标签:新版本 html ddt type tno 递归 rtl mic clock
对一般小公司来说 可能yarn调度能力足够了 但是对于大规模集群1000 or 2000+的话 yarn的调度性能捉襟见肘
恰好网上看到一篇很好的文章https://tech.meituan.com/2019/08/01/hadoop-yarn-scheduling-performance-optimization-practice.html
参考了YARN-5969 发现hadoop2.9.0已经修正了该issue 实测提高了调度性能
FairScheduler 调度方式有两种
心跳调度:Yarn的NodeManager会通过心跳的方式定期向ResourceManager汇报自身状态 伴随着这次rpc请求 会触发Resourcemanager 触发nodeUpdate()方法 为这个节点进行一次资源调度
持续调度:有一个固定守护线程每隔很短的时间调度 实时的资源分配,与NodeManager的心跳出发的调度相互异步并行进行
心跳调度作为一个线程 每次运行
每次nodeUpdate 走的都是相同的逻辑
// If the node is decommissioning, send an update to have the total // resource equal to the used resource, so no available resource to // schedule. if (nm.getState() == NodeState.DECOMMISSIONING) { this.rmContext .getDispatcher() .getEventHandler() .handle( new RMNodeResourceUpdateEvent(nm.getNodeID(), ResourceOption .newInstance(getSchedulerNode(nm.getNodeID()) .getUsedResource(), 0))); } if (continuousSchedulingEnabled) { if (!completedContainers.isEmpty()) { //心跳调度 attemptScheduling(node); } } else { attemptScheduling(node); //持续调度 } // Updating node resource utilization node.setAggregatedContainersUtilization( nm.getAggregatedContainersUtilization()); node.setNodeUtilization(nm.getNodeUtilization());
continuousSchedulingAttempt
/**
* Thread which attempts scheduling resources continuously,
* asynchronous to the node heartbeats.
*/
private class ContinuousSchedulingThread extends Thread {
@Override
public void run() {
while (!Thread.currentThread().isInterrupted()) {
try {
continuousSchedulingAttempt();
Thread.sleep(getContinuousSchedulingSleepMs());
} catch (InterruptedException e) {
LOG.warn("Continuous scheduling thread interrupted. Exiting.", e);
return;
}
}
}
}
之后进行一次node节点 根据资源宽松情况的排序
void continuousSchedulingAttempt() throws InterruptedException { long start = getClock().getTime(); List<NodeId> nodeIdList = new ArrayList<NodeId>(nodes.keySet()); // Sort the nodes by space available on them, so that we offer // containers on emptier nodes first, facilitating an even spread. This // requires holding the scheduler lock, so that the space available on a // node doesn‘t change during the sort. synchronized (this) { Collections.sort(nodeIdList, nodeAvailableResourceComparator); } // iterate all nodes for (NodeId nodeId : nodeIdList) { FSSchedulerNode node = getFSSchedulerNode(nodeId); try { if (node != null && Resources.fitsIn(minimumAllocation, node.getAvailableResource())) { attemptScheduling(node); } } catch (Throwable ex) { LOG.error("Error while attempting scheduling for node " + node + ": " + ex.toString(), ex); if ((ex instanceof YarnRuntimeException) && (ex.getCause() instanceof InterruptedException)) { // AsyncDispatcher translates InterruptedException to // YarnRuntimeException with cause InterruptedException. // Need to throw InterruptedException to stop schedulingThread. throw (InterruptedException)ex.getCause(); } } }
依次对node遍历分配Container
queueMgr.getRootQueue().assignContainer(node) 从root遍历树 对抽象的应用资源遍历
boolean validReservation = false; FSAppAttempt reservedAppSchedulable = node.getReservedAppSchedulable(); if (reservedAppSchedulable != null) { validReservation = reservedAppSchedulable.assignReservedContainer(node); } if (!validReservation) { // No reservation, schedule at queue which is farthest below fair share int assignedContainers = 0; Resource assignedResource = Resources.clone(Resources.none()); Resource maxResourcesToAssign = Resources.multiply(node.getAvailableResource(), 0.5f); while (node.getReservedContainer() == null) { boolean assignedContainer = false; Resource assignment = queueMgr.getRootQueue().assignContainer(node); if (!assignment.equals(Resources.none())) { assignedContainers++; assignedContainer = true; Resources.addTo(assignedResource, assignment); } if (!assignedContainer) { break; } if (!shouldContinueAssigning(assignedContainers, maxResourcesToAssign, assignedResource)) { break; } }
接下来在assignContainer 方法中对子队列使用特定的比较器排序这里是fairSchduler
@Override public Resource assignContainer(FSSchedulerNode node) { 对于每一个服务器,对资源树进行一次递归搜索 Resource assigned = Resources.none(); // If this queue is over its limit, reject if (!assignContainerPreCheck(node)) { return assigned; } // Hold the write lock when sorting childQueues writeLock.lock(); try { Collections.sort(childQueues, policy.getComparator()); } finally { writeLock.unlock(); }
对队列下的app排序
/* * We are releasing the lock between the sort and iteration of the * "sorted" list. There could be changes to the list here: * 1. Add a child queue to the end of the list, this doesn‘t affect * container assignment. * 2. Remove a child queue, this is probably good to take care of so we * don‘t assign to a queue that is going to be removed shortly. */ readLock.lock(); try { for (FSQueue child : childQueues) { assigned = child.assignContainer(node); if (!Resources.equals(assigned, Resources.none())) { break; } } } finally { readLock.unlock(); } return assigned;
assignContainer 可能传入的是app 可能传入的是一个队列 是队列的话 进行递归 直到找到app为止(root(FSParentQueue)节点递归调用assignContainer(),最终将到达最终叶子节点的assignContainer()方法,才真正开始进行分配)

我们在这里 关注的就是排序
hadoop2.8.4 排序类 FairSharePolicy中的 根据权重 需求的资源大小 和内存占比 进行排序 多次获取
getResourceUsage() 产生了大量重复计算 这个方法是一个动态获取的过程(耗时)
@Override
public int compare(Schedulable s1, Schedulable s2) {
double minShareRatio1, minShareRatio2;
double useToWeightRatio1, useToWeightRatio2;
Resource minShare1 = Resources.min(RESOURCE_CALCULATOR, null,
s1.getMinShare(), s1.getDemand());
Resource minShare2 = Resources.min(RESOURCE_CALCULATOR, null,
s2.getMinShare(), s2.getDemand());
boolean s1Needy = Resources.lessThan(RESOURCE_CALCULATOR, null,
s1.getResourceUsage(), minShare1);
boolean s2Needy = Resources.lessThan(RESOURCE_CALCULATOR, null,
s2.getResourceUsage(), minShare2);
minShareRatio1 = (double) s1.getResourceUsage().getMemorySize()
/ Resources.max(RESOURCE_CALCULATOR, null, minShare1, ONE).getMemorySize();
minShareRatio2 = (double) s2.getResourceUsage().getMemorySize()
/ Resources.max(RESOURCE_CALCULATOR, null, minShare2, ONE).getMemorySize();
useToWeightRatio1 = s1.getResourceUsage().getMemorySize() /
s1.getWeights().getWeight(ResourceType.MEMORY);
useToWeightRatio2 = s2.getResourceUsage().getMemorySize() /
s2.getWeights().getWeight(ResourceType.MEMORY);
int res = 0;
if (s1Needy && !s2Needy)
res = -1;
else if (s2Needy && !s1Needy)
res = 1;
else if (s1Needy && s2Needy)
res = (int) Math.signum(minShareRatio1 - minShareRatio2);
else
// Neither schedulable is needy
res = (int) Math.signum(useToWeightRatio1 - useToWeightRatio2);
if (res == 0) {
// Apps are tied in fairness ratio. Break the tie by submit time and job
// name to get a deterministic ordering, which is useful for unit tests.
res = (int) Math.signum(s1.getStartTime() - s2.getStartTime());
if (res == 0)
res = s1.getName().compareTo(s2.getName());
}
return res;
}
}
新版优化后如下
@Override public int compare(Schedulable s1, Schedulable s2) { int res = compareDemand(s1, s2); // Pre-compute resource usages to avoid duplicate calculation Resource resourceUsage1 = s1.getResourceUsage(); Resource resourceUsage2 = s2.getResourceUsage(); if (res == 0) { res = compareMinShareUsage(s1, s2, resourceUsage1, resourceUsage2); } if (res == 0) { res = compareFairShareUsage(s1, s2, resourceUsage1, resourceUsage2); } // Break the tie by submit time if (res == 0) { res = (int) Math.signum(s1.getStartTime() - s2.getStartTime()); } // Break the tie by job name if (res == 0) { res = s1.getName().compareTo(s2.getName()); } return res; } private int compareDemand(Schedulable s1, Schedulable s2) { int res = 0; Resource demand1 = s1.getDemand(); Resource demand2 = s2.getDemand(); if (demand1.equals(Resources.none()) && Resources.greaterThan( RESOURCE_CALCULATOR, null, demand2, Resources.none())) { res = 1; } else if (demand2.equals(Resources.none()) && Resources.greaterThan( RESOURCE_CALCULATOR, null, demand1, Resources.none())) { res = -1; } return res; } private int compareMinShareUsage(Schedulable s1, Schedulable s2, Resource resourceUsage1, Resource resourceUsage2) { int res; Resource minShare1 = Resources.min(RESOURCE_CALCULATOR, null, s1.getMinShare(), s1.getDemand()); Resource minShare2 = Resources.min(RESOURCE_CALCULATOR, null, s2.getMinShare(), s2.getDemand()); boolean s1Needy = Resources.lessThan(RESOURCE_CALCULATOR, null, resourceUsage1, minShare1); boolean s2Needy = Resources.lessThan(RESOURCE_CALCULATOR, null, resourceUsage2, minShare2); if (s1Needy && !s2Needy) { res = -1; } else if (s2Needy && !s1Needy) { res = 1; } else if (s1Needy && s2Needy) { double minShareRatio1 = (double) resourceUsage1.getMemorySize() / Resources.max(RESOURCE_CALCULATOR, null, minShare1, ONE) .getMemorySize(); double minShareRatio2 = (double) resourceUsage2.getMemorySize() / Resources.max(RESOURCE_CALCULATOR, null, minShare2, ONE) .getMemorySize(); res = (int) Math.signum(minShareRatio1 - minShareRatio2); } else { res = 0; } return res; } /** * To simplify computation, use weights instead of fair shares to calculate * fair share usage. */ private int compareFairShareUsage(Schedulable s1, Schedulable s2, Resource resourceUsage1, Resource resourceUsage2) { double weight1 = s1.getWeights().getWeight(ResourceType.MEMORY); double weight2 = s2.getWeights().getWeight(ResourceType.MEMORY); double useToWeightRatio1; double useToWeightRatio2; if (weight1 > 0.0 && weight2 > 0.0) { useToWeightRatio1 = resourceUsage1.getMemorySize() / weight1; useToWeightRatio2 = resourceUsage2.getMemorySize() / weight2; } else { // Either weight1 or weight2 equals to 0 if (weight1 == weight2) { // If they have same weight, just compare usage useToWeightRatio1 = resourceUsage1.getMemorySize(); useToWeightRatio2 = resourceUsage2.getMemorySize(); } else { // By setting useToWeightRatios to negative weights, we give the // zero-weight one less priority, so the non-zero weight one will // be given slots. useToWeightRatio1 = -weight1; useToWeightRatio2 = -weight2; } } return (int) Math.signum(useToWeightRatio1 - useToWeightRatio2); } }
用了测试环境集群 比较了修改前后两次队列排序耗时
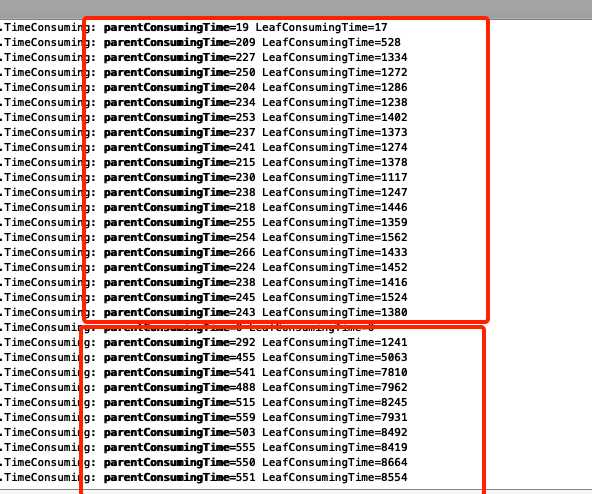
上面红框里为 新版本 下面红框为老版本 虽然没有进行压测 但是在同样的调度任务前提下 是有说服力的 在大集群上每秒调度上千万乃至上亿次该方法时 调度优化变的明显
hadoop2.9.0之前的版本yarn RM fairScheduler调度性能优化
标签:新版本 html ddt type tno 递归 rtl mic clock
原文地址:https://www.cnblogs.com/songchaolin/p/11844217.html