标签:融合 就是 形状 自适应 shape 约束 sha https 图像
想到什么写什么。
2D图像是网格数据,对于3D检测(3d location + 3d size + orientation)任务非常不友好,虽然可以通过添加几何约束(比如PnP定位?)来得到3D box,比如在CVPR 2019 Xiaozhi Chen提出的Stereo R-CNN,但准确率和基于Lidar数据的相比仍然存在巨大的gap。
为了融合RGB数据(2D网格,WxHx3矩阵)和Lidar的点云数据(Nx3矩阵),最简单的方法是把Lidar投影成为深度图,进行简单的concatenate,得到WxHx4的网格。
这是有用的,我也看过有人在研究深度图的后处理,比如我看的第一篇论文就是说,KITTI投影后的深度图很稀疏(一个图片大概有100k个点),所以可以进行一个双边滤波的操作,使得深度变得稠密,再和RGB图进行concatenate,这样对最后的分类准确率会有提升(小声BB一句,这样做应该会严重降低3D box的回归准确率,原因见下文)。但是这种基于网格/平面/前视图方法有两个主要缺陷:第一是从特征表示上说的,RGBD的前视图不利于处理遮挡问题,比如两个行人靠得很近,特征就很容易混在一起,检测时也会存在困难,因为回归的两个人的中心点/边界框靠得太近;相比之下,点云表示,或者鸟瞰图表示(CVPR17 MV3D, 以及AVOD),又或者体素表示(CVPR18 VoxelNet, 以及Second),两个靠的很近的人在这些表示下都是分开的。第二是从CNN学到的特征来说的。CNN在RGB图像上能学到边缘、纹理特征,1x1Conv(MLP)在Nx3点云上能学到形状特征(参考CVPR17,PointNet,虽然还没看过可视化的研究,但姑且认为学到的是形状特征)。然而,我很怀疑CNN在深度图上也可能只是学到边缘、纹理特征。当然,深度图上的边缘意味着深度不同,所以也不能说它没用,只不过没有点云有用。而且,在CVPR2019 pseudo-Lidar 文章中指出,深度图在经过box-filter(11x11卷积)后虽然从前视图看起来差不多,但点云的形状已经被扭曲了。(跟那种对图像加点噪音,人眼看不出,但其实对特征影响很大,导致分类错误的想法很像。)
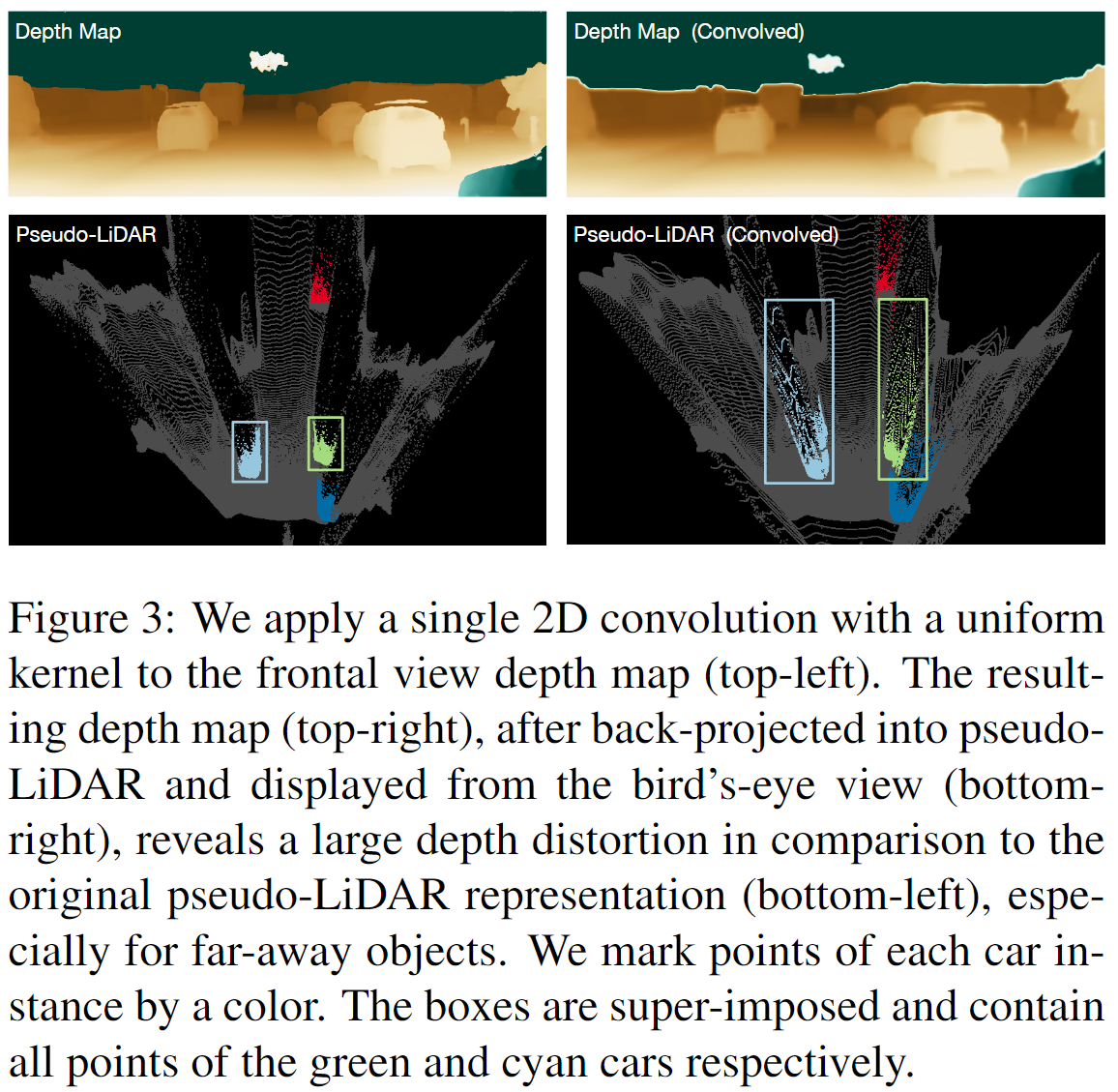
由于RGBD不好使,所以诞生出了MV3D(基于鸟瞰图表示),Frustum-Pointnet(基于点云表示),VoxelNet(基于体素表示),在KITTI榜上效果都很好,都能融合RGB信息。
最典型的例子在6D姿态估计上,可以对所检测的物体都建立一个3D模型,然后就可以随意合成数据了(甚至可以渲染不同光照),这在2D图像上是很难的。这些合成的数据不需要特殊的迁移/领域自适应手段就能提高准确率,相当于数据增强的作用。但在另一方面,比如GTA5到现实世界的数据差异就比较大,需要进一步的领域自适应的研究。
【在一次用DenseFusion模型(一个融合RGB和点云特征做6D姿态估计的模型,CVPR2019)对YCB-Video数据集进行实验时,用大约1w真实数据+8w合成数据,得到AP大约为0.92;第二次实验只使用8w合成数据,得到AP大约为0.90,只降低了0.02.】
我经常也在想为什么做3D目标检测的都是train from stretch,而不是拿ModelNet,ShapeNet等模型数据集进行预训练。
医学上不仅有3DCT,还有SMLM(Single molecule localization microscopy)产生的点云数据。
标签:融合 就是 形状 自适应 shape 约束 sha https 图像
原文地址:https://www.cnblogs.com/simingfan/p/11782378.html