标签:read == 动态 问题 jpg info 比较 numpy version
我们知道现在主流的VQA都是神经网络,特征序列输入RNN或者LSTM,基于注意力机制这样做一套,经典的如Show Attend and Tell、Top down Attention等,都是基于神经网络做的视觉问答,我这里基于知识图谱做的,所以势必牵扯到本体建模,由于时间有限,所以我选择了一张比较简单的图片进行本体建模,而且只做了一张图片的建模。但如果能够对整个数据集建模(人力、财力够的话),或者通过某些图方法实现从图片信息和标注信息中自动本体建模,那么我这一套流程感觉有很有意义了。所以,我知识提出一个思路,并简单实现下Demo,并不能做工程上的应用。
我选知识图谱这门课和做这个项目的动机均来自:
?Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection

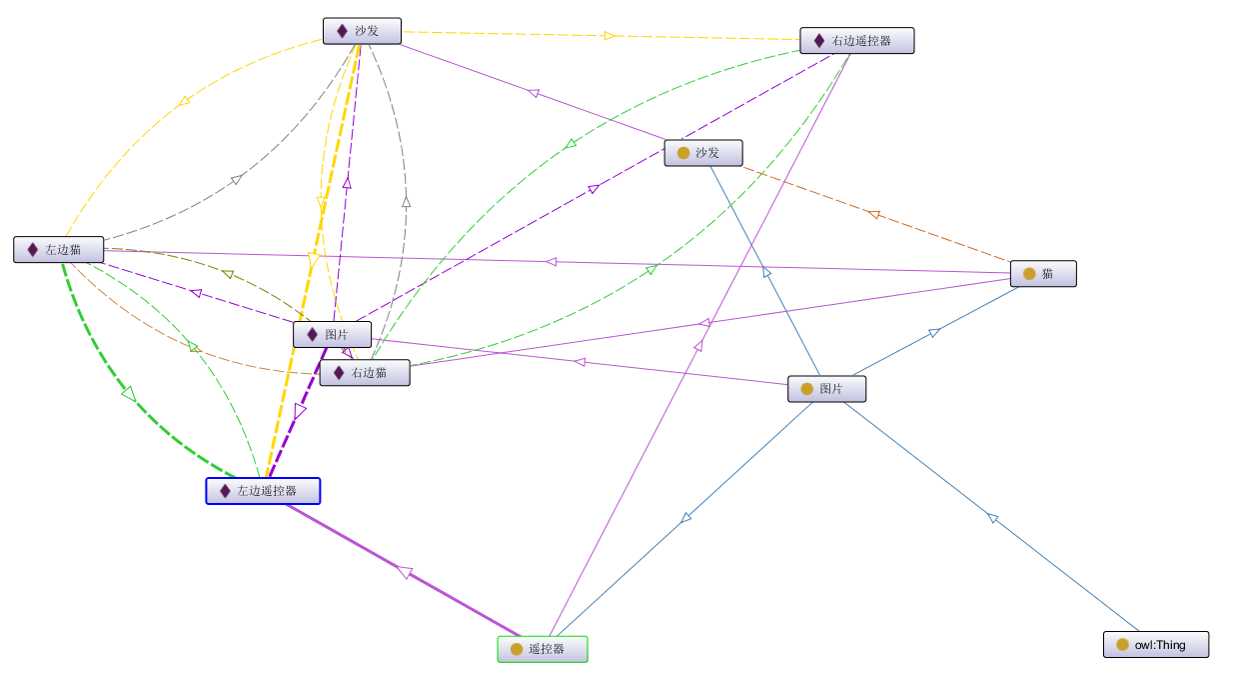
这张图片是来自COCO数据集的一张图片,我精挑细选才找到这么一张比较简单的哈,建模的过程是使用 Protege 鼠标点一点就完成了,关系呢主要是“在左边”、“在右边”、“在上边”、“在下边”、”躺在“等等这样描述位置的关键词,最后建立好的本体如图可视化所示:
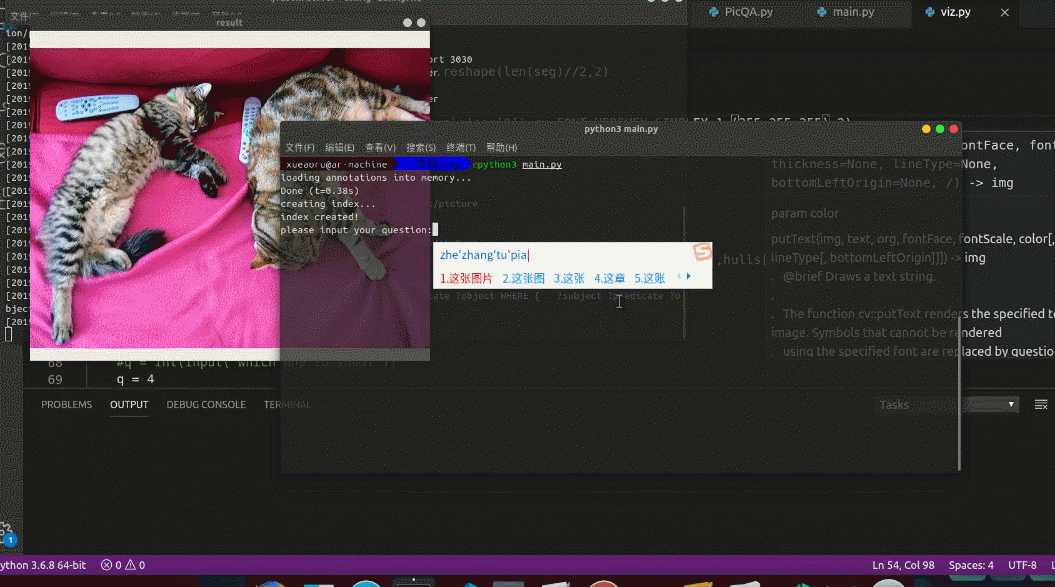
我们从命令行输入一个问题,这肯定就涉及到机器要理解我们问的问题了对吧。
首先肯定标准的Jieba分词,这个就不解释了。
然后呢?我们要知道他问的是啥,是问图里面有什么东西呢,还是问图里有多少只猫呢。所以我先去匹配了下出现多少、什么等词,每个词作为一个问句类型。对每个问句类型就要做不同的处理了。
什么:1
哪里:2
多少:3
当然这种匹配肯定不是完全能匹配到的,所以最好去训练个贝叶斯分类器对jieba分词的结果分类得到对应的问句类型。
同样的,根据预定义的实体名称去匹配实体,这样就拿到了问句中的实体和问句类型。
然后根据他们出现的先后顺序,又可以与预定义的问题匹配上,每个预定义问题又对应一种查询方式,所以实现最终的查询。
这一块应该给一个NLP懂得比较多的人做,我自己不做这块所以说的比较简单。
SELECT ?object
FROM <http://test.com>
where {
<http://example.com/{subject}> <http://example.com/{subject}> ?object
};
不同的问题不同的查询方式,这里是查宾语的例子,得到查询结果。
COCO数据集里提供了json格式的标注,利用COCOAPI我们得到凸包格式标注,然后使用Opencv画一下轮廓就好了,至于动态效果,就是waitkey。
代码:
'''
@Descripttion: This is Aoru Xue's demo, which is only for reference.
@version:
@Author: Aoru Xue
@Date: 2019-11-08 13:10:19
@LastEditors: Aoru Xue
@LastEditTime: 2019-11-08 13:18:19
'''
from pycocotools.coco import COCO
import numpy as np
import cv2 as cv
import copy
color_map = {
0:[220, 20, 60],
1:[119, 11, 32],
2:[0, 0, 142],
3:[0,255,255],
4:[250, 170, 30],
5:[100, 170, 30]
}
def id2name(vid):
dic = {
0:"Remote Control",
1:"Remote Control",
2:"Sofa",
3:"Frame",
4:"Cat",
5:"Cat"
}
return dic[vid]
class Viz():
def __init__(self):
annFile = './instances_val2017.json'
self.coco = COCO(annFile)
self.sid = "000000039769"
self.annIds = self.coco.getAnnIds(imgIds=int(self.sid), iscrowd=None)
self.img = cv.imread("./" + self.sid + ".jpg")
self.show = copy.copy(self.img)
def anns(self,ann_id = 0):
return self.coco.loadAnns(self.annIds[ann_id:ann_id + 1])
def draw_(self,ann_id = 0,is_mask = False):
instance = self.anns(ann_id = ann_id)[0]
seg = instance["segmentation"][0]
if is_mask :
seg = np.array(seg,dtype = np.int).reshape(len(seg)//2,2)
cv.drawContours(self.show,[seg],-1,tuple(color_map[ann_id]),-1)
else:
seg = np.array(seg,dtype = np.int).reshape(len(seg)//2,2)
self.draw_hull(seg)
print(seg[0])
cv.putText(self.show,id2name(ann_id),tuple(seg[0]),cv.FONT_HERSHEY_SIMPLEX,1,(255,255,255),2)
cv.imshow("result",self.show)
def clear_(self):
self.show = copy.copy(self.img)
cv.imshow("result",self.show)
def draw_hull(self,hulls):
for i in range(len(hulls)):
cv.line(self.show,(hulls[i][0],hulls[i][1]),(hulls[(i+1)%len(hulls)][0],hulls[(i+1)%len(hulls)][1]),(0,0,255),3)
if __name__ == "__main__":
viz = Viz()
#q = int(input("which one to show?"))
q = 4
viz.draw_(q,is_mask = True)
cv.waitKey(0)
"""
遥控器-右:0
遥控器-左:1
沙发:2
左边猫子:4
右边猫子:5
"""
晚点把NLP那部分完善一下发github。
标签:read == 动态 问题 jpg info 比较 numpy version
原文地址:https://www.cnblogs.com/aoru45/p/11839263.html