标签:from min 归一化 使用 nsf 之间 scale 处理 cal


from sklearn.preprocessing import MinMaxScaler, StandardScaler
def mm():
"""
归一化预处理
:return:None
"""
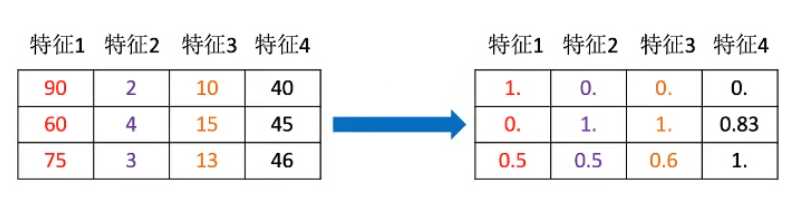
mm = MinMaxScaler()
data = mm.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]])
print(data)
def stand():
"""
标准化预处理
:return: None
"""
st = StandardScaler()
data = st.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]])
print(data)
if __name__ == '__main__':
mm()
print('*' * 50)
stand()import numpy as np
from sklearn.preprocessing import Imputer
def im():
"""
缺失值处理
:return: None
"""
# NaN, nan都可以
im = Imputer(missing_values='NaN', strategy='mean', axis=0) # axis=0 列,可以记忆0是竖着圈
data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6]])
print(data)
return None
if __name__ == '__main__':
im()标签:from min 归一化 使用 nsf 之间 scale 处理 cal
原文地址:https://www.cnblogs.com/hp-lake/p/11827623.html