标签:复制 执行 ati 提前 分配 方法 pac 运行 基于
标记—清除算法是第一种使用和比较完善的垃圾回收算法,后续的收集算法都是基于其设计思路并对其不足进行改进而得到的。
该算法分为“标记”和“清除”两个阶段:
它的主要不足有两个:
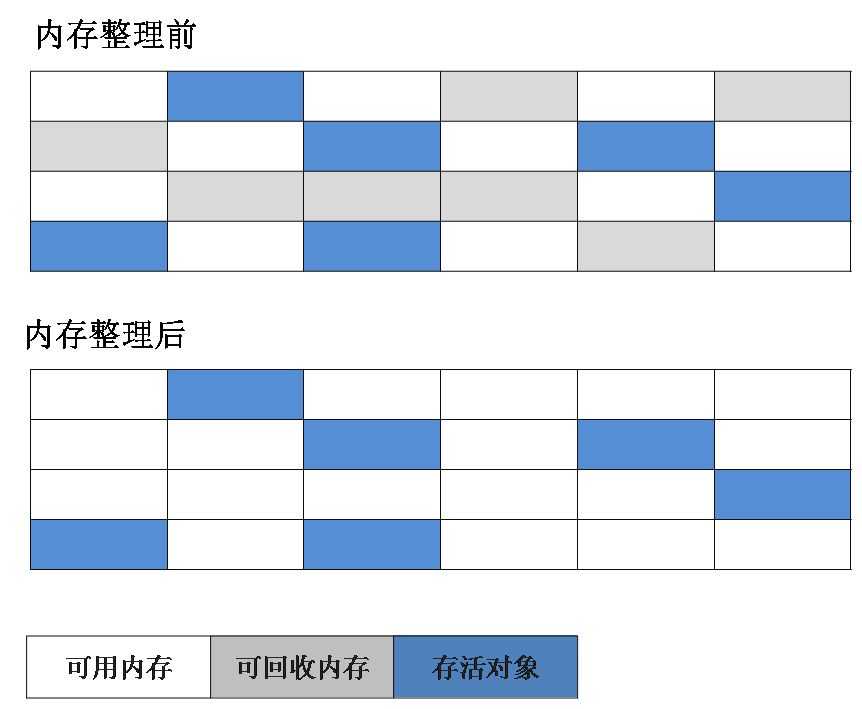
复制算法通过采用双区域交替使用这种方式解决了标记—清除算法中效率低下的问题。它将可可用内存划分为两个等量的区域(使用区和空闲区),每次只使用一块。当正在使用的区域需要进行垃圾回收时,存活的对象将被复制到另外一块区域。原先被使用的区域被重置,转为空闲区。这样就使每次的内存回收都是对内存区间的一半进行回收。
这种算法的代价是:
将内存缩小为了原来的一半,空间利用率较低。
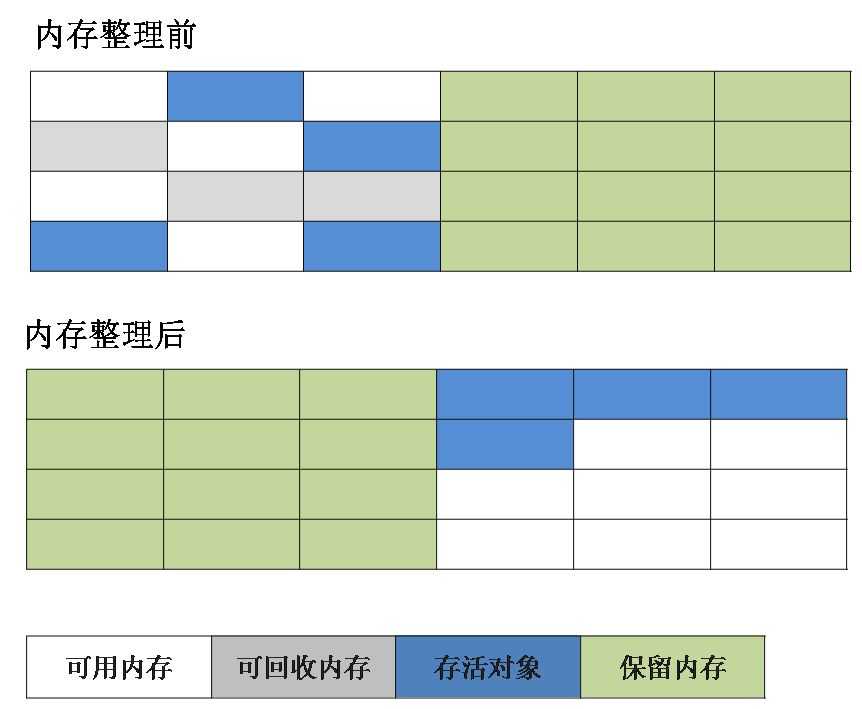
基于复制算法的上面缺陷,可以将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的内存会被“浪费”。
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
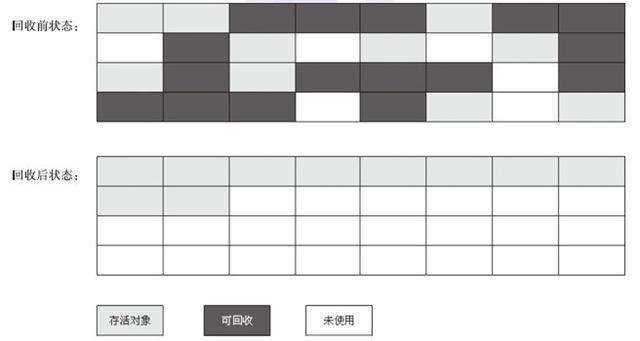
所以根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
当前商业虚拟机的垃圾收集都采用“分代收集”(Generational Collection)算法,这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块。
一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
标签:复制 执行 ati 提前 分配 方法 pac 运行 基于
原文地址:https://www.cnblogs.com/zjfjava/p/11838480.html