因呢?
经过仔细的审查,发现,是循环的条件出错了,midpoit的加减搞反了,所以循环根本没有执行
最终运行结果如下图
《search 最终 运行结果》
(statistics.sh脚本的运行结果截图)
上周无考试
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 623/1000 | 3/7 | 22/60 | |
| 第四周 | 600/1600 | 2/9 | 22/82 | |
| 第五周 | 1552/2987 | 2/11 | 22/94 | |
| 第六周 | 892/3879 | 2/11 | 22/114 | |
| 第七周 | 2284/6163 | 2/13 | 42/156 | |
| 第八周 | 2284/6163 | 2/13 | 40/196 |
计划学习时间:10小时
实际学习时间:8小时
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)
标签:之间 遇到 语言 附加 有一个 排除 自己 算法 原来
原文地址:https://www.cnblogs.com/yangkaihan/p/11788056.html