标签:返回 查看 有一个 系统 忽略 常用选项 style rand 说明
在日常使用中grep命令也是会经常用到的一个搜索命令。grep命令用于在文本中执行关键词搜索,并显示匹配的结果。
grep [选项] [文件]
Usage: grep [OPTION]... PATTERN [FILE]...
-b,--byte-offset 将可执行文件binary当作文本文件来搜索
-c,--count 仅显示找到的行数
-i , --ignore-case 忽略大小写
-n,--line-number 显示行号
-v, --revert-match 取反,列出没有“关键词”的行
-w, --word-regex 按单词搜索,仅匹配这个字符串
-r 逐层便利目录查看
--color 匹配到的行高亮显示
--include 指定匹配的文件类型
--exinclude 过滤掉不需要匹配的文件类型
-A: 显示匹配行及后面多少行, 如: -A3, 则表示显示匹配行及后3行
-B: 显示匹配行及前面多少行, 如: -B3, 则表示显示匹配行及前3行
-C: 显示匹配行前后多少行, 如: -C3, 则表示显示批量行前后3行
^ #行的开始 如:‘^grep‘匹配所有以grep开头的行。
$ #行的结束 如:‘grep$‘匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:‘gr.p‘匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:‘*grep‘匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
‘\?‘:匹配其前面的字符0次或者1次;
‘\+’:匹配其前面的字符1次或者多次;
[] #匹配一个指定范围内的字符,如‘[Gg]rep‘匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:‘[^A-FH-Z]rep‘匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如‘\(love\)‘,love被标记为1。
\< #锚定单词的开始,如:‘\<grep‘匹配包含以grep开头的单词的行。
\> #锚定单词的结束,如‘grep\>‘匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:‘0\{5\}‘匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:‘o\{5,\}‘匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:‘o\{5,10\}‘匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:‘G\w*p‘匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: ‘\bgrep\b‘只匹配grep。
1)查询当前系统中不允许登录的用户信息
[root@VM_0_10_centos shellScript]# grep /sbin/nologin /tmp/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
或
[root@VM_0_10_centos shellScript]# cat /tmp/passwd | grep /sbin/nologin
2)多文件查询
# 查看多个文件匹配包含字母a的行
[root@VM_0_10_centos shellScript]# grep a test.sh test.txt
test.sh:#!/bin/bash
test.sh:echo "argument: $0";
test.txt:2 this is a test

3)查看既包含a又包含o的行
[root@VM_0_10_centos shellScript]# grep a test.txt | grep o
或
[root@VM_0_10_centos shellScript]# cat test.txt | grep a | grep o
3 Are you like awk
10 There are orange,apple,mongo

4)查找匹配a或者匹配o的行
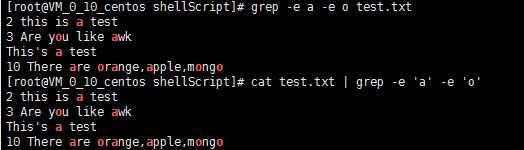
[root@VM_0_10_centos shellScript]# grep -e a -e o test.txt
或
[root@VM_0_10_centos shellScript]# cat test.txt | grep -e ‘a‘ -e ‘o‘
2 this is a test
3 Are you like awk
This‘s a test
10 There are orange,apple,mongo
5)匹配查询内容的前n行,后n行,前后n行
#显示匹配行前2行
grep a test.txt -A2
#显示匹配行后2行
grep a test.txt -B2
#显示匹配行前后2行
grep a test.txt -C2
PS:尝试,但是结果还是显示的全部,不知道是我命令错了还是其他原因
6)匹配字符不区分大小写
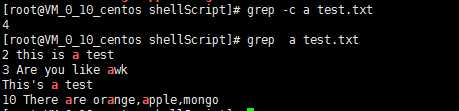
[root@VM_0_10_centos shellScript]# grep -i a test.txt
2 this is a test
3 Are you like awk
This‘s a test
10 There are orange,apple,mongo

7)匹配正则表达式(匹配小写a-z之间的5个字符,即包含5个小写字母的字符)下面加粗部分显示
[root@VM_0_10_centos shellScript]# grep -e ‘[a-z]\{5\}‘ test.txt
10 There are orange,apple,mongo

8)统计包含a的行数
[root@VM_0_10_centos shellScript]# grep -c a test.txt
4
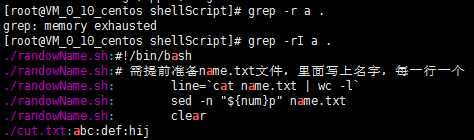
9)遍历当前目录及子目录包含a的行
[root@VM_0_10_centos shellScript]# grep -r a . grep: memory exhausted [root@VM_0_10_centos shellScript]# grep -rI a . ./randowName.sh: clear ./cut.txt:abc:def:hij
PS:这里不加-I会出现上面内存问题,这是因为grep -r查找的范围会访问所有这个目录下的文件,包括二进制文件,加上-I参数不匹配查询二进制文件,可以解决这个问题。
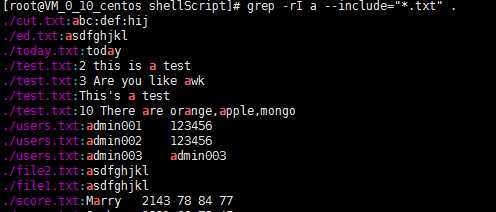
10)遍历当前目录及所有子目录,查找所有.txt类型的文件中包含a的字符
[root@VM_0_10_centos shellScript]# grep -rI a --include="*.txt" .
./cut.txt:abc:def:hij
./ed.txt:asdfghjkl
11)查找指定进程及其个数

PS:如果想值查询tomcat进程,使用grep -v "grep"筛选即可( ps -ef | grep -v "grep" |grep "tomcat")
12)查找包含非“a”开头的行
[root@VM_0_10_centos shellScript]# grep ^[a] test.txt
[root@VM_0_10_centos shellScript]# grep ^[^a] test.txt
2 this is a test
3 Are you like awk
This‘s a test
10 There are orange,apple,mongo
PS:grep可用于shell中。grep通过返回一个状态值来说明搜索的状态,结果{0:成功,1:不成功,2:搜索的文件不存在}
取出ip地址可以查看我另一篇博客:https://www.cnblogs.com/HeiDi-BoKe/p/11757961.html
标签:返回 查看 有一个 系统 忽略 常用选项 style rand 说明
原文地址:https://www.cnblogs.com/HeiDi-BoKe/p/11791905.html