标签:class extend ram 字典 color 名称 信息 防止 通过
一、首先需要导入我们的库函数
导语:通过看网上直播学习得到,如有雷同纯属巧合。
import requests#请求网页链接
import pandas as pd#建立数据模型
from bs4 import BeautifulSoup
import io
import sys#防止乱码
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘)
注:如有库安装不了,可参考上一篇随笔。
二、源代码:
1 import requests 2 import pandas as pd 3 from bs4 import BeautifulSoup 4 import io 5 import sys#防止乱码 6 sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘) 7 def get_url(n): 8 #获取网页链接 9 urls=[] 10 for i in range(1,n+1): 11 urls.append(‘https://travel.qunar.com/p-cs299878-shanghai-jingdian-1-%s‘ %i)#获取n段网页链接 12 return urls 13 14 pass 15 16 def get_data(url):#获取一段网页链接的数据 17 r=requests.get(url) 18 soup=BeautifulSoup(r.text,‘lxml‘)#lxml一种不错的编译器 19 ul=soup.find(‘ul‘,class_=‘list_item clrfix‘)#在网页中通过查找元素信息找到其名称 20 lis=ul.find_all(‘li‘)#查找所有信息 21 datalst=[]#定义一个数据字典 22 for li in lis: 23 dic={}#将需要查找的信息写入数据字典 24 dic[‘景点名称‘]=li.find(‘span‘,class_=‘cn_tit‘).text 25 dic[‘星级‘]=li.find(‘span‘,class_=‘cur_star‘)[‘style‘].split(‘:‘)[1].replace(‘%‘,‘‘)#将数据中的百分号去掉实现初步数据清洗 26 dic[‘经度‘]=li[‘data-lng‘] 27 dic[‘纬度‘]=li[‘data-lat‘] 28 datalst.append(dic) 29 return datalst 30 31 32 def get_alldata(n):#按要求查找多段网页链接的数据 33 alldata=[] 34 for url in get_url(n): 35 alldata.extend(get_data(url)) 36 return alldata 37 #print(get_alldata(2)) 38 df=pd.DataFrame(get_alldata(2))#建立pandas模型,按要求输出 39 print(df)
三、运行结果:
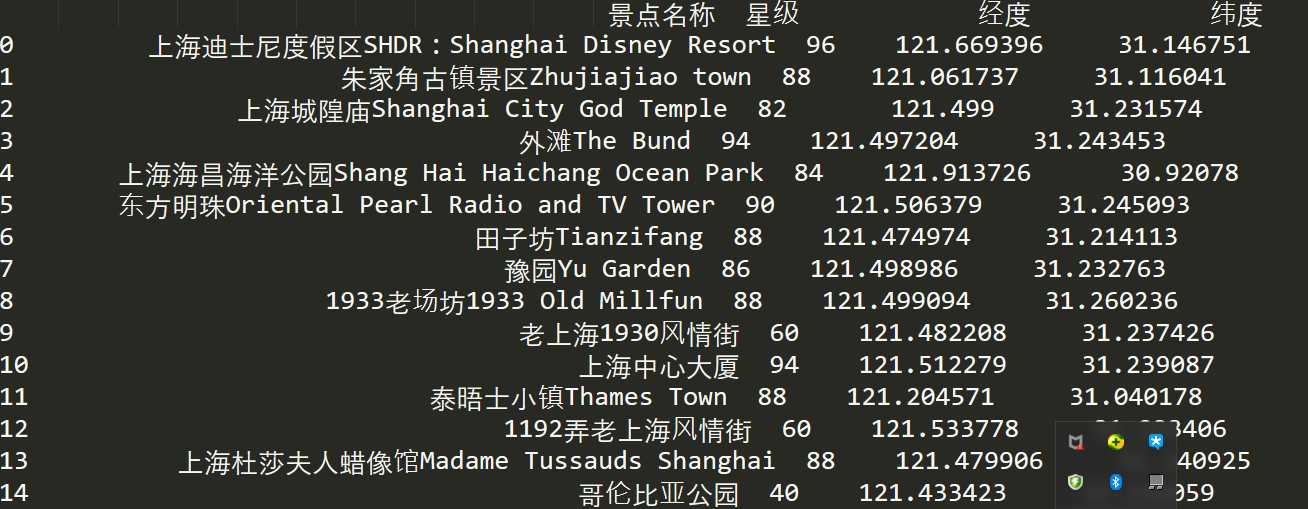
小有瑕疵,初学见谅!!!
标签:class extend ram 字典 color 名称 信息 防止 通过
原文地址:https://www.cnblogs.com/Wang1107/p/11874600.html