标签:集成学习 class model 学习 rest 不同 logistic 建立 anti
从百度云课堂上截图的基础概念,如果之前不了解的可以先看一下这篇博客:https://blog.csdn.net/weixin_30708329/article/details/97262409


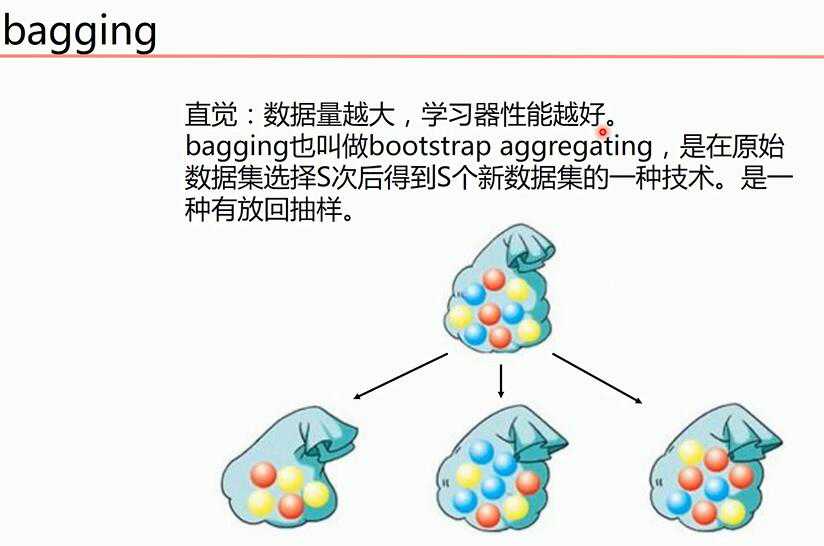

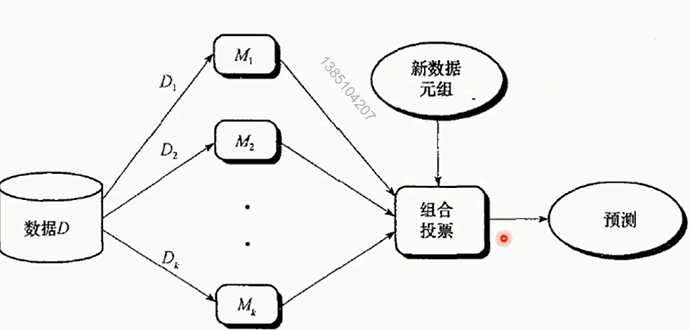
不同的数据集训练不同的模型,根据模型进行投票得到最终预测结果
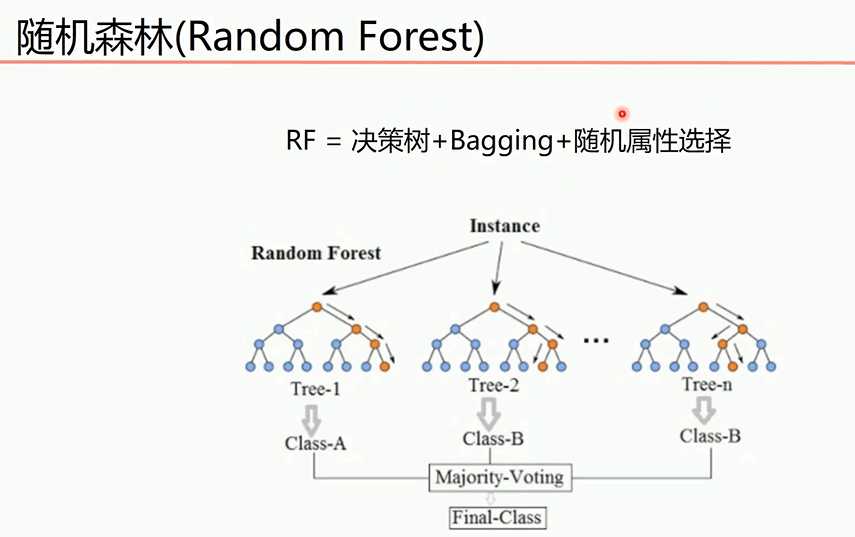
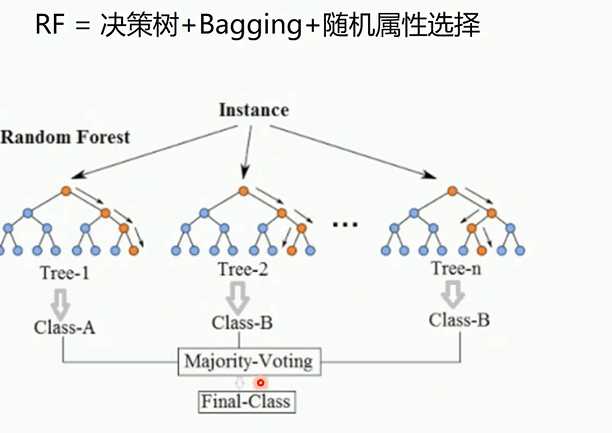
多棵决策树组成森林,每个模型训练集不同和选择的决策属性不同是RF算法随机的最主要体现

adaboost算法不同模型之间会有影响







多层分类器进行结果的预测
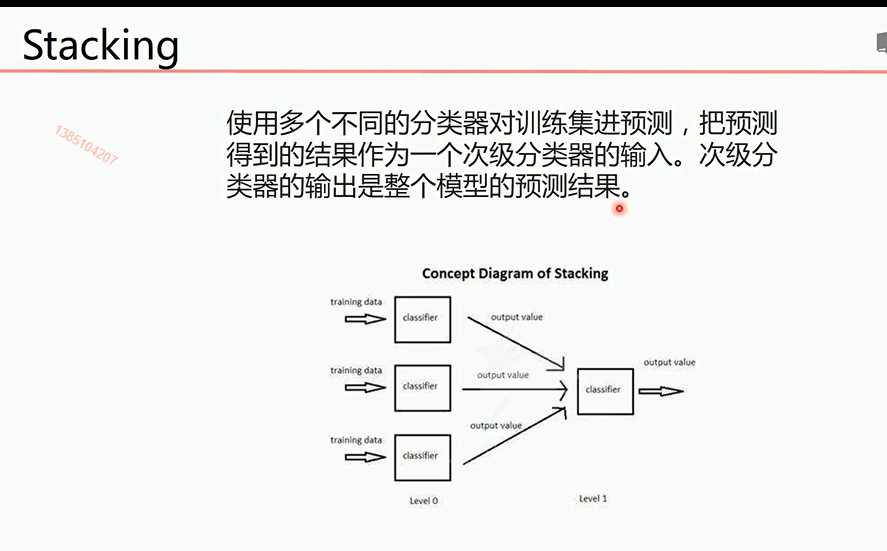
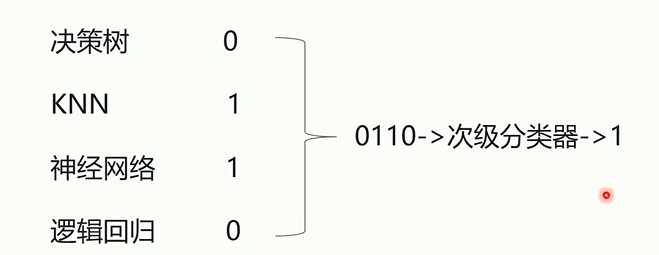

bagging算法提高KNN和决策树算法精确度
1 # 导入算法包以及数据集 2 from sklearn import neighbors 3 from sklearn import datasets 4 from sklearn.ensemble import BaggingClassifier 5 from sklearn import tree 6 from sklearn.model_selection import train_test_split 7 import numpy as np 8 import matplotlib.pyplot as plt 9 iris = datasets.load_iris() 10 x_data = iris.data[:,:2] 11 y_data = iris.target 12 def plot(model): 13 # 获取数据值所在的范围 14 x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1 15 y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1 16 17 # 生成网格矩阵 18 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), 19 np.arange(y_min, y_max, 0.02)) 20 21 z = model.predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据 22 z = z.reshape(xx.shape) 23 # 等高线图 24 cs = plt.contourf(xx, yy, z) 25 x_train,x_test,y_train,y_test = train_test_split(x_data, y_data) 26 knn = neighbors.KNeighborsClassifier() 27 knn.fit(x_train, y_train) 28 # 画图 29 plot(knn) 30 # 样本散点图 31 plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data) 32 plt.show() 33 # 准确率 34 print("knn:",knn.score(x_test, y_test)) 35 dtree = tree.DecisionTreeClassifier() 36 dtree.fit(x_train, y_train) 37 # 画图 38 plot(dtree) 39 # 样本散点图 40 plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data) 41 plt.show() 42 # 准确率 43 print("dtree:",dtree.score(x_test, y_test)) 44 bagging_knn = BaggingClassifier(knn, n_estimators=100)#使用bagging算法训练100组knn分类器 45 # 输入数据建立模型 46 bagging_knn.fit(x_train, y_train) 47 plot(bagging_knn) 48 # 样本散点图 49 plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data) 50 plt.show() 51 print("bagging:",bagging_knn.score(x_test, y_test)) 52 bagging_tree = BaggingClassifier(dtree, n_estimators=100)#使用bagging算法训练100组决策树分类器 53 # 输入数据建立模型 54 bagging_tree.fit(x_train, y_train) 55 plot(bagging_tree) 56 # 样本散点图 57 plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data) 58 plt.show() 59 print("bagging_tree",bagging_tree.score(x_test, y_test))
随机森林对决策树模型优化
1 from sklearn import tree 2 from sklearn.model_selection import train_test_split 3 from sklearn.ensemble import RandomForestClassifier 4 import numpy as np 5 import matplotlib.pyplot as plt 6 # 载入数据 7 data = np.genfromtxt("LR-testSet2.txt", delimiter=",") 8 x_data = data[:,:-1] 9 y_data = data[:,-1] 10 11 plt.scatter(x_data[:,0],x_data[:,1],c=y_data) 12 plt.show() 13 x_train,x_test,y_train,y_test = train_test_split(x_data, y_data, test_size = 0.5) 14 def plot(model): 15 # 获取数据值所在的范围 16 x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1 17 y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1 18 19 # 生成网格矩阵 20 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), 21 np.arange(y_min, y_max, 0.02)) 22 23 z = model.predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据 24 z = z.reshape(xx.shape) 25 # 等高线图 26 cs = plt.contourf(xx, yy, z) 27 # 样本散点图 28 plt.scatter(x_test[:, 0], x_test[:, 1], c=y_test) 29 plt.show() 30 dtree = tree.DecisionTreeClassifier() 31 dtree.fit(x_train, y_train) 32 plot(dtree) 33 print("dtree",dtree.score(x_test, y_test)) 34 RF = RandomForestClassifier(n_estimators=50) 35 RF.fit(x_train, y_train) 36 plot(RF) 37 print("RandomForest",RF.score(x_test, y_test))
下面是用到的数据

1 0.051267,0.69956,1 2 -0.092742,0.68494,1 3 -0.21371,0.69225,1 4 -0.375,0.50219,1 5 -0.51325,0.46564,1 6 -0.52477,0.2098,1 7 -0.39804,0.034357,1 8 -0.30588,-0.19225,1 9 0.016705,-0.40424,1 10 0.13191,-0.51389,1 11 0.38537,-0.56506,1 12 0.52938,-0.5212,1 13 0.63882,-0.24342,1 14 0.73675,-0.18494,1 15 0.54666,0.48757,1 16 0.322,0.5826,1 17 0.16647,0.53874,1 18 -0.046659,0.81652,1 19 -0.17339,0.69956,1 20 -0.47869,0.63377,1 21 -0.60541,0.59722,1 22 -0.62846,0.33406,1 23 -0.59389,0.005117,1 24 -0.42108,-0.27266,1 25 -0.11578,-0.39693,1 26 0.20104,-0.60161,1 27 0.46601,-0.53582,1 28 0.67339,-0.53582,1 29 -0.13882,0.54605,1 30 -0.29435,0.77997,1 31 -0.26555,0.96272,1 32 -0.16187,0.8019,1 33 -0.17339,0.64839,1 34 -0.28283,0.47295,1 35 -0.36348,0.31213,1 36 -0.30012,0.027047,1 37 -0.23675,-0.21418,1 38 -0.06394,-0.18494,1 39 0.062788,-0.16301,1 40 0.22984,-0.41155,1 41 0.2932,-0.2288,1 42 0.48329,-0.18494,1 43 0.64459,-0.14108,1 44 0.46025,0.012427,1 45 0.6273,0.15863,1 46 0.57546,0.26827,1 47 0.72523,0.44371,1 48 0.22408,0.52412,1 49 0.44297,0.67032,1 50 0.322,0.69225,1 51 0.13767,0.57529,1 52 -0.0063364,0.39985,1 53 -0.092742,0.55336,1 54 -0.20795,0.35599,1 55 -0.20795,0.17325,1 56 -0.43836,0.21711,1 57 -0.21947,-0.016813,1 58 -0.13882,-0.27266,1 59 0.18376,0.93348,0 60 0.22408,0.77997,0 61 0.29896,0.61915,0 62 0.50634,0.75804,0 63 0.61578,0.7288,0 64 0.60426,0.59722,0 65 0.76555,0.50219,0 66 0.92684,0.3633,0 67 0.82316,0.27558,0 68 0.96141,0.085526,0 69 0.93836,0.012427,0 70 0.86348,-0.082602,0 71 0.89804,-0.20687,0 72 0.85196,-0.36769,0 73 0.82892,-0.5212,0 74 0.79435,-0.55775,0 75 0.59274,-0.7405,0 76 0.51786,-0.5943,0 77 0.46601,-0.41886,0 78 0.35081,-0.57968,0 79 0.28744,-0.76974,0 80 0.085829,-0.75512,0 81 0.14919,-0.57968,0 82 -0.13306,-0.4481,0 83 -0.40956,-0.41155,0 84 -0.39228,-0.25804,0 85 -0.74366,-0.25804,0 86 -0.69758,0.041667,0 87 -0.75518,0.2902,0 88 -0.69758,0.68494,0 89 -0.4038,0.70687,0 90 -0.38076,0.91886,0 91 -0.50749,0.90424,0 92 -0.54781,0.70687,0 93 0.10311,0.77997,0 94 0.057028,0.91886,0 95 -0.10426,0.99196,0 96 -0.081221,1.1089,0 97 0.28744,1.087,0 98 0.39689,0.82383,0 99 0.63882,0.88962,0 100 0.82316,0.66301,0 101 0.67339,0.64108,0 102 1.0709,0.10015,0 103 -0.046659,-0.57968,0 104 -0.23675,-0.63816,0 105 -0.15035,-0.36769,0 106 -0.49021,-0.3019,0 107 -0.46717,-0.13377,0 108 -0.28859,-0.060673,0 109 -0.61118,-0.067982,0 110 -0.66302,-0.21418,0 111 -0.59965,-0.41886,0 112 -0.72638,-0.082602,0 113 -0.83007,0.31213,0 114 -0.72062,0.53874,0 115 -0.59389,0.49488,0 116 -0.48445,0.99927,0 117 -0.0063364,0.99927,0 118 0.63265,-0.030612,0
adaboost决策树
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn import tree 4 from sklearn.ensemble import AdaBoostClassifier 5 from sklearn.tree import DecisionTreeClassifier 6 from sklearn.datasets import make_gaussian_quantiles 7 from sklearn.metrics import classification_report 8 # 生成2维正态分布,生成的数据按分位数分为两类,500个样本,2个样本特征 9 x1, y1 = make_gaussian_quantiles(n_samples=500, n_features=2,n_classes=2)#默认mean=(0, 0) 10 # 生成2维正态分布,生成的数据按分位数分为两类,400个样本,2个样本特征均值都为3 11 x2, y2 = make_gaussian_quantiles(mean=(3, 3), n_samples=500, n_features=2, n_classes=2) 12 # 将两组数据合成一组数据 13 x_data = np.concatenate((x1, x2)) 14 y_data = np.concatenate((y1, - y2 + 1)) 15 plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data) 16 plt.show() 17 # 决策树模型 18 model = tree.DecisionTreeClassifier(max_depth=3) 19 20 # 输入数据建立模型 21 model.fit(x_data, y_data) 22 23 # 获取数据值所在的范围 24 x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1 25 y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1 26 27 # 生成网格矩阵 28 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), 29 np.arange(y_min, y_max, 0.02)) 30 31 z = model.predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据 32 z = z.reshape(xx.shape) 33 # 等高线图 34 cs = plt.contourf(xx, yy, z) 35 # 样本散点图 36 plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data) 37 plt.show() 38 # 模型准确率 39 print("决策树:",model.score(x_data,y_data)) 40 # AdaBoost模型 41 model = AdaBoostClassifier(DecisionTreeClassifier(max_depth=3),n_estimators=10)#决策树深度为3,一共训练十个模型 42 # 训练模型 43 model.fit(x_data, y_data) 44 45 # 获取数据值所在的范围 46 x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1 47 y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1 48 49 # 生成网格矩阵 50 xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), 51 np.arange(y_min, y_max, 0.02)) 52 53 # 获取预测值 54 z = model.predict(np.c_[xx.ravel(), yy.ravel()]) 55 z = z.reshape(xx.shape) 56 # 等高线图 57 cs = plt.contourf(xx, yy, z) 58 # 样本散点图 59 plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data) 60 plt.show() 61 # 模型准确率 62 print("adaboost:",model.score(x_data,y_data))#得分很高
stacking分类器算法
1 from sklearn import datasets 2 from sklearn import model_selection 3 from sklearn.linear_model import LogisticRegression 4 from sklearn.neighbors import KNeighborsClassifier 5 from sklearn.tree import DecisionTreeClassifier 6 from mlxtend.classifier import StackingClassifier # pip install mlxtend 7 import numpy as np 8 9 # 载入数据集 10 iris = datasets.load_iris() 11 # 只要第1,2列的特征 12 x_data, y_data = iris.data[:, 1:3], iris.target 13 14 # 定义三个不同的分类器 15 clf1 = KNeighborsClassifier(n_neighbors=1) 16 clf2 = DecisionTreeClassifier() 17 clf3 = LogisticRegression() 18 19 # 定义一个次级分类器 20 lr = LogisticRegression() 21 sclf = StackingClassifier(classifiers=[clf1, clf2, clf3], 22 meta_classifier=lr) 23 24 for clf, label in zip([clf1, clf2, clf3, sclf], 25 [‘KNN‘, ‘Decision Tree‘, ‘LogisticRegression‘, ‘StackingClassifier‘]): 26 scores = model_selection.cross_val_score(clf, x_data, y_data, cv=3, scoring=‘accuracy‘) 27 print("Accuracy: %0.2f [%s]" % (scores.mean(), label))
voting分类器
1 from sklearn import datasets 2 from sklearn import model_selection 3 from sklearn.linear_model import LogisticRegression 4 from sklearn.neighbors import KNeighborsClassifier 5 from sklearn.tree import DecisionTreeClassifier 6 from sklearn.ensemble import VotingClassifier 7 import numpy as np 8 9 # 载入数据集 10 iris = datasets.load_iris() 11 # 只要第1,2列的特征 12 x_data, y_data = iris.data[:, 1:3], iris.target 13 14 # 定义三个不同的分类器 15 clf1 = KNeighborsClassifier(n_neighbors=1) 16 clf2 = DecisionTreeClassifier() 17 clf3 = LogisticRegression() 18 19 sclf = VotingClassifier([(‘knn‘, clf1), (‘dtree‘, clf2), (‘lr‘, clf3)]) 20 21 for clf, label in zip([clf1, clf2, clf3, sclf], 22 [‘KNN‘, ‘Decision Tree‘, ‘LogisticRegression‘, ‘VotingClassifier‘]): 23 scores = model_selection.cross_val_score(clf, x_data, y_data, cv=3, scoring=‘accuracy‘) 24 print("Accuracy: %0.2f [%s]" % (scores.mean(), label))
标签:集成学习 class model 学习 rest 不同 logistic 建立 anti
原文地址:https://www.cnblogs.com/henuliulei/p/11831153.html
