标签:ESS get color == 线程安全 amp tab load 链表
HashMap,基于哈希结构的Map接口的一个实现,无序,允许null键值对,线程不安全的。可以使用集合工具类Collections中的synchronizedMap方法,去创建一个线程安全的集合map。
在jdk1.7中,HashMap主要是基于 数组+链表 的结构实现的。链表的存在主要是解决 hash 冲突而存在的。插入数据的时候,计算key的hash值,取得存储的数组下标,如果冲突已有元素,则会在冲突地址上生成个链表,再通过key的比较,链表是否已存在,存在则覆盖,不存在则链表上添加。这种方式,如果存在大量冲突的时候,会导致链表过长,那么直接导致的就是牺牲了查询和添加的效率。所以在jdk1.8版本之后,使用的就是 数组 + 链表 + 红黑树,当链表长度超过 8(实际加上初始的节点,整个有效长度是 9) 的时候,转为红黑树存储。
本文中内容,主要基于jdk1.7版本,单线程环境下使用的HahsMap没有啥问题,但是当在多线程下使用的时候,则可能会出现并发异常,具体表象是CPU会直线上升100%。下面是主要介绍相关的存取以及为什么会出现线程安全性问题。
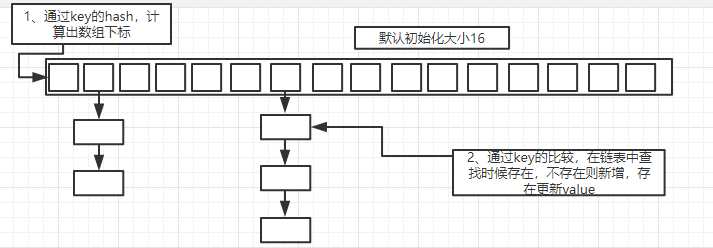
HashMap默认初始化size=16的哈希数组,然后通过计算待存储的key的hash值,去计算得到哈希数组的下标值,然后放入链表中(新增节点或更新)。链表的存在即是解决hash冲突的。
1、存储具体数据的table数组:
Entry为HashMap中的静态内部类,其具体结构如下图
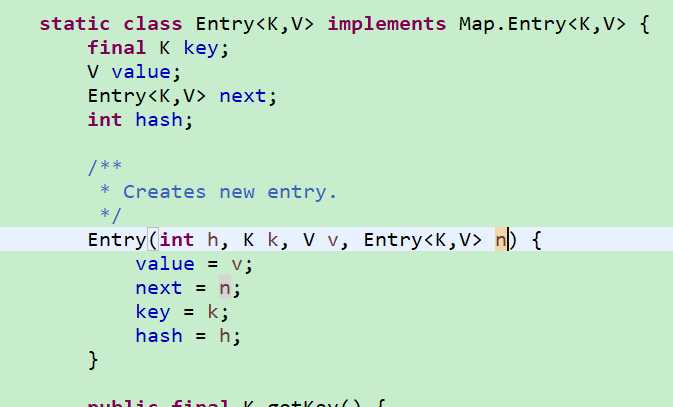
key、value属性就是存储键值对的,next则是指向链表的下一个元素节点。
2、 默认初始化方法:
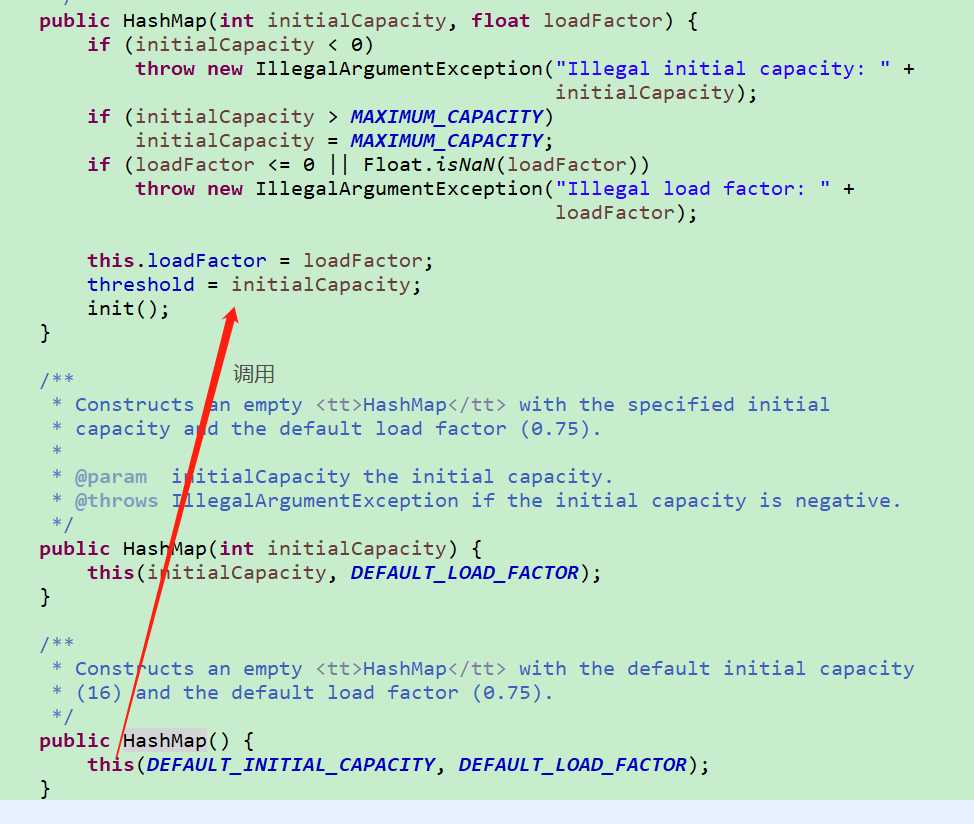
默认构造方法,不对table进行初始化new(真正初始化动作放在put中,后面会看到),只是设置参数的默认值,hashmap长度和table长度初始化成DEFAULT_INITIAL_CAPACITY(16),加载因子loadFactor默认DEFAULT_LOAD_FACTOR(0.75f,至于为什么是0.75,这个可以参见 https://stackoverflow.com/questions/10901752/what-is-the-significance-of-load-factor-in-hashmap)。
加载因子:默认情况下,16*0.75=12,也就是在存储第13个元素的时候,就会进行扩容(jdk1.7的threshold真正计算放在第一次初始化中,后面会再提及)。此元素的设置,直接影响到的是key的hash冲突问题。
3、put方法
public V put(K key, V value) {
if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }
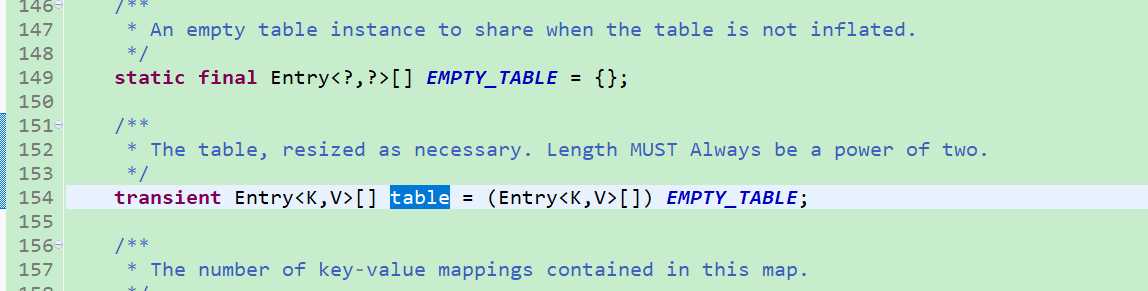
3.1、EMPTY_TABLE是HashMap中的一个静态的空的Entry数组,table也是HashMap的一个属性,默认就是EMPTY_TABLE(这两句可参见上面源码),table就是我们真正数据存储使用的。
3.2、前面提及,无参构造的时候,并未真正完成对HashMap的初始化new操作,而仅仅只是设置几个常量,所以在第一次put数据的时候,table是空的。则会进入下面的初始化table方法中。
if (table == EMPTY_TABLE) { inflateTable(threshold); } private void inflateTable(int toSize) { // Find a power of 2 >= toSize int capacity = roundUpToPowerOf2(toSize); threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); //计算加载因子,默认情况下结果为12 table = new Entry[capacity]; //真正的初始化table数组 initHashSeedAsNeeded(capacity); }
3.3、key的null判断
if (key == null) return putForNullKey(value); private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; } void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); } void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
具体步骤解析:
1、key为null,取出table[0]的链表结构Enrty,如果取出的元素不为null,则对其进行循环遍历,查找其中是否存在key为null的节点元素。
2、如果存在key == null的节点,则使用新的value去更新节点的oldValue,并且将oldValue返回。
3、如果不存在key == null的元素,则执行新增元素addEntry方法:
(1)判断是否需要扩容,size为当前数组table中,已存放的Entry链表个数,更直接点说,就是map.size()方法的返回值。threshold上面的真正初始化HashMap的时候已经提到,默认情况下,计算得到 threshold=12。若同时满足 (size >= threshold) && (null != table[bucketIndex]) ,则对map进行2倍的扩容,然后对key进行重新计算hash值和新的数组下标。
(2)创建新的节点原色createEntry方法,首先获取table数组中下标为bucketIndex的链表的表头元素,然后新建个Entry作为新的表头,并且新表头其中的next指向老的表头数据。
3.4、key不为null的存储
原理以及过程上通key==null的大体相同,只不过,key==null的时候,固定是获取table[0]的链表进行操作,而在不为key != null的时候,下标位置是通过
int hash = hash(key); int i = indexFor(hash, table.length); 计算得到的
static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
很清晰的就能看明白,先计算key的hash,然后与当前table的长度进行相与,这样计算得到待存放数据的下标。得到下标后,过程就与key==null一致了,遍历是否存在,存在则更新并返回oldVlaue,不存在则新建Entry。
4、get方法
public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
如果key == null,则调用getForNullKey方法,遍历table[0]处的链表。
private V getForNullKey() { if (size == 0) { return null; } for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }
如果key != null,则调用getEntry,根据key计算得到在table数组中的下标,获取链表Entry,然后遍历查找元素,key相等,则返回该节点元素。
final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
上述,主要浅析了下HashMap的存取过程,HashMap的线程安全性问题主要也就是在上述的扩容resize方法上,下面来看看在高并发下,扩容后,是如何引起100%问题的。
1、在进行新元素 put 的时候,这在上面中的3.3的代码片段中可以查看,addEntry 添加新节点的时候,会计算是否需要扩容处理:(size >= threshold) && (null != table[bucketIndex]) 。
2、如果扩容的话,会接下来调用 resize 方法
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; //关键性代码,构建新hashmap并将老的数据移动过来 transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
3、其中,出现100%问题的关键就是上面的 transfer 方法,新建hashmap移动复制老数据
1 void transfer(Entry[] newTable, boolean rehash) { 2 int newCapacity = newTable.length; 3 for (Entry<K,V> e : table) { 4 // 遍历老的HashMap,当遇到不为空的节点的是,进入移动方法 5 while(null != e) { 6 // 首先创建个Entry节点 指向该节点所在链表的下一个节点数据 7 Entry<K,V> next = e.next; 8 if (rehash) { 9 e.hash = null == e.key ? 0 : hash(e.key); 10 } 11 // 计算老的数据在新Hashmap中的下标位置 12 int i = indexFor(e.hash, newCapacity); 13 // 将新HashMap中相应位置的元素,挂载到老数据的后面(不管有无数据) 14 e.next = newTable[i]; 15 // 将新HashMap中相应位置指向上面已经成功挂载新数据的老数据 16 newTable[i] = e; 17 // 移动到链表节点中的下一个数据,继续复制节点 18 e = next; 19 } 20 } 21 }
问题的关键就在上述的14、15行上,这两行的动作,在高并发下可能就会造成循环链表,循环链表在等待下一个尝试 get 获取数据的时候,就悲剧了。下面举例模拟说说这个过程:
(1)假设目前某个位置的链表存储结构为 A -> B -> C,有两个线程同时进行扩容操作
(2)线程1执行到第7行 Entry<K,V> next = e.next; 的时候被挂起了,此时,线程1的 e 指向 A , next 指向的是 B
(3)线程2执行完成了整个的扩容过程,那么此时的链表结构应该是变为了 C -> B -> A
(4)线程1唤醒继续执行,而需要操作的链表实际就变成了了上述线程2完成后的 C ->B -> A,下面分为几步去完成整个操作:
第一次循环:
(i)执行 e.next = newTable[i] ,将 A 的 next 指向线程1的新的HashMap,由于此时无数据,所以 e.next = null
(ii)执行 newTable[i] = e,将线程1的新的HashMap的第一个元素指向 A
(iii)执行e = next,移动到链表中的下一个元素,也就是上面的(2)中的 线程挂起的时候的 B
第二次循环:
(i)执行 Entry<K,V> next = e.next,此时的 e 指向 B,next指向 A
(ii)执行 e.next = newTable[i] ,将 B 的 next 指向线程1的新的HashMap,由于此时有数据A,所以 e.next = A
(iii)执行 newTable[i] = e,将线程1的新的HashMap的第一个元素指向 B,此时线程1的新Hashmap链表结构为B -> A
(iiii)执行e = next,移动到链表中的下一个元素 A
第三次循环:
(i)执行 Entry<K,V> next = e.next,此时的 e 指向 A,next指向 null
(ii)执行 e.next = newTable[i] ,将 A 的 next 指向线程1的新的HashMap,由于此时有数据B,所以 e.next = B
(iii)执行 newTable[i] = e,将线程1的新的HashMap的第一个元素指向 A ,此时线程1的新Hashmap链表结构为 A -> B -> A
(iiii)执行e = next,移动到链表中的下一个元素,已移动到链表结尾,结束 while 循环,完成链表的转移。
(5)上述过程中,很显然的,最终的链表结构中,出现了 A -> B -> A 的循环结构。扩容完成了,剩下的等待的是get获取的时候, getEntry 方法中 for循环e = e.next中就永远出不来了。
注意:扩容过程中,newTable是每个扩容线程独有的,共享的只是每个Entry节点数据,最终的扩容是会调用 table = newTable 赋值操作完成。
标签:ESS get color == 线程安全 amp tab load 链表
原文地址:https://www.cnblogs.com/eric-fang/p/10283154.html