标签:window 开会 ken 错误 name from 命令解析 dem 执行命令
tessract的训练有个工具叫 jTessBoxEditor
1、jTessBoxEditor是用java写的,首先要装java的环境
jdk-8u191-windows-x64.exe 这个我想从官网下载来的,但是一直失败,直接从搞java的同事那里要来的。
装完以后要配置一些环境变量:
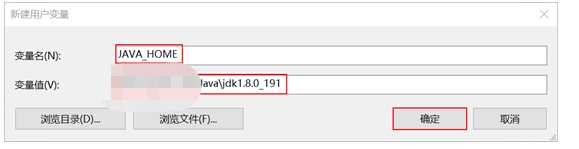
系统环境变量 --》 path ---》新建
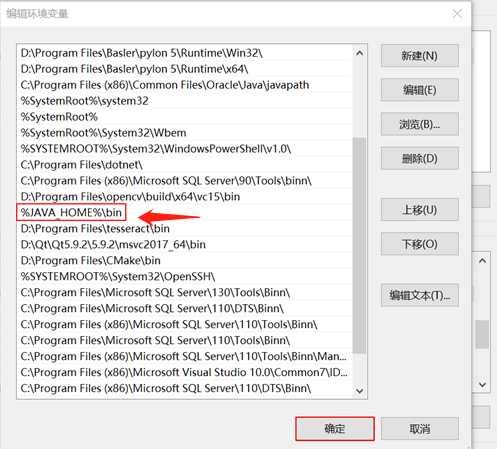
然后重启电脑。。。
2、安装jTessBoxEditor:
下载地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
3、启动jTessBoxEditor:
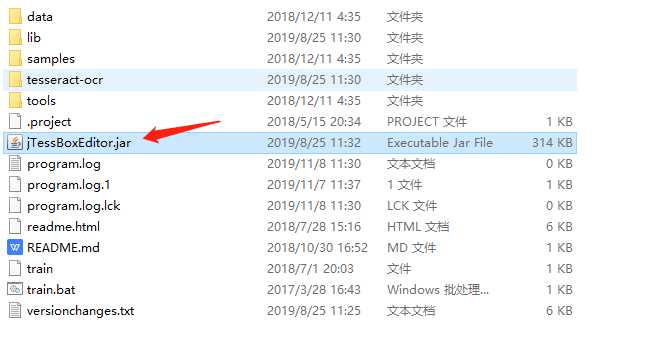
双击显示:
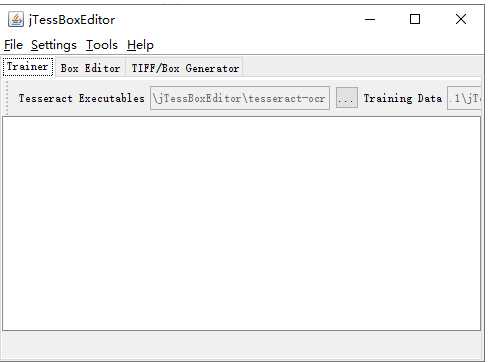
然后进入tools 点击merge tif
如果你加入的模型是tif的格式,直接找到那个tif即可。
如果你加入的图片格式是png的,
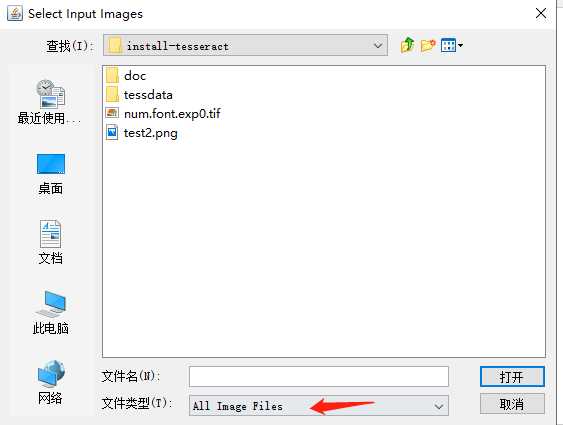
修改加入的文件格式,点击打开会显示保存的界面,将文件保存为:num.font.exp0.tif 其中,num是你自己定义的,图片要保存到tesseract的目录下。
cmd进入tesseract目录,执行命令 tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
命令解析,
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
然后: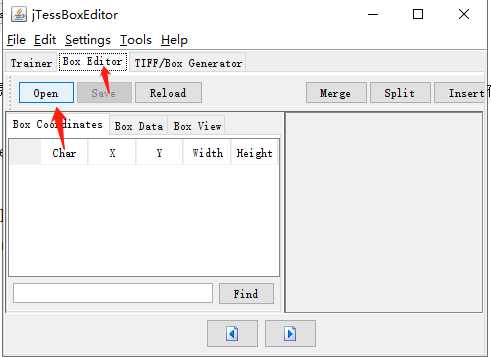
点击open打开上面保存的num.font.exp0.tif文件
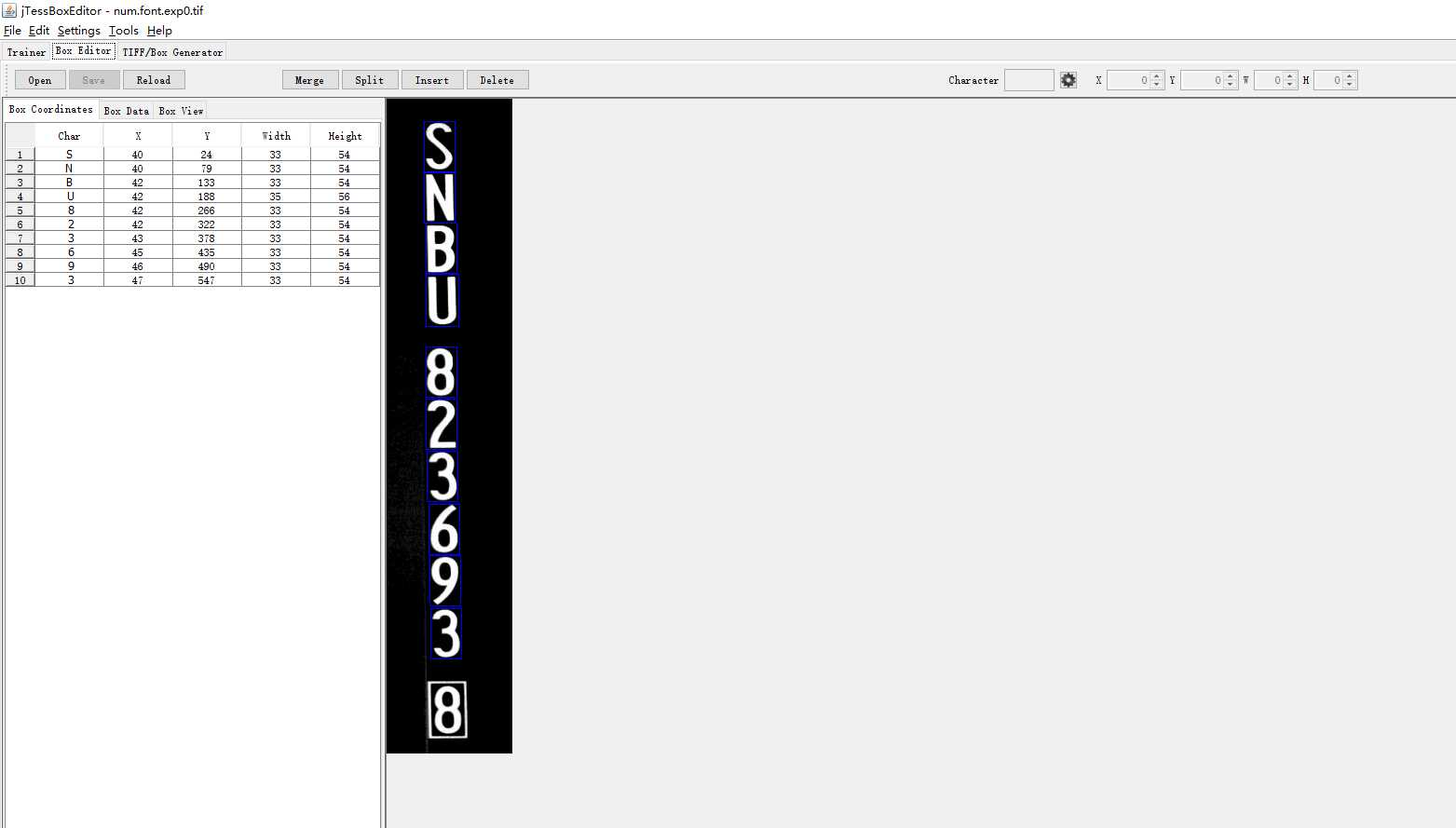
这我的demo的一张图。
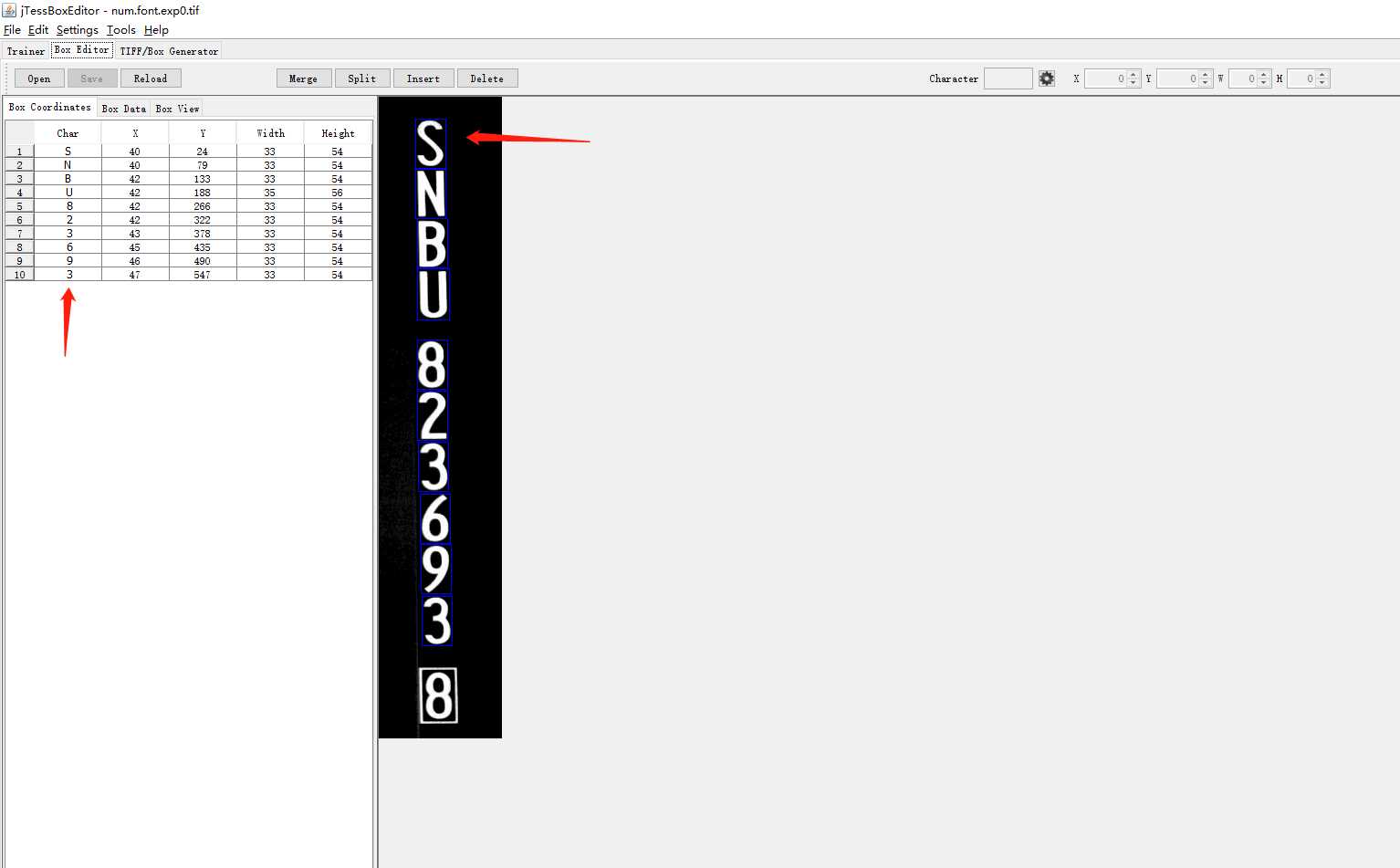
每一个char都要和左边的图相对应。如果不对应就一一修改,建议大家把这上面的所有的操作按钮都熟悉下再使用,其实很简单。
修改完以后点击save保存。
定义字体特征文件。创建一个名称为font_properties的字体特征文件。font_properties不含有BOM头,文件内容格式如下:
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中fontname为字体名称,必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件,用记事本打开,输入以下下内容:
font 0 0 0 0 0
这里全取值为0,表示字体不是粗体、斜体等等。
简单的说就是在tesseract的目录下新建一个font_properties,txt,然后写内容: font 0 0 0 0 0
将下面命令保存成一个批处理的bat文件,放在tesseract的目录下,双击执行。
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties.txt -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
pause
命令窗口会有一些错误,请看错误的解决办法:
传送门:https://www.cnblogs.com/132818Creator/p/11811841.html
something from:https://blog.csdn.net/sylsjane/article/details/83751297
标签:window 开会 ken 错误 name from 命令解析 dem 执行命令
原文地址:https://www.cnblogs.com/132818Creator/p/11819174.html