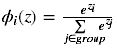标签:ble ati ring 梯度下降 pem width height nim span
【 tensorflow中文文档:tensorflow 的激活函数有哪些】

激活函数可以分为两大类 :
相对于饱和激活函数,使用“非饱和激活函数”的优势在于两点:
1.首先,“非饱和激活函数”能解决深度神经网络【层数非常多!!】的“梯度消失”问题,浅层网络【三五层那种】才用sigmoid 作为激活函数。
2.其次,它能加快收敛速度。
目录
(2)tanh (双曲正切函数 ;Hyperbolic tangent function)
(3) relu (Rectified linear unit; 修正线性单元 )
(4)Leaky Relu (带泄漏单元的relu ) (5) RReLU(随机ReLU)
(6)softsign (7)softplus (8)Softmax

参数 α > 0 可控制其斜率。 sigmoid 将一个实值输入压缩至[0,1]的范围,也可用于二分类的输出层。

将 一个实值输入压缩至 [-1, 1]的范围,这类函数具有平滑和渐近性,并保持单调性.

深度学习目前最常用的激活函数
与Sigmoid/tanh函数相比,ReLu激活函数的优点是:
缺点是: Relu的输入值为负的时候,输出始终为0,其一阶导数也始终为0,这样会导致神经元不能更新参数,也就是神经元不学习了,这种现象叫做“Dead Neuron”。
为了解决Relu函数这个缺点,在Relu函数的负半区间引入一个泄露(Leaky)值,所以称为Leaky Relu函数。
数学表达式: y = max(0, x) + leak*min(0,x)
与 ReLu 相比 ,leak 给所有负值赋予一个非零斜率, leak是一个很小的常数 ,这样保留了一些负轴的值,使得负轴的信息不会全部丢失)
 leaky ReLU
leaky ReLU
比较高效的写法为:
在训练时使用RReLU作为激活函数,则需要从均匀分布U(I,u)中随机抽取的一个数值 ,作为负值的斜率。
数学表达式:
,导数:

Softplus函数是Logistic-Sigmoid函数原函数。 ,加了1是为了保证非负性。Softplus可以看作是强制非负校正函数max(0,x)平滑版本。红色的即为ReLU。
用于多分类神经网络输出
在这篇论文中,作者展示了几个使用GELU的神经网络优于使用ReLU作为激活的神经网络的实例。GELU也被用于BERT。
GELU、ReLU和LeakyReLU的函数

以下两个是以前使用的:

相应的输出 为
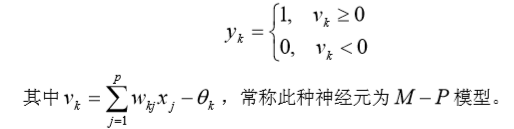
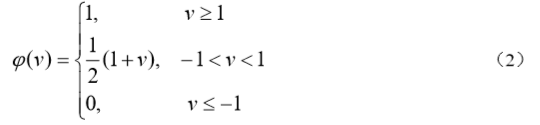
它类似于一个放大系数为 1 的非线性放大器,当工作于线性区时它是一个线性组合器, 放大系数趋于无穷大时变成一个阈值单元。
3.Swish函数
Swish函数是一种自控门的激活函数,其定义:
Swish(x)=xσ(βx) Swish(x) = x\sigma(\beta x)
Swish(x)=xσ(βx)
其中,σ(⋅) \sigma(·)σ(⋅)函数是logistic函数,其值域在(−1,1) (-1,1)(−1,1),β \betaβ是一个参数。也就是说当σ(⋅) \sigma(·)σ(⋅)趋近于1的时候,其输出和x xx本身近似;当σ(⋅) \sigma(·)σ(⋅)趋近于0的时候,其输出趋近于0。
3、基于Gate mechanism的GLU、GTU 单元
介绍一下基于gate mechanism实现的,两个比较新颖的激活函数GTU和GLU。
GTU(Gated Tanh Unit)的表达式为:
f(X) = tanh(X*W+b) * O(X*V+c)
GLU(Gated Liner Unit)的表达式为:
f(X) = (X * W + b) * O(X * V + c)
分析GTU和GLU的组成结构可以发现:
Tanh激活单元:tanh(X*W+b),加上一个Sigmoid激活单元:O(X*V+c)构成的gate unit,就构成了GTU单元。
Relu激活单元:(X * W + b),加上一个Sigmoid激活单元:O(X * V + c)构成的gate unit,就构成了GLU单元。
原文链接:https://blog.csdn.net/lqfarmer/article/details/72676715
深度学习的激活函数 :sigmoid、tanh、ReLU 、Leaky Relu、RReLU、softsign 、softplus、GELU
标签:ble ati ring 梯度下降 pem width height nim span
原文地址:https://www.cnblogs.com/think90/p/11883739.html