标签:分类 表示 weak 直接 证明 支持向量机 使用 正式 耦合
集成学习(ensemble learning)通过结合不同的学习算法来解决实际任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)。
如下图8.1所示,个体学习器通常由一个现有的学习算法产生。例如BP算法、SMO算法等等。而集成学习则通过某种策略将这些个体学习器结合起来并输出最终结果。根据个体学习器之间的算法差异,集成学习分类两大类:
1、同质集成(homogenous) 此时集成中的个体学习器只包含同一种算法,这时个体学习器也被称为基学习器(base learner)
2、异质集成(heterogenous)此时集成中的个体学习器不知包含一种算法,这时的个体学习器被称为组件学习器(component learner),也被直接称为个体学习器。
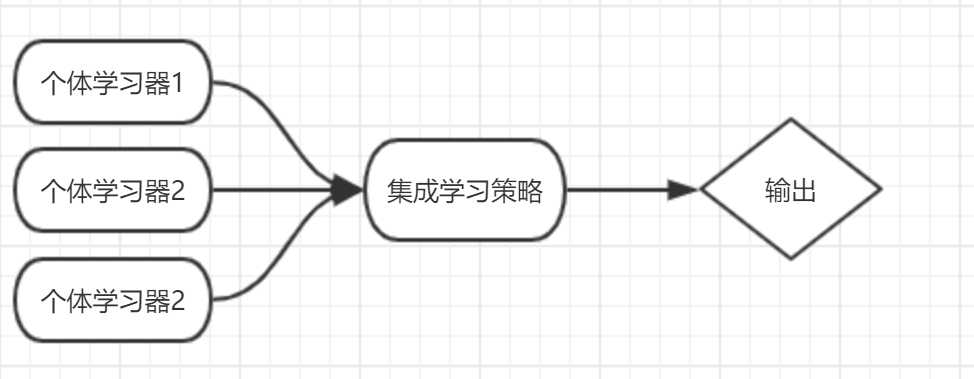
图8.1 集成学习示意图
在一般的经验内,当我们把参差不齐的事物集中在一起时,往往最终结果会趋向于最好与最差之间的某一中间值。集成学习类似,通过将不同的个体学习算法集中在一起,常可以得到比单一个体学习器更优秀的泛化性能,这对”弱学习器“(weak learner)尤其突出。虽然现实中处于多种原因,人们更倾向于选择强学习器进行集成学习,但集成学习的大部分理论研究都有关于弱学习器。(PS:弱学习器常指泛化性能略高于随即猜测的学习器;比如二分类问题上精度略高于50%的学习器即可称为弱学习器)
那么,以二分类问题为例引出问题,集成学习把不同的学习器结合起来,如何获得比最好的单一学习器更好的性能呢?(否则,集成学习将失去意义,直接选取最优学习器训练即可)。假设四个个体学习器1、2、3、4,按照投票表决机制对数据进行集成学习(少数服从多数原则)。在下面的问题中 令四者对四个数据进行学习预测,个体学习器表现如下:
| 数据1 | 数据2 | 数据3 | 数据4 | |
|
分类器1 |
? | ? | ? | ? |
| 分类器2 | ? | ? | ? | ? |
| 分类器3 | ? | ? | ? | ? |
| 分类器4 | ? | ? | ? | ? |
| 输出 | ? | ? | ? | ? |
(a)集成提升性能
| 数据1 | 数据2 | 数据3 | 数据4 | |
| 分类器1 | ? | ? | ? | ? |
| 分类器2 | ? | ? | ? | ? |
| 分类器3 | ? | ? | ? | ? |
| 分类器4 | ? | ? | ? | ? |
| 输出 | ? | ? | ? | ? |
(b)集成不起作用
| 数据1 | 数据2 | 数据3 | 数据4 | |
| 分类器1 | ? | ? | ? | ? |
| 分类器2 | ? | ? | ? | ? |
| 分类器3 | ? | ? | ? | ? |
| 分类器4 | ? | ? | ? | ? |
| 输出 | ? | ? | ? | ? |
(c)集成起负作用
图8.2 个体学习器学习情况
这个简单的例子告诉我们:个体学习器要有一定的准确率,至少不差于弱分类器(否则,直观上会大量出现情况c)。并且学习器之间要有差异,即多样性(diversity)。
继续以该二分类问题y∈{-1, 1}和真是函数f(x)为例,假定基分类器dd额错误率为μ,即对每个分类器hi有:
P(hi(x)≠f(x)) = μ ...(1)
假设通过T(为便于分析,将T设定为奇数)个分类器的投票表决产生最终结果,则根据概率论知识可以列出继承的错误率计算公式:
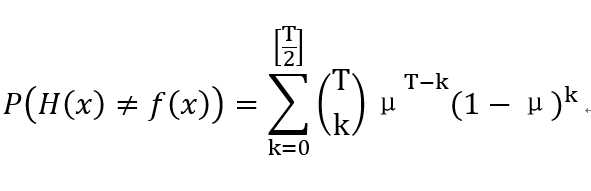 ...(2)
...(2)
(2)式显示,当数据T趋近于无穷大时,集成的错误率将迅速下降,最终趋向于零。
然而,上述问题的重要假设是基学习器的误差需要相互独立。实际上个体学习器针对同一数据进行训练,其误差不可能独立!现实中,学习器的”准确性“和”多样性“本来就存在一定的冲突,比如提高学习器的多样性必然会降低学习器的准确性。而如何产生”好而不同“的个体学习器正式集成学习的核心。
根据个体学习器的生成方式,目前的集成学习可以分为两大类:个体学习器存在强依赖关系必须串行生成的序列化方法以及个体学习器不存在强依赖关系可以并行生成的序列化方法;前者的代表为Boosting,后者的代表有Bagging以及”随机森林“(Random Forest)
AdaBoost有多种推到方式,比较容易理解的是“加性模型”(additive model),即通过基学习器的线性叠加组合 ΣαmGm(x) 来最小化指数损失函数(exponential loss function)
输入:训练数据集T={(x1,y1), (x2,y2), (x3,y3), ……, (xN,yN)},其中xi∈χ∈Rn,标记yi∈Y∈{-1, 1};弱学习算法;
输出:最终分类器G(x)
Processing:
1、初始化训练数据集的权值分布
D1 = (w11,……,w1i,……,w1N),w1i = 1/N i = 1,2,……,N
2、for m =1, 2, ……,M:
3、 使用具有权值分布Dm的训练数据学习,得到基本分类器: Gm(x): X -> {-1, 1}
4、 计算Gm(x)再训练数据上的分布误差率: em = ΣP(Gm(xi) ≠ yi) = Σwmi I(Gm(xi) ≠ yi)
5、 计算Gm(x) 的系数: αm = 1/2 * ln[ (1-em ) / em] ...(3)
6、 更新训练数据集的权值分布: Dm+1 = (wm+1,1 , ……,wm+1,i ,……,wm+1,N )
wm+1,i = wmi / Zm * exp( -αmyiGm(xi) ) 其中Zm为归一化的规范化因子 ...(4)
8、 end for
7、 构建基本分类器的线性组合: f(x) = ΣαmGm(x)
8、 输出最终分类器: G(x) = sign( ΣαmGm(x) )
end Processing
PS:第五行和第六行的公式推导可以参考周志华老师《机器学习》第八章 集成学习的8.2Boosting小节。
这里简单说明的是,通过对损失函数求导并置零可以得到(参考如上),线性叠加组合
sign(ΣαmGm(x))=sign(1/2*ln [P( f(x) = 1 | x) / P( f(x) = -1 | x) ])
= 1, P( f(x) = 1 | x) > P( f(x) = -1 | x)
-1, P( f(x) = 1 | x) <P( f(x) = -1 | x)
= argmax P(f(x) =y | x ) ...(5)
这意味着sign(ΣαmGm(x))达到了贝叶斯最优错误率,即若指数函数最小化,则分类错误率也最小化;这说明指数损失函数是分类任务原本0/1损失函数的一致性(consistency)替代损失函数。由于这个替代函数具有连续可微的特点,用它替代二分类问题中的0/1损失函数作为最优化目标,推导得出Processing内的系数以及更新权值分布公式。
注:一致性问题:替代损失函数在机器学习中经常使用,但是,通过替代损失函数求解得到的解是否是原问题的解?这在理论上被称为替代损失函数的一致性问题。
具体的例子可以参考李航《统计学习方法》8.1.3 AdaBoost的例子,或者CSDN上关于AdaBoost的讲解。博客:https://blog.csdn.net/guyuealian/article/details/70995333 中附有详细的例子讲解和代码实现。
Adaboost算法的某些特性是非常好的,这里主要介绍Adaboost的两个特性。(1)是训练的错误率上界,随着迭代次数的增加,会逐渐下降;(2)是Adaboost算法即使训练次数很多,也不会出现过拟合的问题。关于这两方面的研究和分析,我建议各大网友,还是看看大神的博客:https://blog.csdn.net/v_july_v/article/details/40718799
Java代码实现回头我会上传。鼓励伙伴们自己编写,流程图也很简单,实现起来也不难。
由 8.1小节可知,为了得到泛化能力较强的集成,我们应该尽量保证基学习器之间的相互“独立”。虽然“独立”在现时任务中无法实现,但我们可以借助已有手段尽可能降低基学习器之间的耦合性。最常用的方法便是自助采样法(bootstrap sampling)。
8.3.1 Bagging
Bagging是并行式集成学习方法的著名代表,其直接基于自助采样法。即:给定包含m个数据的数据集,随即从m个数据集中copy一份数据到采样集中,重复m次便得到大小同为m的采样集。因此,样本在m次采样中始终不被采样到的概率为:
lim m->∞ (1 - 1/m)m = 1/e = 0.368 ...(6)
照这样,我们基于T个包含m个数据集的采样集分别训练得到各自的基学习器,再将这些基学习器组合起来,便是Bagging的基本流程。
容易理解,训练一个Bagging集成与直接使用基学习器训练一个学习器的复杂度是同阶的,即Bagging是一个很高效的集成学习算法。同时,根据(6)式我们知每次训练基学习器时会有将近36.8%的数据未参与训练。这些未参与训练的数据可用作”包外估计“(out-of-bag estimate),可用于泛化误差的估计等用途。
8.3.2 Random Forest
随机森林(RF)在以决策树为基学习器构建Bagging集成学习的基础上,进一步在决策树训练的过程中引入随机属性的选择。与传统决策树做对比:假定划分某结点时,该结点包含d个属性,传统决策树会选择最优的属性作为划分选择(如信息增益最大的一项);而RF则会首先在d个属性中随机选择k个属性,再从k个属性集合内选择出最优的属性作为划分选择。当k = d时,RF与传统决策树等价;当k = 1时,RF便是随机选择一个属性作为划分选择。根据现有知识,推荐值k = log2d
随机森林改编于Bagging,简单易实现,在很多问题中都展现出不俗的能力,被誉为”代表集成学习技术水平的方法“。比Bagging集成更突出的一点,Bagging集成的”多样性“来自于样本扰动(初始化样本集不同而来),而随机森林中基学习器不仅来自于样本扰动,也引入属性扰动,通过增加基学习器之间的差异进一步增加了集成的泛化性能。
俗话说的好,“三个臭皮匠顶个诸葛亮”,学习器结合可能从多方面带来好处:
1、从统计方面来看,由于学习任务的假设空间很大,少量的假设在训练集上达到同等的性能,会导致训练得到的模型泛化性能不佳,结合多个学习器在一定程度上可以冲淡这种情况;
2、从计算方面来看,单一的学习器容易陷入局部极小现象,而有的局部极小位置对应的泛化性能很糟糕,而通过多次运行之后进行结合,可以降低陷入糟糕局部极小点的风险;
3、从表示方面来看,实际问题的真实假设可能不在算法的假设空间内,而结合多个算法的假设空间可能拓展相应的空间,从而学得更好的近似。
假定集成包含T个基学习器 {h1, h2,……,hT},其中hi在示例x上的输出为hi(x)。
8.4.1 平均法
对数值输出型hi(x) ,最常见的结合策略为平均法(averaging)。
平均法包含简单平均法和加权平均法两类。顾名思义,简单平均法是加权平均法各权值相等的特例。根据已有实验能够证明,只有保证非负权值才能确保集成性能优于单一基学习器。因此,在集成学习中,一般对权值施加以非负约束。与此同时,现时任务中的训练数据通常不充分或含有噪声,对于大量的训练样本时,加权平均法确定的权值可能受到“污染”,极容易造成过拟合。并非加权平均法一定优于简单平均法,在个体学习器差异不大时,宜使用简单平均法。
8.4.2 投票法
对分类任务来说,学习器hi将从类别标记集合{c1, c2, ……,cN}中预测出一个标记,最常见的结合策略就是投票法(voting)。为便于讨论,我们将hi在样本x上的预测输出表示为N维向量(hi1(x), hi2(x), ..., hiN(x));其中hij(x)为hi在第j个标记上的输出。
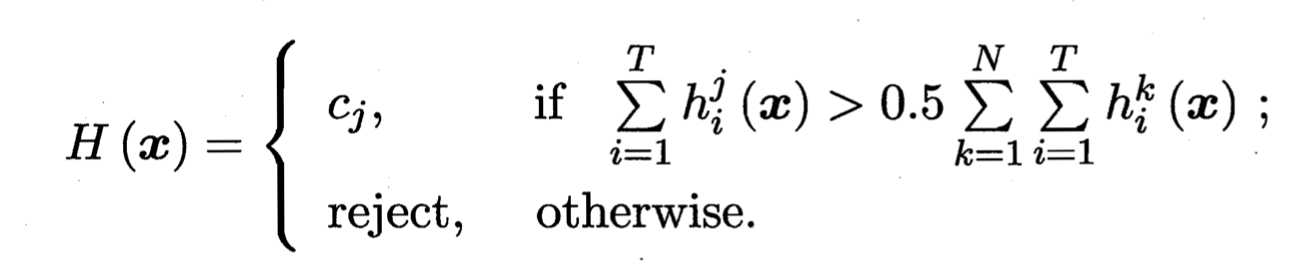
即若某标记的得票数超过50%则预测为该标记,否则拒绝预测;
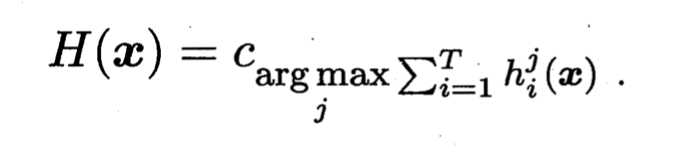
即将得票数最多的标记作为预测输出;如果有多个标记得票数相同,则随机数出其中的一个标记;
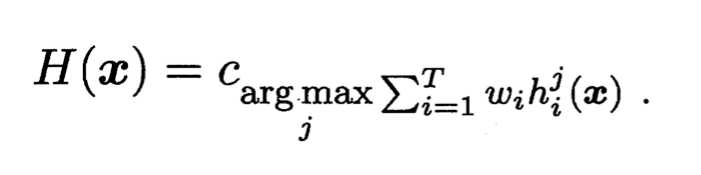
与加权平均法类似,权值给定非负约束条件。
在现实中,不同类型的个体学习器hij(x)对应着不同类型的输出值,常见的有:

8.4.3 学习法
当训练数据很多时,更强大的结合策略“学习法”应运而生,即通过另一个学习器来进行结合。Stacking是学习法的代表算法。这里我们把个体学习器称为初级学习器,用于结合的学习器称为次级学习器或者元学习器。

图8.3 Stacking算法
长话短说,为了避免直接采用初级学习器训练结果作为样本输入到次级学习器而带来的严重过拟合现象,用于训练初级训练器的样本多采用交叉验证法等方式,而其未使用的样本用于次级学习器的学习。

8.5.1 误差-分歧分解
“误差-分歧分解”(error-ambiguity decomposition)推导可自己搜索,其最终结果明确表示:个体学习器准确度越高,多样性越大,则集成越好。
8.5.2 多样性度量
顾名思义,多样性度量(diversity measure)用于度量集成中个体分类器的多样性,即估算个体学习器的多样化程度。典型做法是考虑个体分类器两两之间的相似/不相似性。
给定数据集D = {(x1,y1), (x2,y2), ……,(xm,ym)},对二分类任务,yii={-1,1},分类器hi与hj的预测结果列联表(contingency table)为:
| hi = +1 | hi = +1 | |
| hj = +1 | a | c |
| hj = +1 | b | d |
其中,a表示两个分类器均预测为正类的正类的样本数目;b、c、d含义类推;a+b+c+d=m。
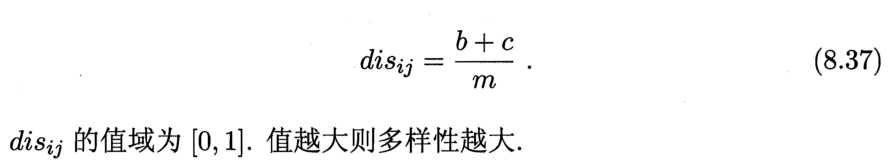

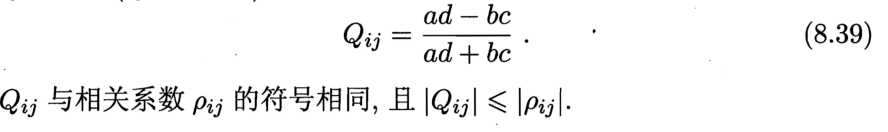

![]()
8.5.3 多样性增强
为了尽量保证个体学习器的独立,我们对原始训练数据集采取的诸如自主采样法等手段,就是通过提高数据样本扰动来实现多样性增强。值得一提的是,例如线性学习器、支持向量机、朴素贝叶斯等基学习器对数据样本的扰动不敏感,对此类基学习器进行集成往往需要使用输入属性扰动等手段。
典型的随机森林(Random Forest)就是在Bagging算法上利用输入属性扰动得到的优良算法。若数据只包含少量的属性或者冗余属性很少,则不宜采用输入属性扰动的手段处理。
标签:分类 表示 weak 直接 证明 支持向量机 使用 正式 耦合
原文地址:https://www.cnblogs.com/LiYimingRoom/p/11836954.html