标签:ast for class hdfs 于平 忽略 性能 流程 text
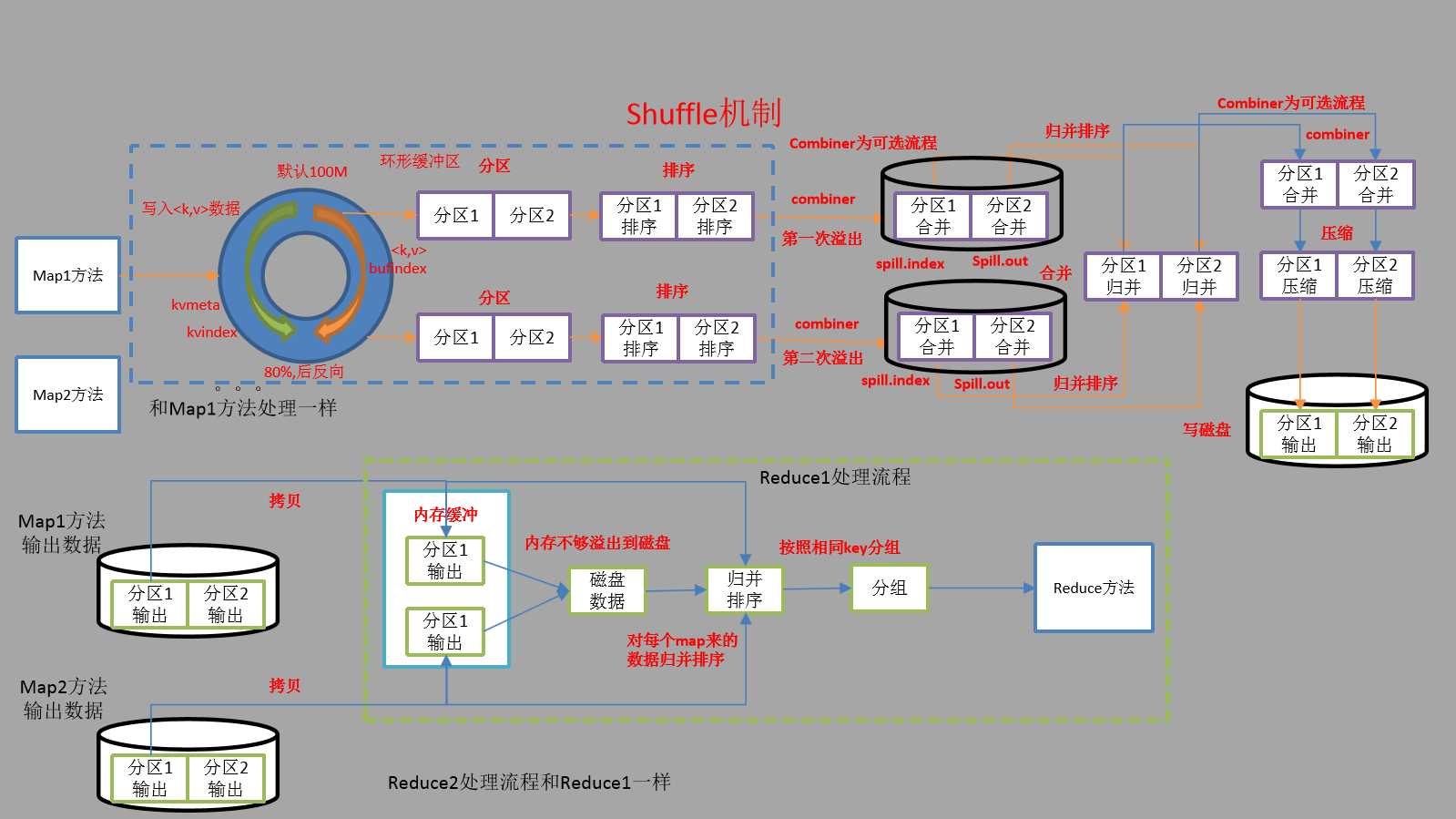
第一阶段map 1.map task读取HDFS文件。每个block,启动一个map task。 每个map task按照行读取一个block中的内容,对每一行执行map函数 2.map函数对输入的数据进行拆分split,得到一个数组,组成一个键值对<word, 1> 3.[忽略]分1个区,对应1个reduce task 4.[忽略]对每个分区中的数据,按照key进行分组并排序 5.[忽略]在map段执行小reduce,输出<key,times> 第二阶段reduce 1.每个分区对应一个reduce task,这个reduce task会读取相同分区的map输出; reduce task对接收到的所有map输出,进行排序分组 <hello,{1,1}><me,{1}><you,{1}> 2.执行reduce 操作,对一个分组中的value进行累加 <hello,2><me,1><you,1> 3.每个分区输出到一个HDFS文件中
原因: 简单来说数据倾斜就是数据的key 的分化严重不均,造成一部分数据很多,一部分数据很少的局面。 情形:group by 维度过小,某值的数量过多 后果:处理某值的reduce非常耗时 去重 distinct count(distinct xx) 情形:某特殊值过多 后果:处理此特殊值的reduce耗时 连接 join 情形1:其中一个表较小,但是key集中 后果1:分发到某一个或几个Reduce上的数据远高于平均值 情形2:大表与大表,但是分桶的判断字段0值或空值过多 后果2:这些空值都由一个reduce处理,非常慢 解决: 调优参数 set hive.map.aggr=true; set hive.groupby.skewindata=true; hive.map.aggr=true:在map中会做部分聚集操作,效率更高但需要更多的内存。 hive.groupby.skewindata=true:数据倾斜时负载均衡,当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。 2、在 key 上面做文章,在 map 阶段将造成倾斜的key 先分成多组,例如 aaa 这个 key,map 时随机在 aaa 后面加上 1,2,3,4 这四个数字之一,把 key 先分成四组,先进行一次运算,之后再恢复 key 进行最终运算。 3、能先进行 group 操作的时候先进行 group 操作,把 key 先进行一次 reduce,之后再进行 count 或者 distinct count 操作。 4、join 操作中,使用 map join 在 map 端就先进行 join ,免得到reduce 时卡住。
1.紧凑 紧凑的格式能让我们充分利用网络带宽,而带宽是数据中心最稀缺的资源 2.快速 进程通信形成了分布式系统的骨架,所以需要尽量减少序列化和反序列化的性能开销,这是基本的; 3.可扩展 协议为了满足新的需求变化,所以控制客户端和服务器过程中,需要直接引进相应的协议,这些是新协议,原序列化方式能支持新的协议报文; 4.互操作 能支持不同语言写的客户端和服务端进行交互;
MRAppMaster向RM申请2个container;
RM分配2个container,
NM启动该container,把container的地址返回给master。
container中开始运行map task或者reduce task。
在运行过程中,master与map task、reduce task保持心跳通讯,监测task的执行情况。
当map task和reduce task运行结束时,回收container。
当job运行结束时,master告诉RM,可以把自己回收了。
RM就让NM杀死master所在的container。
整个job运行完毕
一个split的大小是由goalSize, minSize, blockSize这三个值决定的。
computeSplitSize的逻辑是,先从goalSize和blockSize两个值中选出最小的那个(比如一般不设置map数,这时blockSize为当前文件的块size,而goalSize是文件大小除以用户设置的map数得到的,如果没设置的话,默认是1)。
// 如果不设置InputFormat,它默认用的是TextInputFormat.class job.setInputFormatClass(CombineTextInputFormat.class); CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m CombineTextInputFormat.setMinInputSplitSize(job, 2097152);// 2m
bean对象实现WritableComparable接口重写compareTo方法,就可以实现排序 @Override public int compareTo(FlowBean o) { // 倒序排列,从大到小 return this.sumFlow > o.getSumFlow() ? -1 : 1; if(this.sumFlow==o.getSumFlow()){ This.downFlow>o.getDownFlow() ? -1 :1 } }
(1)自定义类继承Partitioner,重写getPartition()方法 public class ProvincePartitioner extends Partitioner<Text, FlowBean> { @Override public int getPartition(Text key, FlowBean value, int numPartitions) { // 1 获取电话号码的前三位 String preNum = key.toString().substring(0, 3); int partition = 4; // 2 判断是哪个省 if ("136".equals(preNum)) { partition = 0; }else if ("137".equals(preNum)) { partition = 1; }else if ("138".equals(preNum)) { partition = 2; }else if ("139".equals(preNum)) { partition = 3; } return partition; } }
(2)在job驱动中,设置自定义partitioner: job.setPartitionerClass(CustomPartitioner.class); (3)自定义partition后,要根据自定义partitioner的逻辑设置相应数量的reduce task job.setNumReduceTasks(5);
标签:ast for class hdfs 于平 忽略 性能 流程 text
原文地址:https://www.cnblogs.com/lovemeng1314/p/11872221.html