标签:解释器 算法 对象关联 遍历 jpg tps 引入 log 延迟
之前已经讲过垃圾回收机制了,就是引用计数为 0 的时候,解释器就会回收这个变量值,但是引用计数机制还存在着一个致命的弱点,就是循环引用,也叫作交叉引用。
# 如下我们定义了两个列表,简称列表1与列表2,变量名l1指向列表1,变量名l2指向列表2
>>> l1=['xxx'] # 列表1被引用一次,列表1的引用计数变为1
>>> l2=['yyy'] # 列表2被引用一次,列表2的引用计数变为1
>>> l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2
>>> l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2
# l1与l2之间有相互引用
# l1 = ['xxx'的内存地址,列表2的内存地址]
# l2 = ['yyy'的内存地址,列表1的内存地址]
>>> l1
['xxx', ['yyy', [...]]]
>>> l2
['yyy', ['xxx', [...]]]
>>> l1[1][1][0]
'xxx'
循环引用会导致:值不再被任何名字关联,但是值的引用计数并不会为0,应该被回收但不
能被回收,什么意思呢?试想一下,请看如下操作
>>> del l1 # 列表1的引用计数减1,列表1的引用计数变为1
>>> del l2 # 列表2的引用计数减1,列表2的引用计数变为1此时,只剩下列表1与列表2之间的相互引用,两个列表的引用计数均不为0,但两个列表不
再被任何其他对象关联,没有任何人可以再引用到它们,所以它俩占用内存空间应该被回
收,但由于相互引用的存在,每一个对象的引用计数都不为0,因此这些对象所占用的内存
永远不会被释放,所以循环引用是致命的,这与手动进行内存管理所产生的内存泄露毫无区
别。
所以Python引入了“标记-清除” 与“分代回收”来分别解决引用计数的循环引用与效率低的问题
容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都
可能产生循环引用。而“标记-清除”计数就是为了解决循环引用的问题。
在了解标记清除算法前,我们需要明确一点,关于变量的存储,内存中有两块区域:堆区与
栈区,在定义变量时,变量名与值内存地址的关联关系存放于栈区,变量值存放于堆区,内
存管理回收的则是堆区的内容,详解如下图
定义了两个变量x = 10、y = 20
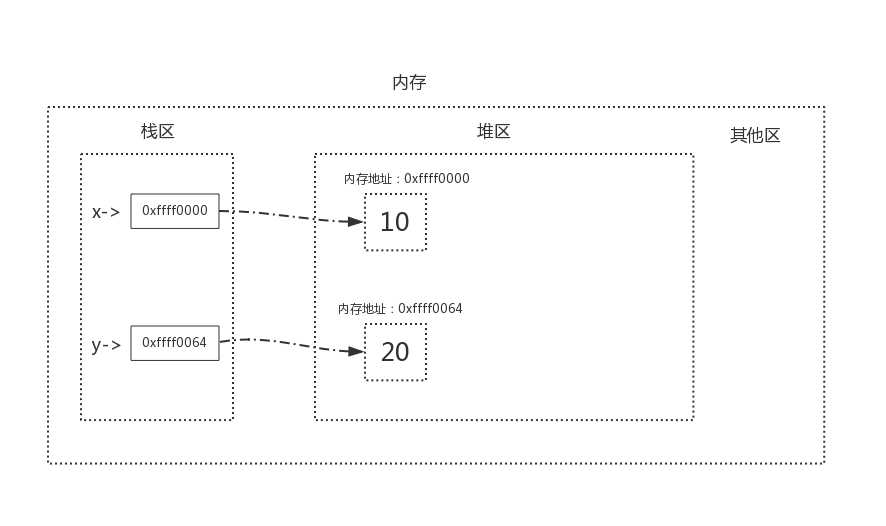
当我们执行x=y时,内存中的栈区与堆区变化如下
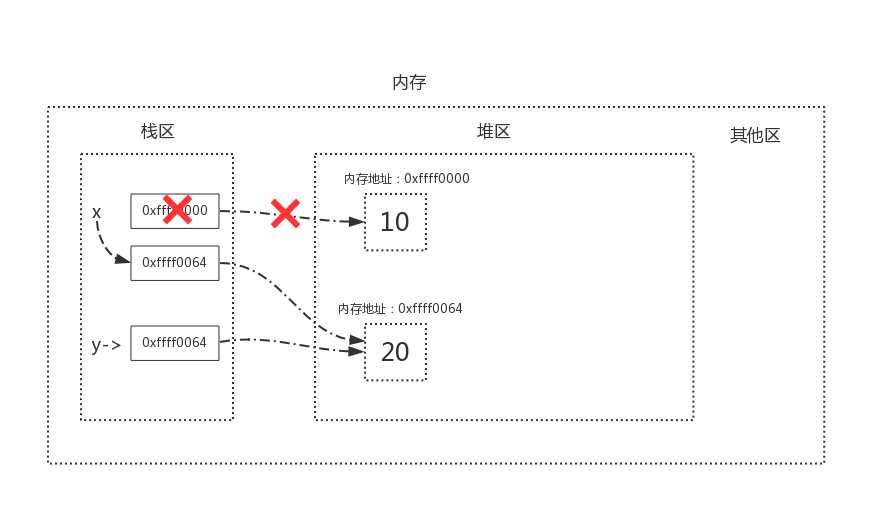
标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后
进行两项工作,第一项则是标记,第二项则是清除
#1、标记
标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所
有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。
#2、清除
清除的过程将遍历堆中所有的对象,将没有标记的对象全部清除掉。
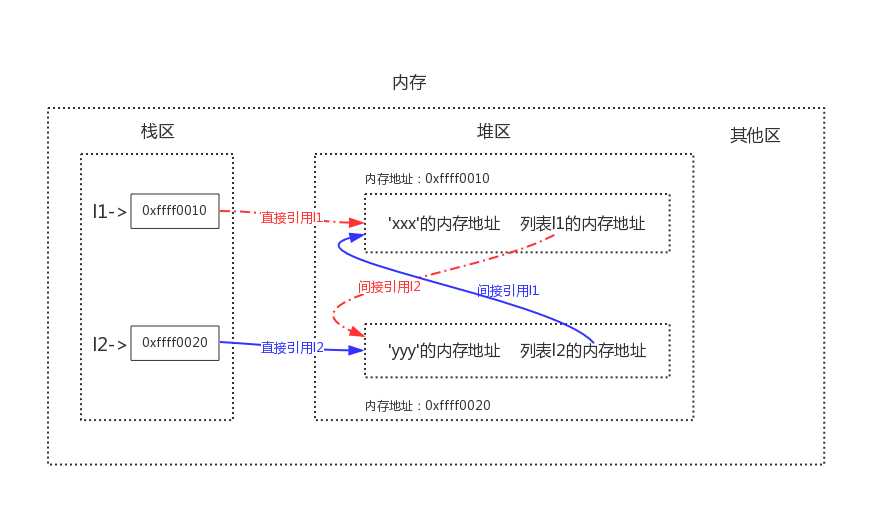
直接引用指的是从栈区出发直接引用到的内存地址,间接引用指的是从栈区出发引用到堆区
后再进一步引用到的内存地址,以我们之前的两个列表l1与l2为例画出如下图像
当我们同时删除l1与l2时,会清理掉栈区中l1与l2的内容
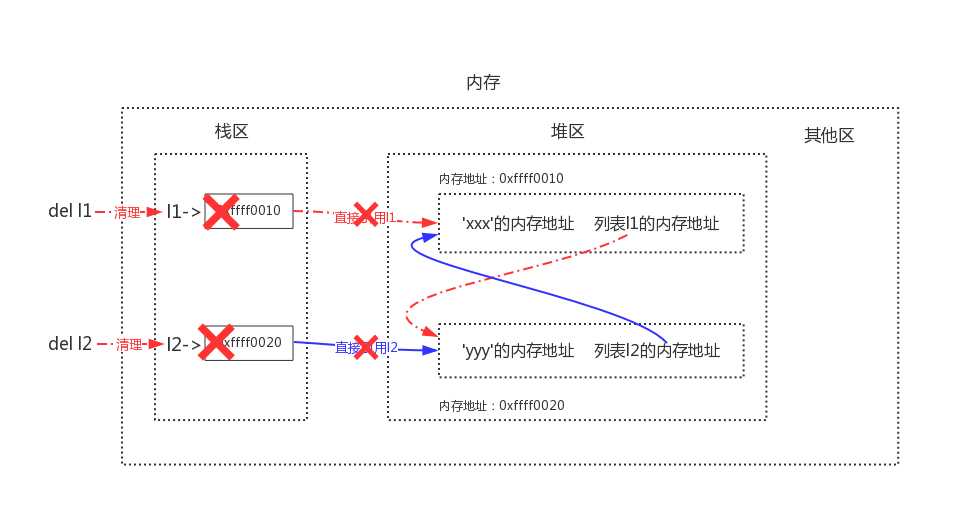
这样在启用标记清除算法时,发现栈区内不再有l1与l2(只剩下堆区内二者的相互引用),
于是列表1与列表2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内
存泄漏问题。
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是
非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时
间”的策略。
分代:
分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认
为,该变量是常用变量,gc对其扫描的频率会降低,具体实现原理如下:
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低
回收:
回收依然是使用引用计数作为回收的依据
虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新
生代,所以该变量的回收就会被延迟。出 处:https://www.cnblogs.com/xiaoyuanqujing
其它博文:https://www.cnblogs.com/xiaoyuanqujing
标签:解释器 算法 对象关联 遍历 jpg tps 引入 log 延迟
原文地址:https://www.cnblogs.com/chanyuli/p/11795665.html