标签:imp uniq 信息 通过 jit center pat start style
参考:https://www.machinelearningplus.com/plots/top-50-matplotlib-visualizations-the-master-plots-python/
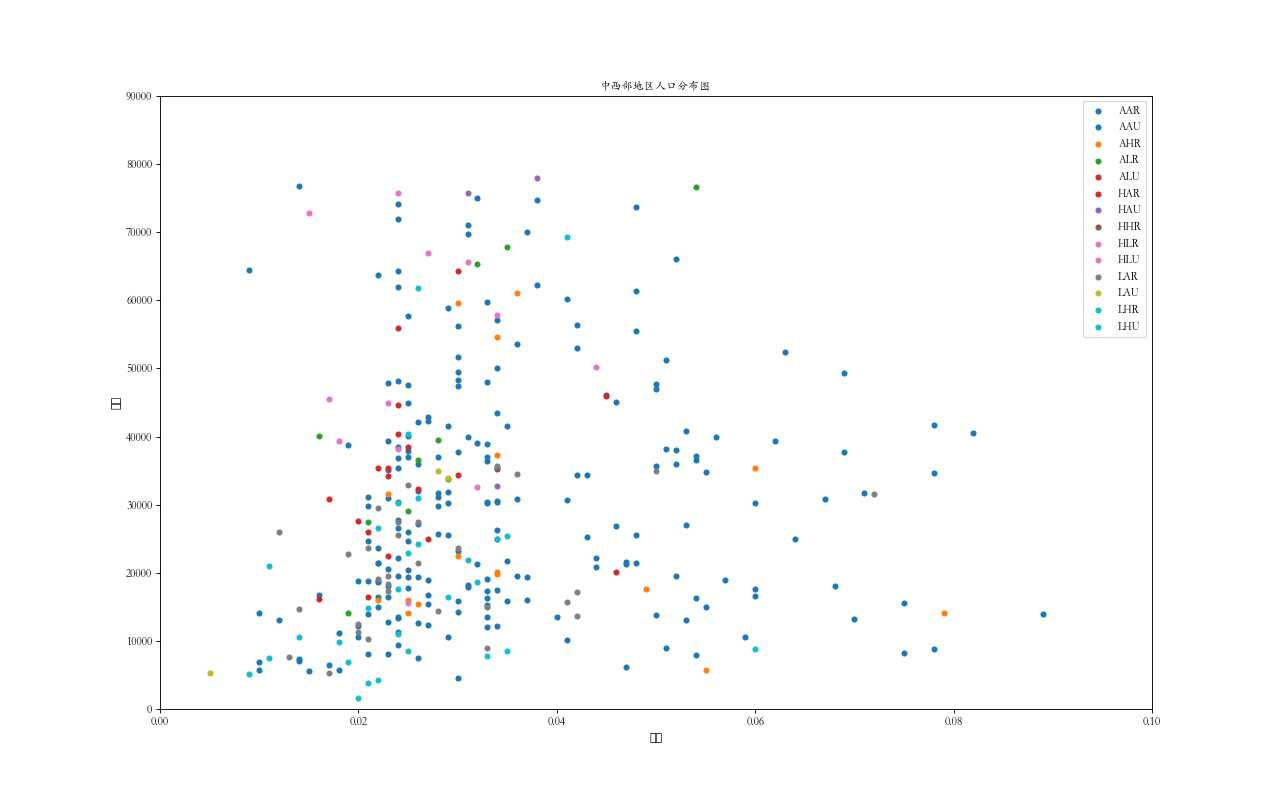
Scatteplot 是用于研究两个变量之间关系的经典和基本图。如果数据中有多个组,则可能需要以不同颜色可视化每个组。在Matplotlib,你可以方便地使用。
# Import dataset %matplotlib import pandas as pd import numpy as np import matplotlib as mpl from matplotlib import patches from matplotlib import font_manager as fm from matplotlib import pyplot as plt from scipy.spatial import ConvexHull import seaborn as sns import warnings; warnings.simplefilter(‘ignore‘) midwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv") zhongwen_font = fm.FontProperties(fname=‘C:\Windows\Fonts\华文楷体.ttf‘) # Step 1: 准备数据 # 创建尽可能多的颜色,因为有独特的midwest[‘category‘] categories = np.unique(midwest[‘category‘]) colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))] # Step 2:为每个类别绘制图形 plt.figure(figsize=(16, 10), dpi= 80, facecolor=‘w‘, edgecolor=‘k‘) for i, category in enumerate(categories): plt.scatter(‘area‘, ‘poptotal‘, data=midwest.loc[midwest.category==category, :], s=20, c=colors[i], label=str(category)) # Step 3:展示优化:设置图例等 plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000), xlabel=‘地区‘, ylabel=‘人口‘) plt.xticks(fontsize=12, fontproperties = zhongwen_font) plt.yticks(fontsize=12, fontproperties = zhongwen_font) plt.title("中西部地区人口分布图", fontsize=22, fontproperties = zhongwen_font) plt.legend(fontsize=12, prop = zhongwen_font) plt.show()
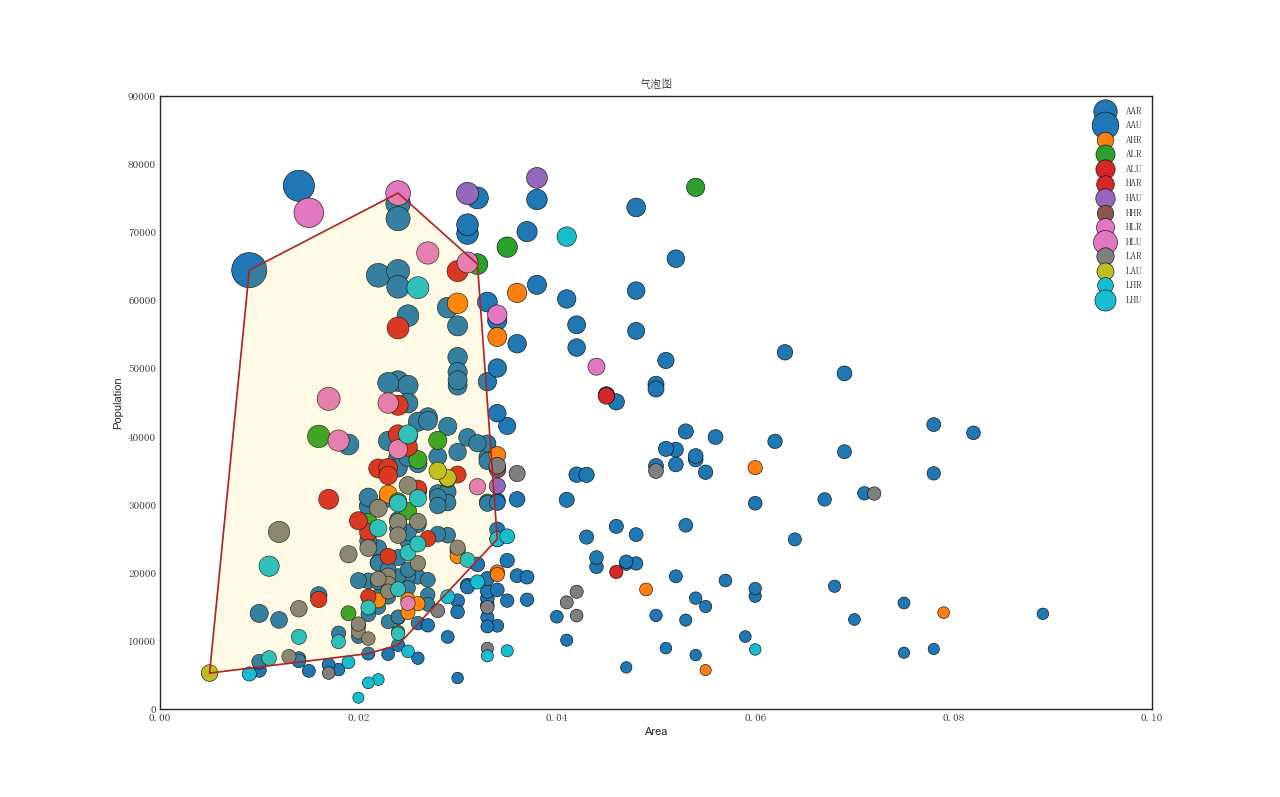
有时,您希望在边界内显示一组点以强调其重要性。在此示例中,您将从应该被环绕的数据帧中获取记录,并将其传递给下面的代码中描述的记录。encircle()
%matplotlib import pandas as pd import numpy as np import matplotlib as mpl from matplotlib import patches from matplotlib import font_manager as fm from matplotlib import pyplot as plt from scipy.spatial import ConvexHull from matplotlib import patches import seaborn as sns import warnings; warnings.simplefilter(‘ignore‘) sns.set_style("white") # S1: 准备数据 midwest = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/midwest_filter.csv") zhongwen_font = fm.FontProperties(fname=‘C:\Windows\Fonts\simsun.ttc‘) # 创建尽可能多的颜色,因为有独特的midwest[‘category‘]y‘] categories = np.unique(midwest[‘category‘]) colors = [plt.cm.tab10(i/float(len(categories)-1)) for i in range(len(categories))] # S2: 为每个类别绘制图形 fig = plt.figure(figsize=(16, 10), dpi= 80, facecolor=‘w‘, edgecolor=‘k‘) for i, category in enumerate(categories): plt.scatter(‘area‘, ‘poptotal‘, data=midwest.loc[midwest.category==category, :], s=‘dot_size‘, c=colors[i], label=str(category), edgecolors=‘black‘, linewidths=.5) # S3: 边界 # https://stackoverflow.com/questions/44575681/how-do-i-encircle-different-data-sets-in-scatter-plot def encircle(x,y, ax=None, **kw): if not ax: ax=plt.gca() p = np.c_[x,y] hull = ConvexHull(p) poly = plt.Polygon(p[hull.vertices,:], **kw) ax.add_patch(poly) # 选择要包围的数据 midwest_encircle_data = midwest.loc[midwest.state==‘IN‘, :] # 围绕顶点绘图 encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="k", fc="gold", alpha=0.1) encircle(midwest_encircle_data.area, midwest_encircle_data.poptotal, ec="firebrick", fc="none", linewidth=1.5) # S4: 优化图例 plt.gca().set(xlim=(0.0, 0.1), ylim=(0, 90000), xlabel=‘Area‘, ylabel=‘Population‘) plt.xticks(fontsize=12, fontproperties = zhongwen_font) plt.yticks(fontsize=12, fontproperties = zhongwen_font) plt.title("气泡图", fontsize=22, fontproperties = zhongwen_font) plt.legend(fontsize=12, prop = zhongwen_font) plt.show()
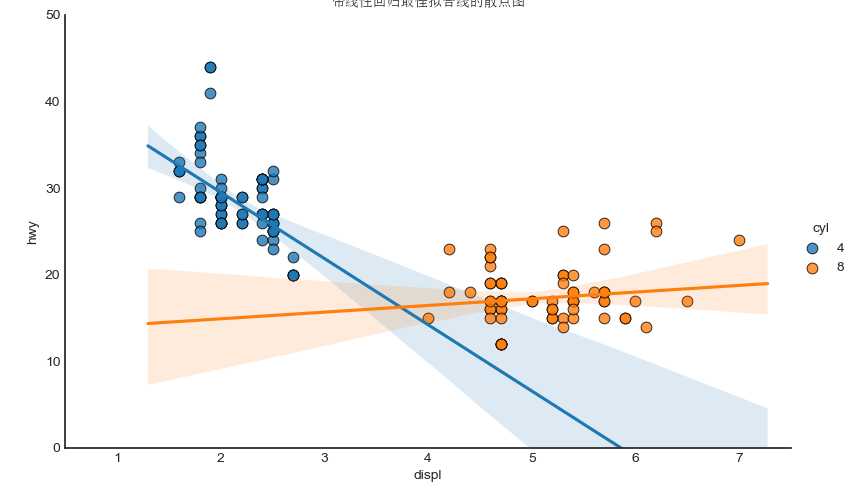
如果你想了解两个变量如何相互改变,那么最合适的线就是要走的路。下图显示了数据中各组之间最佳拟合线的差异。要禁用分组并仅为整个数据集绘制一条最佳拟合线,请从下面的调用中删除该参数。
# Import dataset %matplotlib import pandas as pd import numpy as np import matplotlib as mpl from matplotlib import patches from matplotlib import font_manager as fm from matplotlib import pyplot as plt from scipy.spatial import ConvexHull import seaborn as sns import warnings; warnings.simplefilter(‘ignore‘) # S1 : 数据 df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv") zhongwen_font = fm.FontProperties(fname=‘C:\Windows\Fonts\simsun.ttc‘) df_select = df.loc[df.cyl.isin([4,8]), :] # S2 : 作图 sns.set_style("white") gridobj = sns.lmplot(x="displ", y="hwy", hue="cyl", data=df_select, aspect=1.6, robust=True, palette=‘tab10‘, scatter_kws=dict(s=60, linewidths=.7, edgecolors=‘black‘)) # S3 :优化 gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50)) plt.title("带线性回归最佳拟合线的散点图", fontsize=20, fontproperties = zhongwen_font) plt.show()
或者,您可以在其自己的列中显示每个组的最佳拟合线。你可以通过在里面设置参数来实现这一点。
# Import Data df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv") df_select = df.loc[df.cyl.isin([4,8]), :] # Each line in its own column sns.set_style("white") gridobj = sns.lmplot(x="displ", y="hwy", data=df_select, height=7, robust=True, palette=‘Set1‘, col="cyl", scatter_kws=dict(s=60, linewidths=.7, edgecolors=‘black‘)) # Decorations gridobj.set(xlim=(0.5, 7.5), ylim=(0, 50)) plt.show()
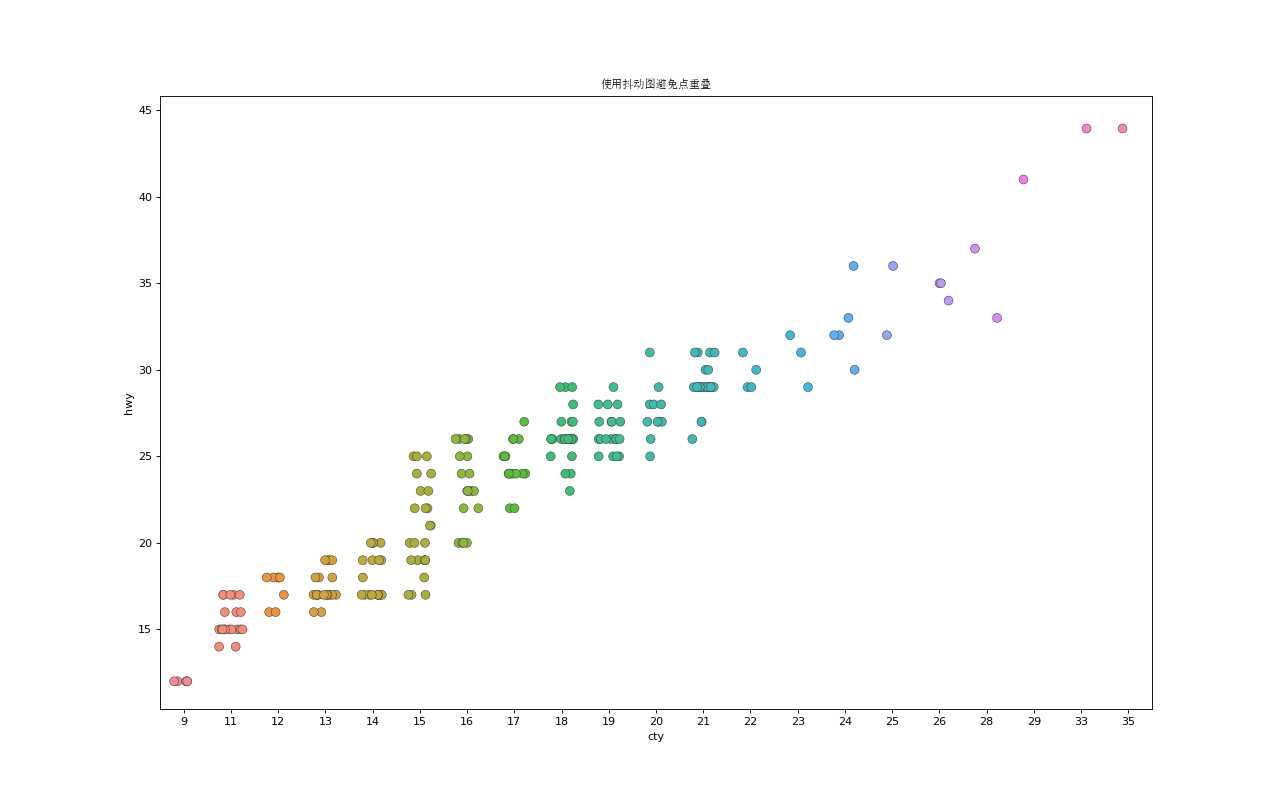
通常,多个数据点具有完全相同的X和Y值。结果,多个点相互绘制并隐藏。为避免这种情况,请稍微抖动点,以便您可以直观地看到它们。这很方便使用
%matplotlib import pandas as pd import numpy as np import matplotlib as mpl from matplotlib import patches from matplotlib import font_manager as fm from matplotlib import pyplot as plt from scipy.spatial import ConvexHull from matplotlib import patches import seaborn as sns import warnings; warnings.simplefilter(‘ignore‘) # S1:数据 df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/mpg_ggplot2.csv") zhongwen_font = fm.FontProperties(fname=‘C:\Windows\Fonts\simsun.ttc‘) # S2:作图 fig, ax = plt.subplots(figsize=(16,10), dpi= 80) sns.stripplot(df.cty, df.hwy, jitter=0.25, size=8, ax=ax, linewidth=.5) # S3:优化 plt.title(‘使用抖动图避免点重叠‘, fontsize=22, fontproperties = zhongwen_font) plt.show()
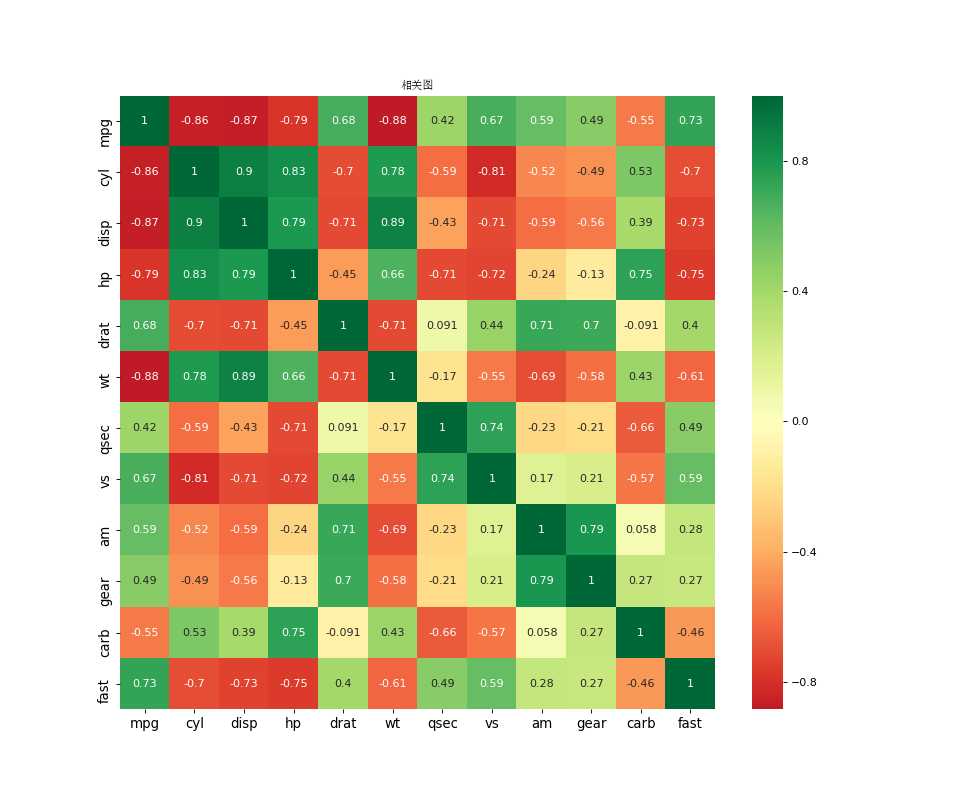
Correlogram用于直观地查看给定数据帧(或2D数组)中所有可能的数值变量对之间的相关度量。
%matplotlib import pandas as pd import numpy as np import matplotlib as mpl from matplotlib import patches from matplotlib import font_manager as fm from matplotlib import pyplot as plt from scipy.spatial import ConvexHull from matplotlib import patches import seaborn as sns import warnings; warnings.simplefilter(‘ignore‘) # S1: 数据 df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv") zhongwen_font = fm.FontProperties(fname=‘C:\Windows\Fonts\simsun.ttc‘) # S2: plot 作图 plt.figure(figsize=(12,10), dpi= 80) sns.heatmap(df.corr(), xticklabels=df.corr().columns, yticklabels=df.corr().columns, cmap=‘RdYlGn‘, center=0, annot=True) # S3: 图例优化 plt.title(‘相关图‘, fontsize=22, fontproperties = zhongwen_font) plt.xticks(fontsize=12) plt.yticks(fontsize=12) plt.show()
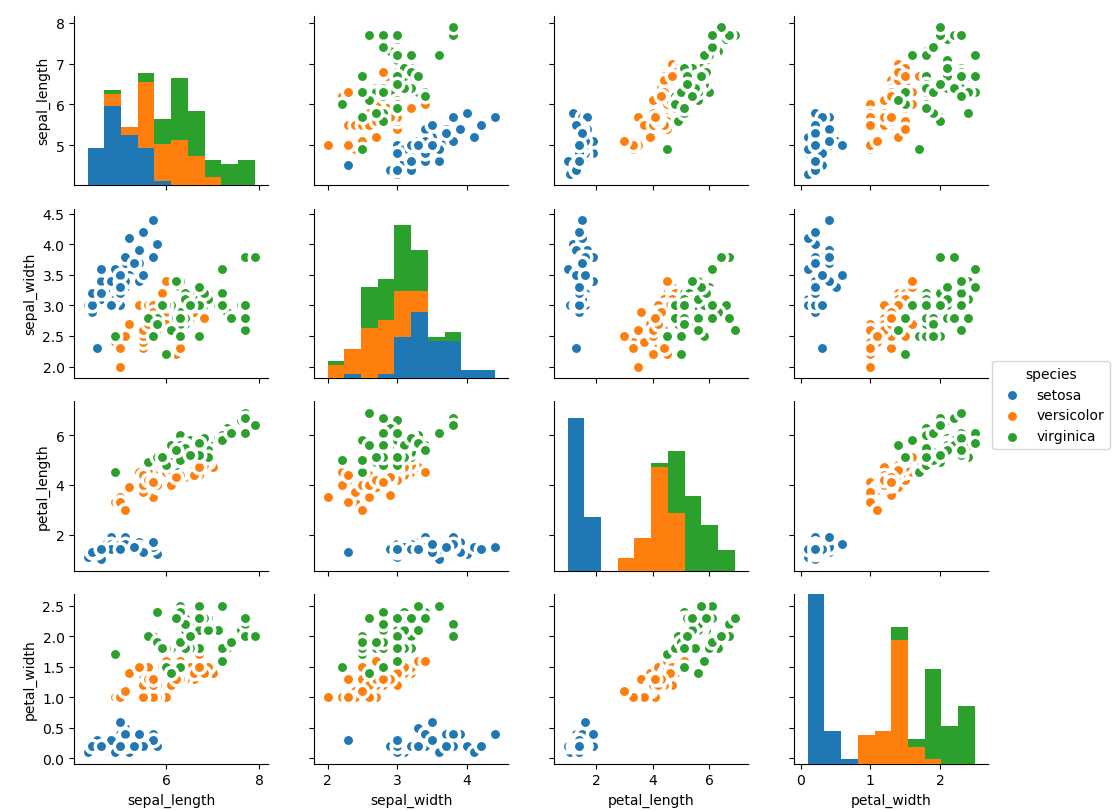
成对图是探索性分析中的最爱,以理解所有可能的数字变量对之间的关系。它是双变量分析的必备工具。
%matplotlib import pandas as pd import numpy as np import matplotlib as mpl from matplotlib import patches from matplotlib import font_manager as fm from matplotlib import pyplot as plt from scipy.spatial import ConvexHull from matplotlib import patches import seaborn as sns import warnings; warnings.simplefilter(‘ignore‘) # Load Dataset df = sns.load_dataset(‘iris‘) # Plot plt.figure(figsize=(10,8), dpi= 80) sns.pairplot(df, kind="scatter", hue="species", plot_kws=dict(s=80, edgecolor="white", linewidth=2.5)) plt.show()
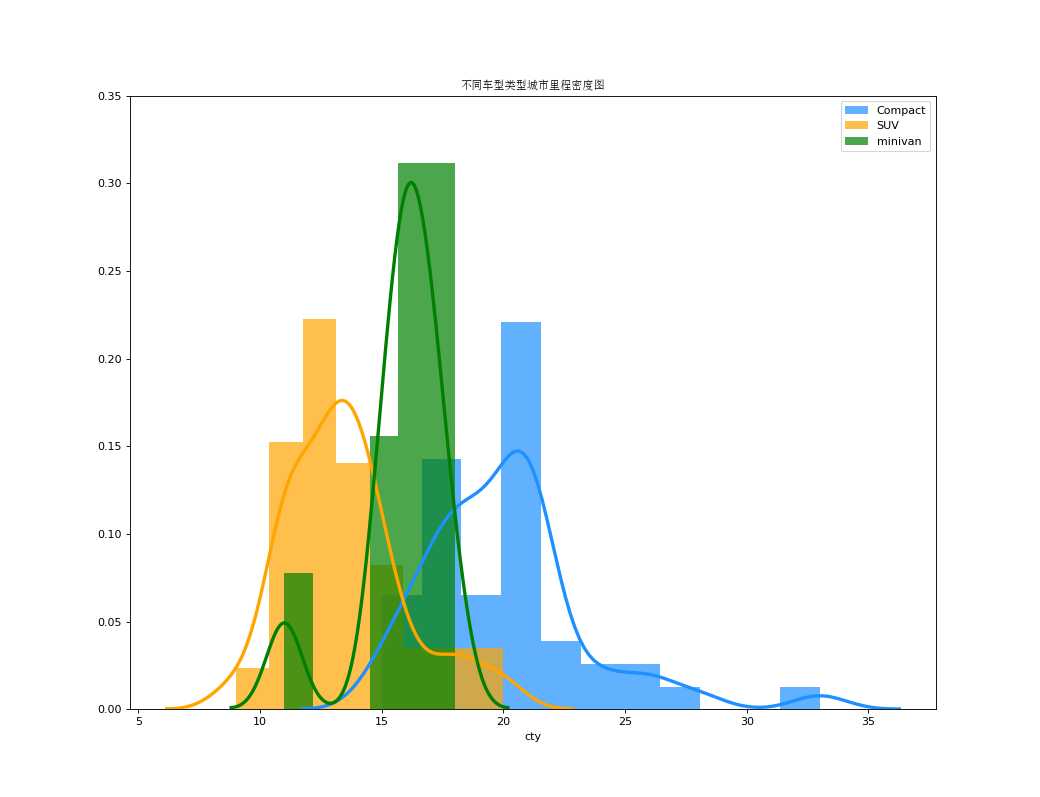
带有直方图的密度曲线将两个图表传达的集体信息汇集在一起,这样您就可以将它们放在一个图形而不是两个图形中。
%matplotlib import pandas as pd import numpy as np import matplotlib as mpl from matplotlib import patches from matplotlib import font_manager as fm from matplotlib import pyplot as plt from scipy.spatial import ConvexHull from matplotlib import patches import seaborn as sns import warnings; warnings.simplefilter(‘ignore‘) # S1:数据 df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv") zhongwen_font = fm.FontProperties(fname=‘C:\Windows\Fonts\simsun.ttc‘) # S2:作图 plt.figure(figsize=(13,10), dpi= 80) sns.distplot(df.loc[df[‘class‘] == ‘compact‘, "cty"], color="dodgerblue", label="Compact", hist_kws={‘alpha‘:.7}, kde_kws={‘linewidth‘:3}) sns.distplot(df.loc[df[‘class‘] == ‘suv‘, "cty"], color="orange", label="SUV", hist_kws={‘alpha‘:.7}, kde_kws={‘linewidth‘:3}) sns.distplot(df.loc[df[‘class‘] == ‘minivan‘, "cty"], color="g", label="minivan", hist_kws={‘alpha‘:.7}, kde_kws={‘linewidth‘:3}) plt.ylim(0, 0.35) # S3:图例 plt.title(‘不同车型类型城市里程密度图‘, fontsize=22, fontproperties = zhongwen_font) plt.legend() plt.show()
与时间序列相比,日历映射是可视化基于时间的数据的备选和不太优选的选项。虽然可以在视觉上吸引人,但数值并不十分明显。然而,它可以很好地描绘极端值和假日效果。
import matplotlib as mpl import calmap as calmap # S1:数据 df = pd.read_csv("https://raw.githubusercontent.com/selva86/datasets/master/yahoo.csv", parse_dates=[‘date‘]) df.set_index(‘date‘, inplace=True) # S2:绘图 plt.figure(figsize=(16,10), dpi= 80) calmap.calendarplot(df[‘2014‘][‘VIX.Close‘], fig_kws={‘figsize‘: (16,10)}, yearlabel_kws={‘color‘:‘black‘, ‘fontsize‘:14}, subplot_kws={‘title‘:‘Yahoo Stock Prices‘}) plt.show()

by : 一只阿木木
标签:imp uniq 信息 通过 jit center pat start style
原文地址:https://www.cnblogs.com/yizhiamumu/p/11850019.html