标签:算法复杂度 产品 url image cal log mda 核心 tps
word2vec作为神经概率语言模型的输入,其本身其实是神经概率模型的副产品,是为了通过神经网络学习某个语言模型而产生的中间结果。具体来说,“某个语言模型”指的是“CBOW”和“Skip-gram”。具体学习过程会用到两个降低复杂度的近似方法——Hierarchical Softmax或Negative Sampling。两个模型乘以两种方法,一共有四种实现。
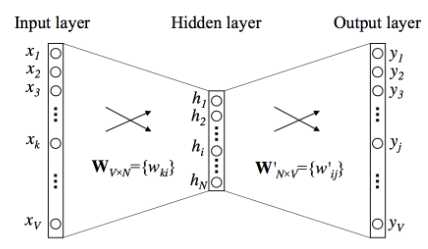
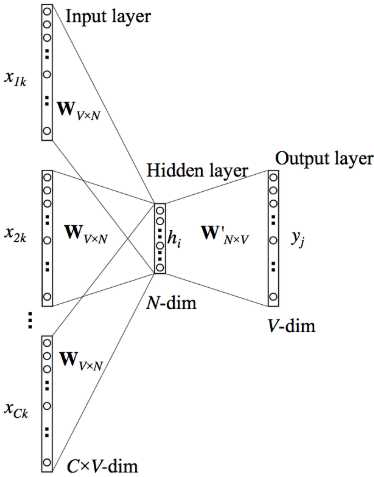
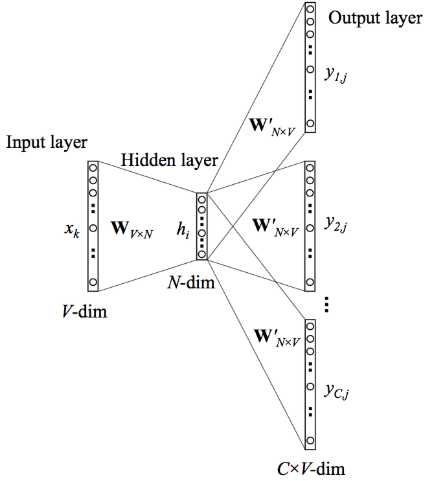
原始的CBOW模型和Skip-Gram 模型的计算量太大,非常难以计算。
虽然输入向量的维度也很高,但是由于输入向量只有一位为 1,其它位均为 0,因此输入的总体计算复杂度较小。
word2vec 优化的主要思想是:限制输出单元的数量。
事实上在上百万的输出单元中,仅有少量的输出单元对于参数更新比较重要,大部分的输出单元对于参数更新没有贡献。
有两种优化策略:
分层 softmax 是一种高效计算 softmax 函数的算法。 经过分层 softmax 之后,计算 softmax 函数的算法复杂度从O(V)降低到O(logV) ,但是仍然要计算V-1个内部节点的向量表达 。
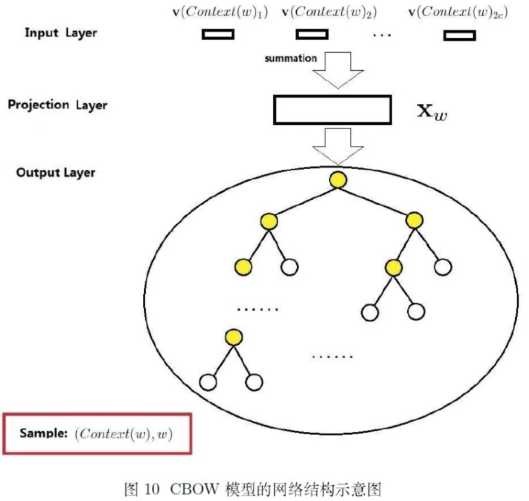
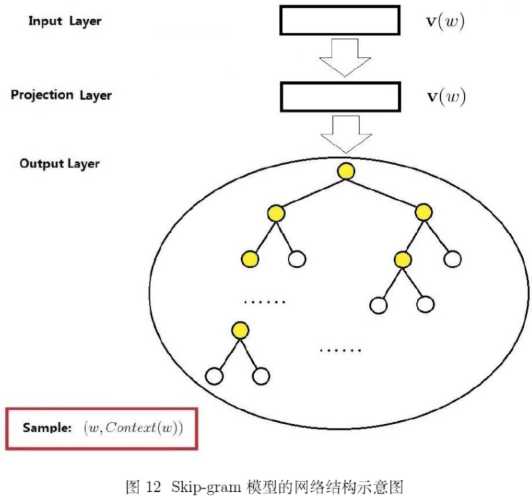
在网络的输出层,真实的输出单词对应的输出单元作为正向单元,其它所有单词对应的输出单元为负向单元。
负采样的核心思想是:利用负采样后的输出分布来模拟真实的输出分布。
参考链接:
【1】word2vec原理(一) CBOW与Skip-Gram模型基础
【3】Hierarchical Softmax(层次Softmax) - 知乎
标签:算法复杂度 产品 url image cal log mda 核心 tps
原文地址:https://www.cnblogs.com/nxf-rabbit75/p/11875847.html