标签:red 后台 重要 直接 png redis key img 忽略 管理员
“分布式锁”是用来解决分布式应用中“并发冲突”的一种常用手段,实现方式一般有基于zookeeper及基于redis二种。具体到业务场景中,我们要考虑二种情况:比如:一些不是很重要的场景,比如“监控数据持续上报”,某一篇文章的“已读/未读”标识位更新,对于同一个id,如果并发的请求同时到达,只要有一个请求处理成功,就算成功。
用活动图表示如下:
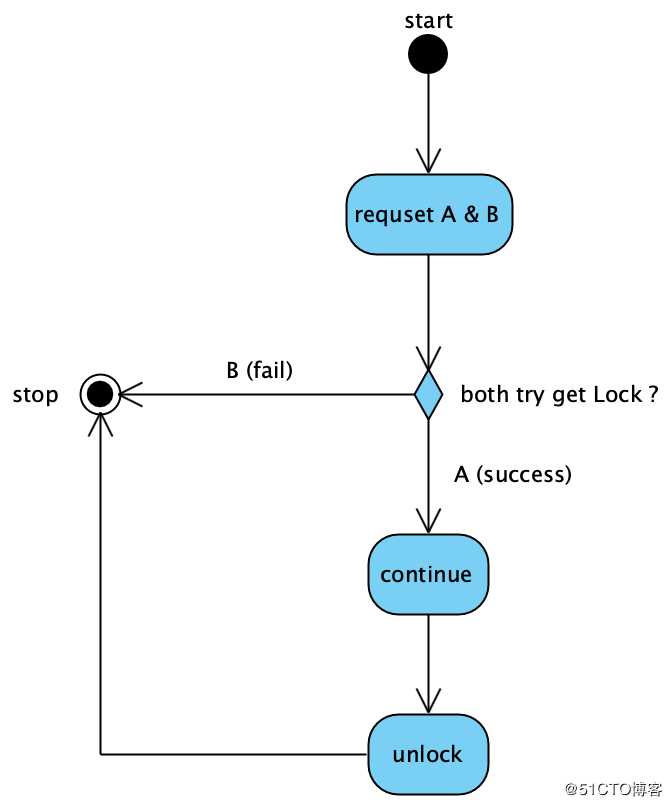
比如:一个订单,客户正在前台修改地址,管理员在后台同时修改备注。地址和备注字段的修改,都必须正确更新,这二个请求同时到达的话,如果不借助db的事务,很容易造成行锁竞争,但用事务的话,db的性能显然比不上redis轻量。
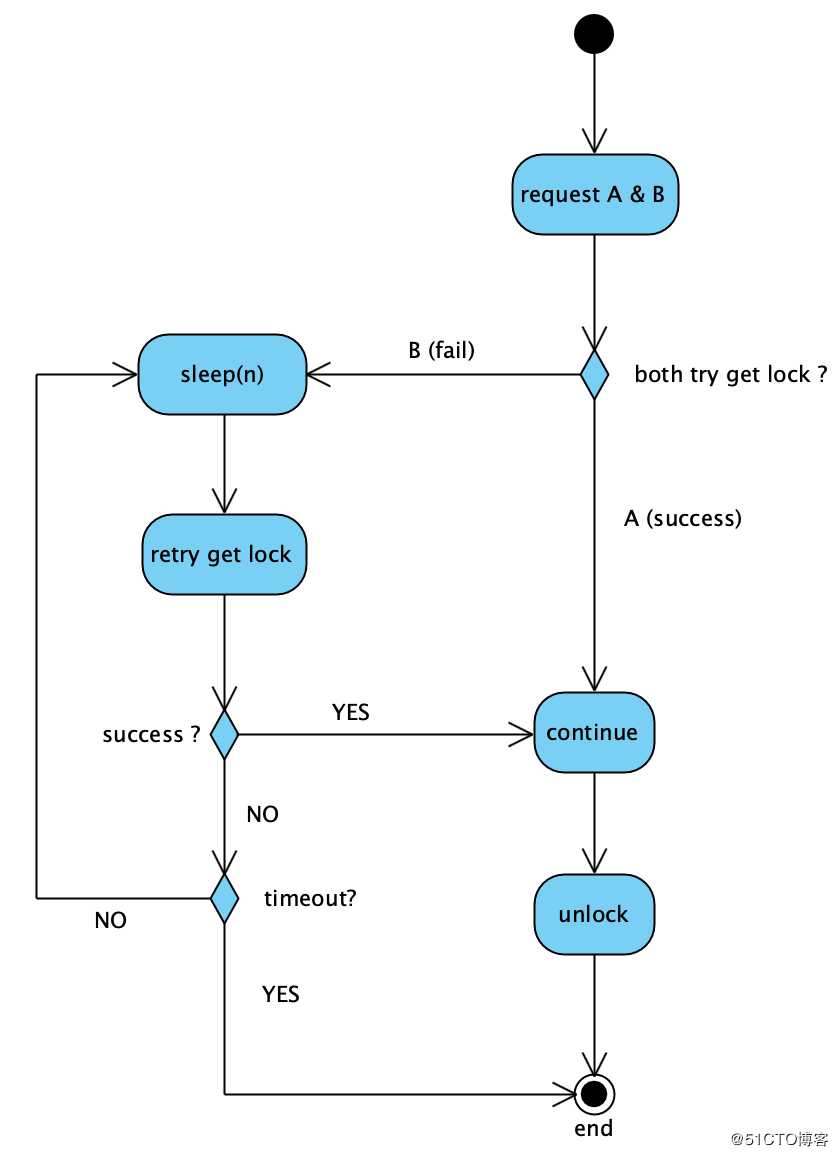
解决思路:A,B二个请求,谁先抢到分布式锁(假设A先抢到锁),谁先处理,抢不到的那个(即:B),在一旁不停等待重试,重试期间一旦发现获取锁成功,即表示A已经处理完,把锁释放了。这时B就可以继续处理了。
但有二点要注意:
a、需要设置等待重试的最长时间,否则如果A处理过程中有bug,一直卡死,或者未能正确释放锁,B就一直会等待重试,但是又永远拿不到锁。
b、等待最长时间,必须小于锁的过期时间。否则,假设锁2秒过期自动释放,但是A还没处理完(即:A的处理时间大于2秒),这时锁会因为redis key过期“提前”误释放,B重试时拿到锁,造成A,B同时处理。(注:可能有同学会说,不设置锁的过期时间,不就完了么?理论上讲,确实可以这么做,但是如果业务代码有bug,导致处理完后没有unlock,或者根本忘记了unlock,分布式锁就会一直无法释放。所以综合考虑,给分布式锁加一个“保底”的过期时间,让其始终有机会自动释放,更为靠谱)
用活动图表示如下:
用2个线程模拟并发场景,跑起来后,输出如下:

可以看到T2线程没抢到锁,直接抛出了预期的异常。
把44行的注释打开,即:换成不允许丢数据的模式,再跑一下:

可以看到,T1先抢到锁,然后经过2秒的处理后,锁释放,这时T2重试拿到了锁,继续处理,最终释放。
标签:red 后台 重要 直接 png redis key img 忽略 管理员
原文地址:https://blog.51cto.com/14230003/2449729