标签:height 中国 获取数据 节点 sla erb http 解析 enter
以淘宝网为例,访问
https://www.baidu.com/robots.txt
最后有两行代码:
User-Agent: *
Disallow: /
意思是除了之前指定的爬虫,不允许其他爬虫爬取任何数据。
1 url = ‘http://www.cntour.cn/’ 2 strhtml = requests.get(url) 3 print(strhtml.text)
首先确定其信息传送方式及相关url。按F12出现开发者工具:
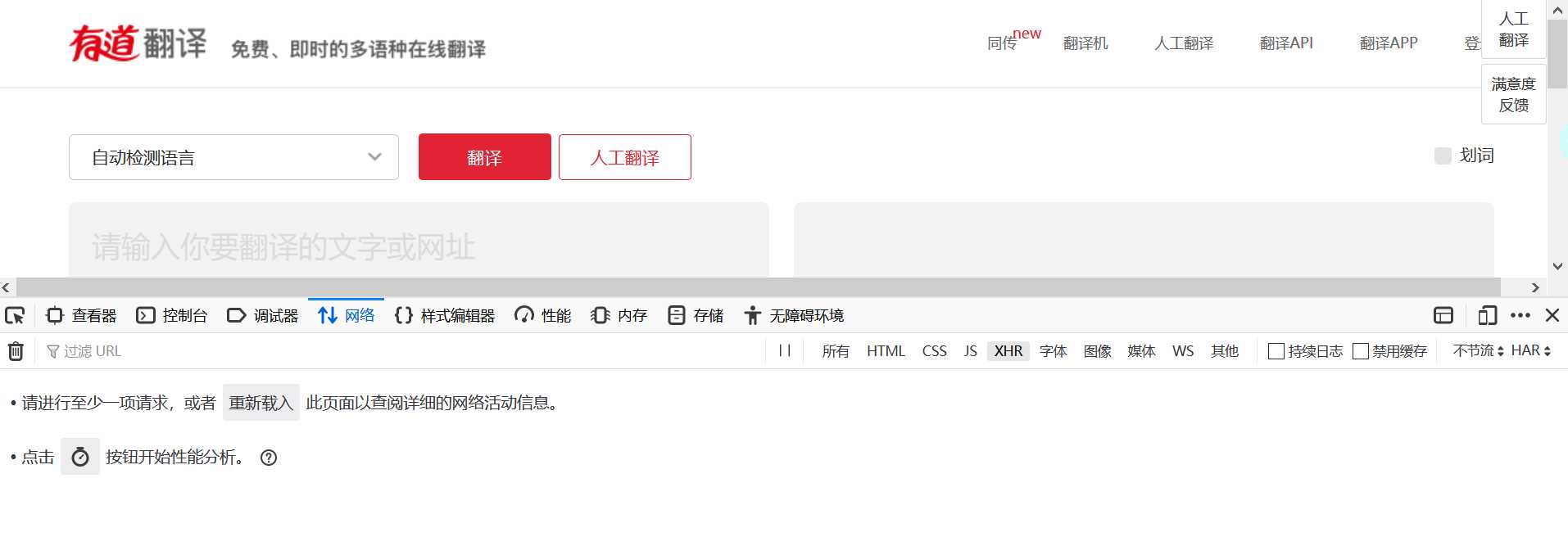
当完成翻译,选择网络->XHR,出现我们要的URL,之后将它提取出来并赋值给url:

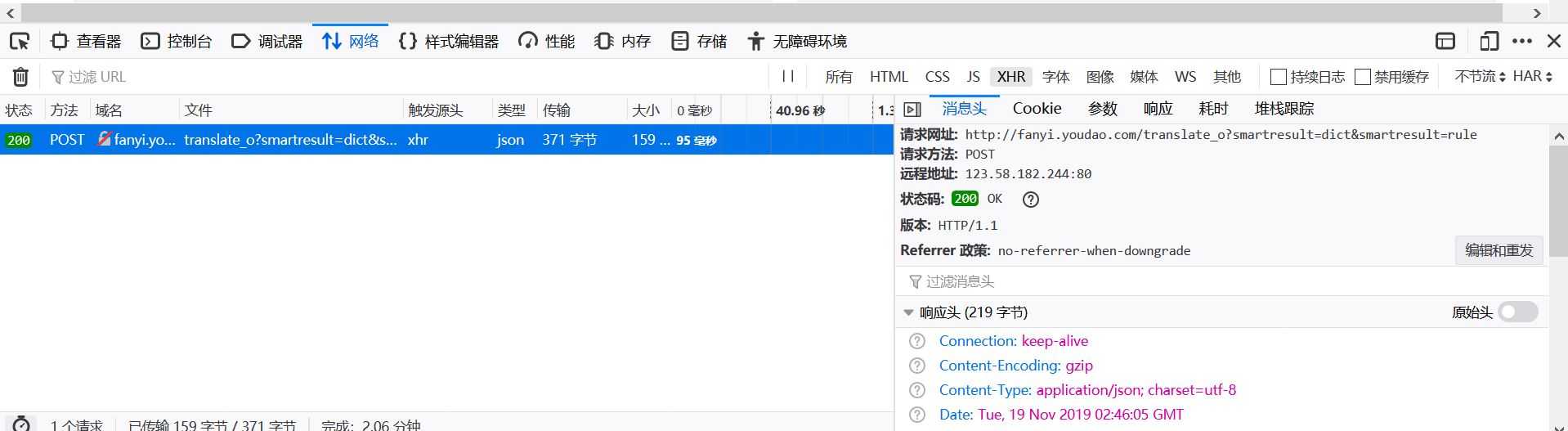
查看此url的详情,确定其提交方式和具体信息:
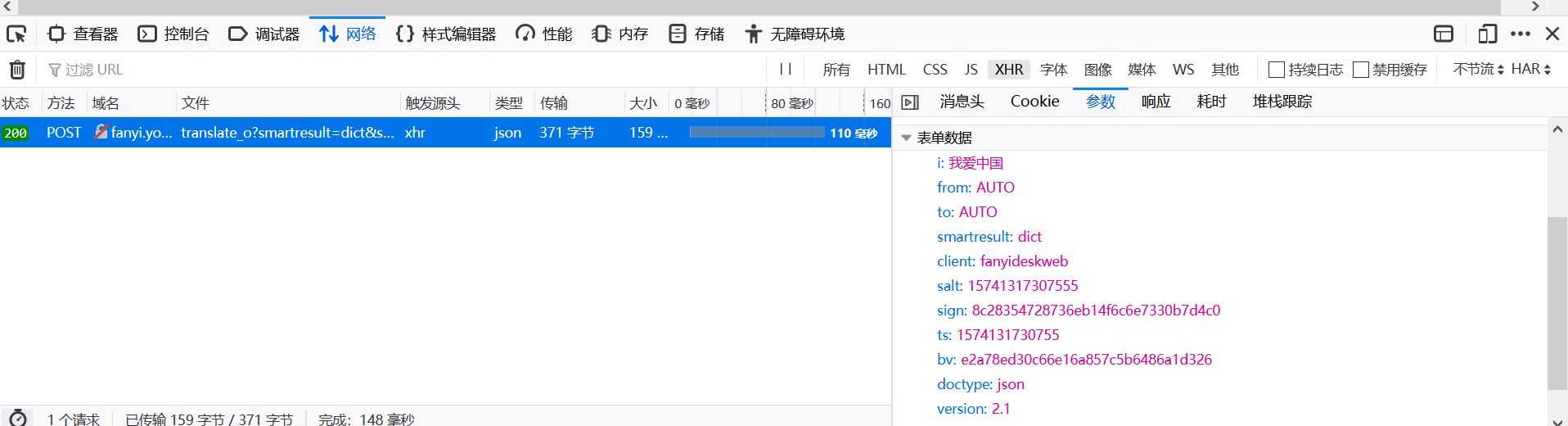
Post请求获取数据的方式不同于Get,必须构建请求头。表单数据(Form data)中请求参数如下,将其复制并会构造成一个字典:
接下来开始使用 requests.post 方法请求表单数据:
1 import requests 2 import json 3 def get_translate_data(word=None): 4 url=‘http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule‘ 5 Form_data = {i":"我爱中国\n","from":"AUTO","to":"AUTO","smartresult":"dict","client":"fanyideskweb","salt":"15741317307555","sign":"8c28354728736eb14f6c6e7330b7d4c0","ts":"1574131730755","bv":"e2a78ed30c66e16a857c5b6486a1d326","doctype":"json","version":"2.1","keyfrom":"fanyi.web","action":"FY_BY_REALTlME"} 6 # 请求表单数据 7 response = requests.post(url, data=payload) 8 # 将JSON格式字符串转字典 9 content = json.loads(response.text) 10 # 打印翻译后的数据 11 print(content[‘translateResult‘][0][0][‘tgt‘]) 12 if _name_==‘_main_‘: 13 get_translate_data(‘我爱数据‘)
通过requests库已经可以抓到网页源码,接下来要从源码中找到并提取数据——使用bs4库中的BeautifulSoup库。
首先html文档被转换成unicode编码格式,然后我们指定了lxml解析器对这段文档进行解析。解析后html文档变成树形结构,每个节点都是python对象。解析后的文档存储进新建的变量soup中。用select(选择器)定位数据,用“检查元素”,右击 copy->copy selector自动复制路径。
依然以www.cntour.cn为例:
1 import requests 2 from bs4 import BeautifulSoup 3 url=‘http://www.cntour.cn/‘ 4 strhtml=requests.get(url) 5 soup=BeautifulSoup(strhtml.text, ‘lxml‘) 6 data=soup.select(‘main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a‘) 7 print(data)
标签:height 中国 获取数据 节点 sla erb http 解析 enter
原文地址:https://www.cnblogs.com/wowhy/p/11888430.html