标签:python 字符串 lock 基本操作 text parse 去除 文件中 注释
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库.
1.prettify()方法:将Beautiful Soup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行。
from bs4 import BeautifulSoup from urllib.request import urlopen f = urlopen(‘https://tieba.baidu.com/index.html‘).read() soup = BeautifulSoup(f,‘html.parser‘) s = soup.prettify() print(s)
输出结果:

2.基本操作
s = BeautifulSoup(‘<p class="123">喜欢捕捉美的瞬间</p>‘,‘html.parser‘) print(s.p) #文档中的tag print(s.p.name) #tag的名字 ‘‘‘ 如果这个标签只有一个 NavigableString类型的子节点,可以使用string来获取tag中的子节点字符串。 如果文档下的标签包含多个字符串,可以使用strings循环获得。 输出的字符串中可能包含了很多空格或空行,使用stripped_strings可以去除多余空白。 ‘‘‘ print(s.p.string) print(s.p.attrs) #tag的属性操作方法与字典一样,.attrs可以拿到属性和属性值 print(s.p[‘class‘]) #根据属性查属性值 print(s.get_text()) # print(s.p.string.replace_with(‘哩哩啦啦‘)) #tag中包含的字符串不能编辑,但是可以被替换成其它的字符串
结果:
<p class="123">喜欢捕捉美的瞬间</p>
p
喜欢捕捉美的瞬间
{‘class‘: [‘123‘]}
[‘123‘]
喜欢捕捉美的瞬间
喜欢捕捉美的瞬间
3.CDATA替代注释
from bs4 import CData markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>" soup = BeautifulSoup(markup,‘html.parser‘) comment = soup.b.string cdata = CData("A CDATA block") comment.replace_with(cdata) print(soup.b.prettify())
输出: <b><![CDATA[A CDATA block]]></b>
4.contents属性可以将tag的子节点以列表的方式输出.
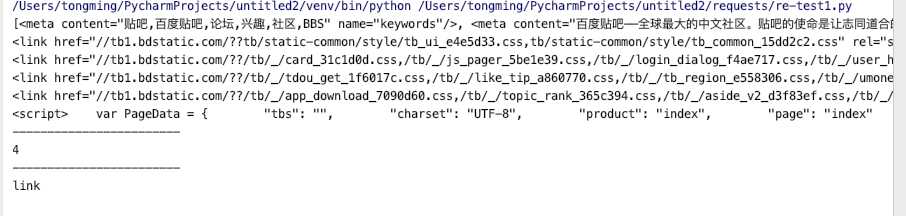
f = urlopen(‘https://tieba.baidu.com/index.html‘).read() soup = BeautifulSoup(f,‘html.parser‘) #s = soup.prettify() #print(s) tag = soup.head print(tag.contents) print(‘------------------------‘) print(len(tag)) #列表展示,可以用len()拿到子节点的个数 print(‘------------------------‘) l = tag.contents[3].contents[1].contents[4] #也可根据索引来查找子节点 print(l.name)
结果:
5.children生成器可以用来遍历子节点:(descendants可以遍历子孙节点)
a = soup.head.contents[3].contents[1] for child in a.children: print(child)
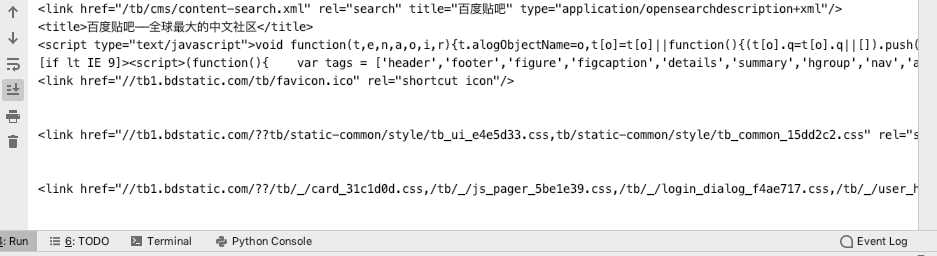
标签:python 字符串 lock 基本操作 text parse 去除 文件中 注释
原文地址:https://www.cnblogs.com/suancaipaofan/p/11826610.html