标签:展现 相互 输出 相对 exp round 丢失 不同的 span
一:激活函数作用:
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
二:激活函数所具有的几个性质:
非线性: 当激活函数是线性的时候,一个两层的神经网络就可以逼近基本上所有的函数了。但是,如果激活函数是恒等激活函数的时候(即f(x)=x),就不满足这个性质了,而且如果MLP(Multi-Layer Perceptron,即多层感知器)使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的。
可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
f(x)≈x: 当激活函数满足这个性质的时候,如果参数的初始化是random的很小的值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要很用心的去设置初始值。
输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate。
3.1:Sigmoid
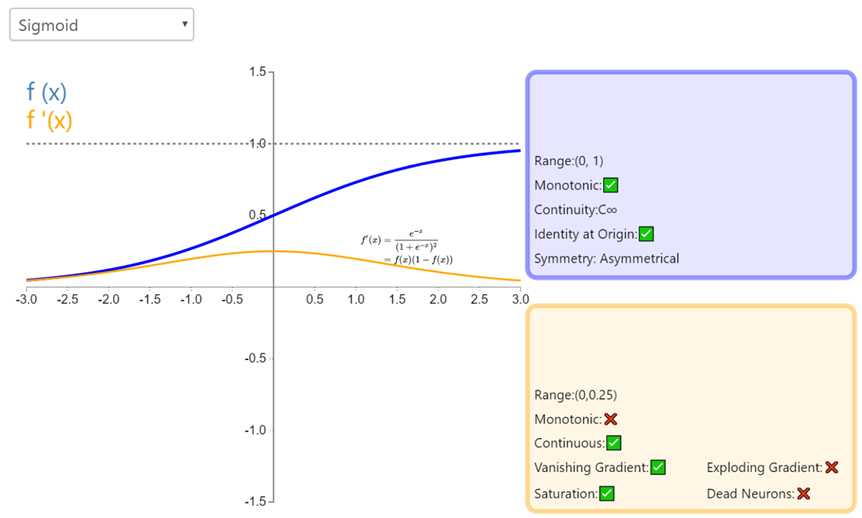
Sigmoid 因其在 logistic 回归中的重要地位而被人熟知,值域在 0 到 1 之间。Logistic Sigmoid(或者按通常的叫法,Sigmoid)激活函数给神经网络引进了概率的概念。它的导数是非零的,并且很容易计算(是其初始输出的函数)。然而,在分类任务中,sigmoid 正逐渐被 Tanh 函数取代作为标准的激活函数,因为后者为奇函数(关于原点对称)。
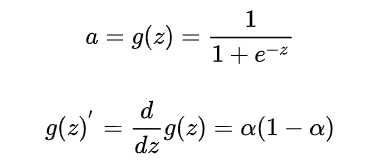
优点:
Sigmoid函数的输出映射在(0,1)之间,单调连续,输出范围有限,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。优化稳定,可以用作输出层。求导容易。sigmoid 函数曾经被使用的很多,不过近年来,用它的人越来越少了。
缺点:
Sigmoids saturate and kill gradients:当输入非常大或者非常小的时候(saturation),这些神经元的梯度是接近于0的,从图中可以看出梯度的趋势。所以,你需要尤其注意参数的初始值来尽量避免saturation的情况。如果你的初始值很大的话,大部分神经元可能都会处在saturation的状态而把gradient kill掉,这会导致网络变的很难学习。
Sigmoid 的 output 不是0均值. 这是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。 产生的一个结果就是:如果数据进入神经元的时候是正的(e.g. x>0x>0 elementwise in f=wTx+bf=wTx+b),那么 ww计算出的梯度也会始终都是正的。 当然了,如果你是按batch去训练,那么那个batch可能得到不同的信号,所以这个问题还是可以缓解一下的。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。
3.2:双曲正切函数(Tanh)
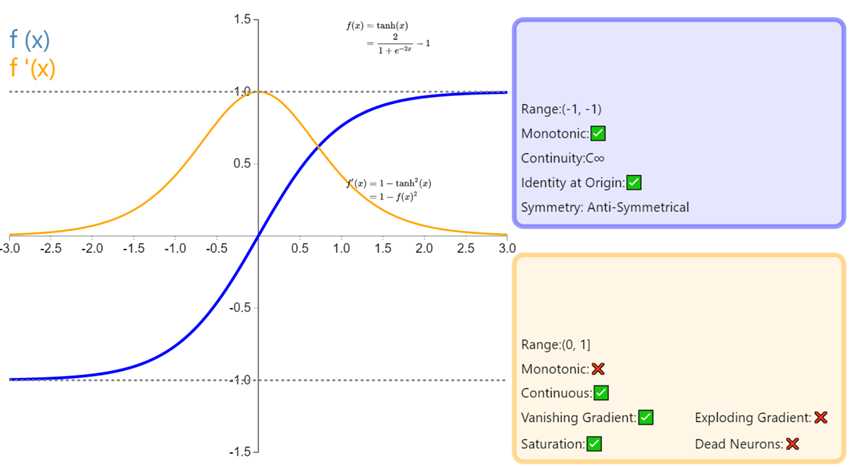
在分类任务中,双曲正切函数(Tanh)逐渐取代 Sigmoid 函数作为标准的激活函数,其具有很多神经网络所钟爱的特征。它是完全可微分的,反对称,对称中心在原点。为了解决学习缓慢和/或梯度消失问题,可以使用这个函数的更加平缓的变体(log-log、softsign、symmetrical sigmoid 等等)。
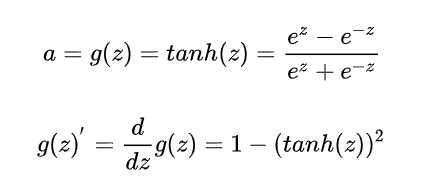
优点:
比Sigmoid函数收敛速度更快。
相比Sigmoid函数,其输出以0为中心。
缺点:
还是没有改变Sigmoid函数的最大问题——由于饱和性产生的梯度消失。
3.3:修正线性单元(Rectified linear unit,ReLU)
是神经网络中最常用的激活函数。它保留了 step 函数的生物学启发(只有输入超出阈值时神经元才激活),不过当输入为正的时候,导数不为零,从而允许基于梯度的学习(尽管在 x=0 的时候,导数是未定义的)。使用这个函数能使计算变得很快,因为无论是函数还是其导数都不包含复杂的数学运算。然而,当输入为负值的时候,ReLU 的学习速度可能会变得很慢,甚至使神经元直接无效,因为此时输入小于零而梯度为零,从而其权重无法得到更新,在剩下的训练过程中会一直保持静默。
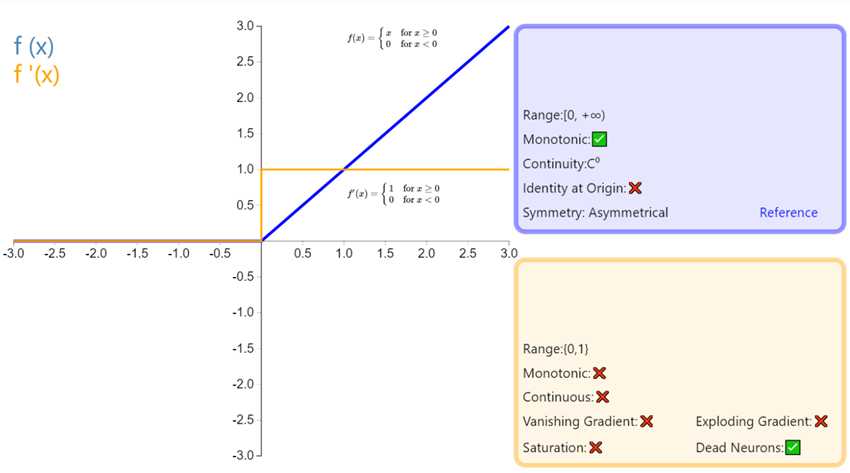
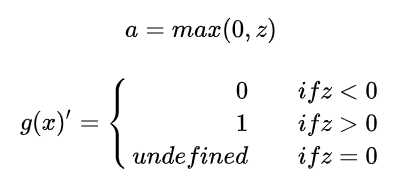
优点:
1.相比起Sigmoid和tanh,ReLU在SGD中能够快速收敛,这是因为它线性(linear)、非饱和(non-saturating)的形式。
2.Sigmoid和tanh涉及了很多很expensive的操作(比如指数),ReLU可以更加简单的实现。
3.有效缓解了梯度消失的问题。
4.在没有无监督预训练的时候也能有较好的表现。
缺点:
随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。如果发生这种情况,那么流经神经元的梯度从这一点开始将永远是0。也就是说,ReLU神经元在训练中不可逆地死亡了
3.4:Leaky ReLU
经典(以及广泛使用的)ReLU 激活函数的变体,带泄露修正线性单元(Leaky ReLU)的输出对负值输入有很小的坡度。由于导数总是不为零,这能减少静默神经元的出现,允许基于梯度的学习(虽然会很慢)。
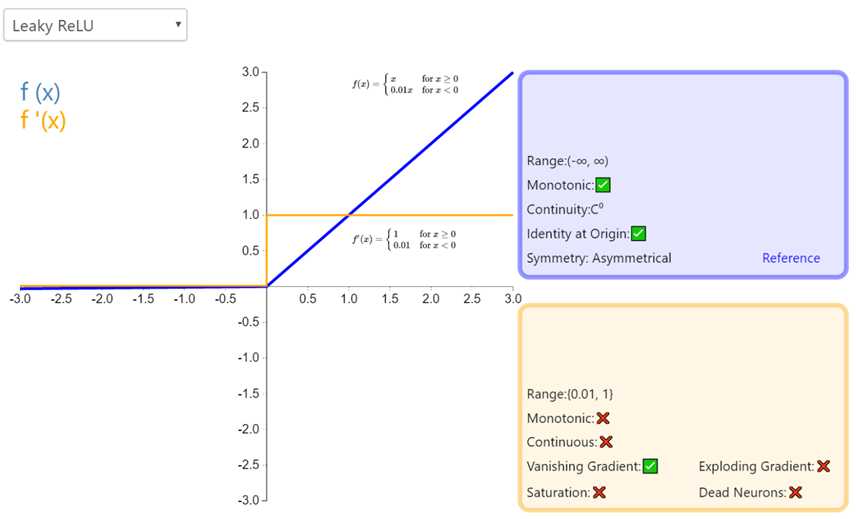
优缺点:人工神经网络中为什么ReLu要好过于tanh和sigmoid function?
1.采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
2.对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),这种现象称为饱和,从而无法完成深层网络的训练。而ReLU就不会有饱和倾向,不会有特别小的梯度出现。
3.Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进。
一般来说,隐藏层最好使用 ReLU 神经元。对于分类任务,Softmax 通常是更好的选择;对于回归问题,最好使用 Sigmoid 函数或双曲正切函数。
如果使用 ReLU,要小心设置 learning rate,注意不要让网络出现很多 "dead" 神经元,如果不好解决,可以试试 Leaky ReLU、PReLU 或者 Maxout.
附加:
Softmax:
做过多分类任务的同学一定都知道softmax函数。softmax函数,又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。下图展示了softmax的计算方法:
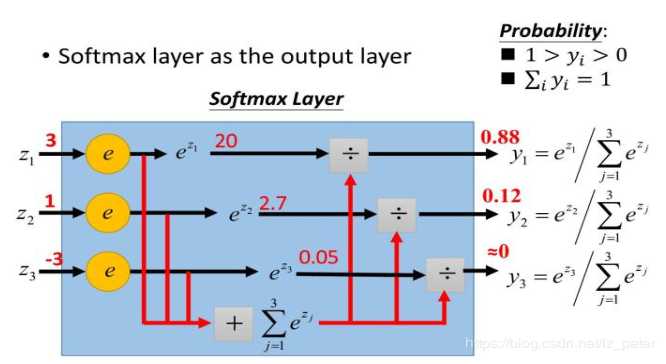
下面为大家解释一下为什么softmax是这种形式。我们知道指数函数的值域取值范围是零到正无穷。与概率取值相似的地方是它们都是非负实数。那么我们可以
1)利用指数函数将多分类结果映射到零到正无穷;
2)然后进行归一化处理,便得到了近似的概率。
总结一下softmax如何将多分类输出转换为概率,可以分为两步:
1)分子:通过指数函数,将实数输出映射到零到正无穷。
2)分母:将所有结果相加,进行归一化。
下图为斯坦福大学CS224n课程中对softmax的解释:

标签:展现 相互 输出 相对 exp round 丢失 不同的 span
原文地址:https://www.cnblogs.com/yifanrensheng/p/11832070.html