标签:nod 存在 表达 hadoop hive 文件 其他 通过 dfs
Hive看上去很像关系型数据库。不过,Hive实现和使用的方式和传统的关系型数据库非常不同。Hive是反模式的。
本文将重点介绍Hive中哪些模式是用户应该使用的,儿哪些是应该避免的
一、按天划分的表
这种每天一张表的方式在数据库领域是反模式的一种方式,但因为实际情况下,数据集增长的很快,这种方式应用还是比较广泛的。
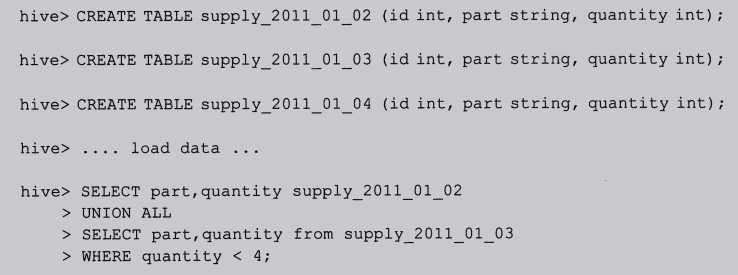
对于Hive,这种情况下应该使用分区表。
Hive通过where子句中的表达式来选择查询所需的指定的分区。这样的产需效率高,而且看起来清晰明了。
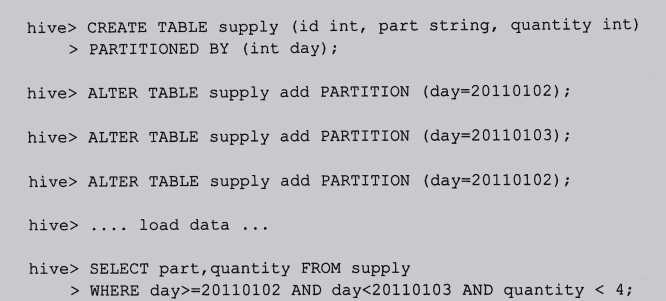
二、关于分区
Hive中分区的功能非常有用的。这是因为Hive通常要对输入进行全盘扫描,来满足查询条件。通过创建很多分区确实可以优化一些铲鲟,但是同时可能会对其他一些重要的查询不利:

HDFS用于设计存储数百万的大文件,而非数十亿的小文件。使用过多分区可能导致的一个问题就是创建大量的非必须的Hadoop文件和文件夹。一个分区就对应着一个包含多个文件的文件夹。如果指定的表存在数百个分区吗,那么可能每天都会创建好几万个文件。如果保持这样的表很多年,那么最终就会超出NameNode对系统云数据信息的
标签:nod 存在 表达 hadoop hive 文件 其他 通过 dfs
原文地址:https://www.cnblogs.com/xibuhaohao/p/11847930.html