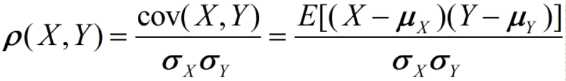标签:EDA ryu asa auc mux col data 效果 lfs
统计学习中的相关性
-
皮尔逊相关系数( Pearson correlation coefficient):
度量两个变量X和Y之间的相关(线性相关)
- 斯皮尔曼相关性系数(spearman correlation coefficient):
先将样本转化为等级变量,如90分为等级1,然后使用上面相关系数公式对等级进行相关性计算。
- 肯德尔和谐系数(kendall correlation coefficient):
表示多列等级变量相关程度的一种方法,检测多个评价者对一群候选者的评价标准是否一致。

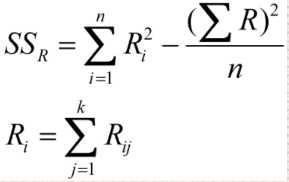
其中k表示评价者数量,n表示被评价者数量。Ri表示第i个被评价者的总等级。
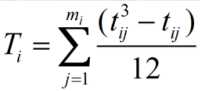
其中mi表示第i个评价者的结果中有多少种是重复等级,t_ij表示第i个评价者的第j个重复等级的数量。
- 马修斯相关系数(Matthews correlation coefficient):
机器学习中,用以测量二分类的分类性能的指标。该指标考虑了真阳性、真阴性和假阳性和假阴性,通常认为该指标是一个比较均衡的指标,即使是在两类别的样本含量差别很大时,也可以应用它。MCC本质上是一个描述实际分类与预测分类之间的相关系数,它的取值范围为[-1,1],取值为1时表示对受试对象的完美预测,取值为0时表示预测的结果还不如随机预测的结果,-1是指预测分类和实际分类完全不一致。
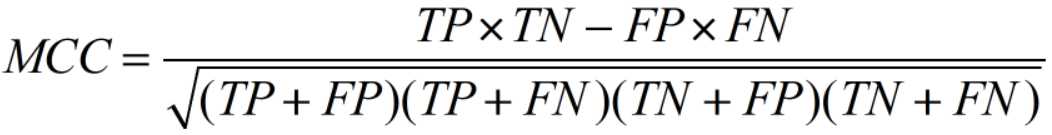
机器学习中的评价指标
回归评估:
- MAE:平均绝对误差,L1范数
- MSE:平均平方差,L2范数
分类评估:

TP:预测为正向(P),实际上预测正确(T),即判断为正向的正确率
TN:预测为负向(N),实际上预测正确(T),即判断为负向的正确率
FP:预测为正向(P),实际上预测错误(F),误报率,即把负向判断成了正向
FN:预测为负向(N),实际上预测错误(F),漏报率,即把正向判断称了负向
- 准确率Accuracy:预测对的比上全部数据。正负样本不平衡时这个评估不好。
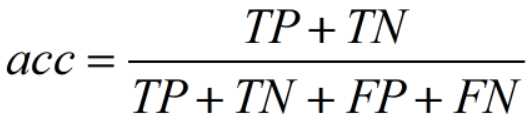
- 查准率(precision):预测为正例的中,有多少比例为预测正确。
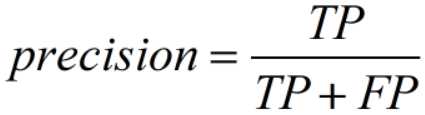
- 召回率(recall):也叫查全率。实际为正例的中,有多少比例为预测正确。
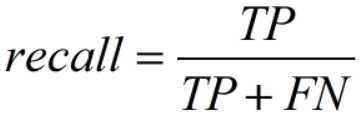
- F-值(F-Score):查全率与查准率加权调和平均。
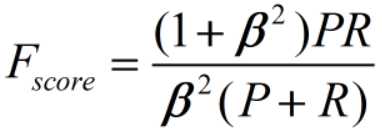
当β=1时,即通常所说F1 score。
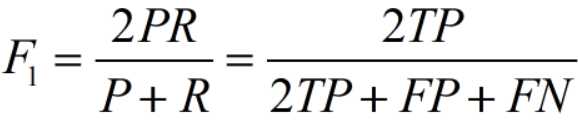
- 马修斯相关系数MCC:见上面统计部分
- AUC(Area Under Curve):将横坐标定为false positive rate(FPR),纵坐标定为true positive rate(TPR)。曲线下的面积作为衡量指标。表征任意一个正负样本对中,将正样本预测为正的概率值比预测为负的概率值还要大的可能性。FPR表示所有负例中,有多少被预测为正例。TPR表示所有正例中,有多少被预测为正例。
在固定横坐标时,纵坐标越大,表明正例中预测为正例的越多(正例中的预测准确度越高)。固定纵坐标时,横坐标越小,表示负例中被错误预测为正例的越少。综合考虑,曲线越靠近y轴且高度越高,则表明分类效果越好,即AUC可以有效表征分类性能。

不画图也可以计算,假设总共有(m+n)个样本,其中正样本m个,负样本n个,总共有m*n个正负样本对。对每一个样本对进行计数,如果正样本预测为正样本的概率值大于负样本预测为正样本的概率值,则结果加1,最后用结果除以(m*n)就是AUC的值。
统计学中相关性与机器学习中的评价指标
标签:EDA ryu asa auc mux col data 效果 lfs
原文地址:https://www.cnblogs.com/lunge-blog/p/11885615.html