标签:pac put compute python版本 框架 输入 c++ file tco
说明:本文是我学习《TensorFlow深度学习应用实战》一书第5章知识的一个总结与实验过程,一方面是希望记录下自己的学习经历;另一方面是希望通过自己学习过程中的经历分享出来,相互学习,相互交流,共同成长。(本人刚学,所以很菜,请各位大佬勿喷,谢谢!)
OpenCV:全称(Open Source Computer Vision Library),它是Intel公司所支持开发的一个计算机视觉处理开源软件库,采用C和C++编写,同时提供了Python、Matlab等语言的接口,并且可以自由地运行在Linux/Windows/Mac等多平台操作系统上。
OpenCV的目标是让使用者能够通过合理的使用和搭配,构建一个简单易用的计算机视觉处理框架,能够便捷地设计更为复杂的计算机视觉的相关应用,而且OpenCV充分利用了Intel处理器的高性能多媒体函数库的手工优化性能,提高了运行速度。
目前来说,OpenCV所包含的能够进行视觉处理的函数和方法接近1000个,已经能够极大地满足各行各业的需求,覆盖了如医学影像、设计外观、定位标记、生物体检测等多个行业领域。
在进行简单的应用前,我们必须先下载安装opencv,我使用的是Anaconda 3+PyCharm,具体的做法如下:
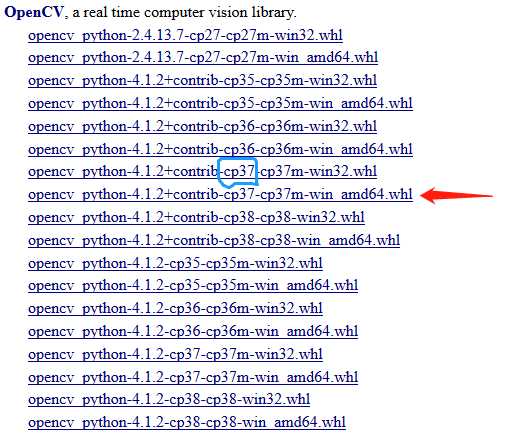
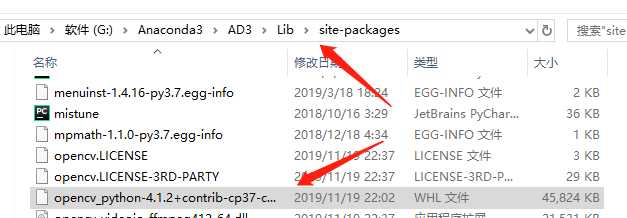

(因我之前已成功安装,故而输入此命令时显示Requirement already satisfied)
import numpy as np import cv2 #创建一个长、宽各300的矩阵(300*300像素的图片),各点的值为0 img=np.mat(np.zeros((300,300))) #输出图片 cv2.imshow("test",img) #使输出的图像暂时等待 cv2.waitKey(0)
输出效果如下:(该矩阵中每个具体的数值为0,故每个像素点的颜色为黑色)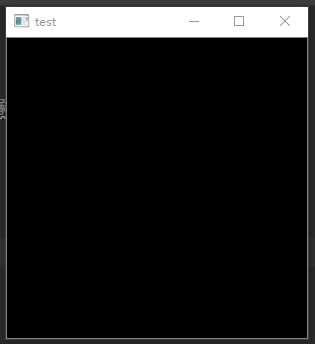
将 1 中的一维图片转化成三维(RGB)图片:
import numpy as np import cv2 #创建一个长、宽各300的矩阵(300*300像素的图片),各点的值为0 img=np.mat(np.zeros((300,300)),dtype="uint8") #强制将原始的一维图片转化为三维图片 img=cv2.cvtColor(img,cv2.COLOR_GRAY2BGR) #打印出通道数目 print(img.shape)
输出结果:
import numpy as np import cv2 #读取当前目录下的picture1.jpg图片,读取为灰度图 image=cv2.imread("picture1.jpg",cv2.IMREAD_GRAYSCALE) #将所读取的图片的格式变成.png格式,存储在当前目录下 cv2.imwrite("picture1s.png",image)
代码执行前当前工作目录: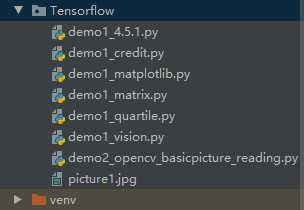
代码执行后当前工作目录:
picture1.jpg与picture1s.png效果对比:

图像的转换:将生成的一个 [300,300] 的矩阵按数组的形式转化并打印,之后通过调用NumPy中数组处理函数重新将其重构并显示:
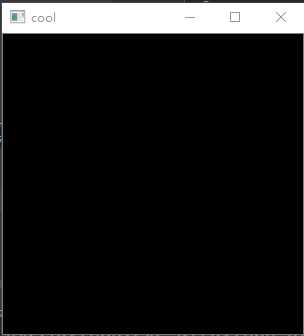
import numpy as np import cv2 image=np.mat(np.zeros((300,300))) #减少图片的存储占用空间 imageByteArray=bytearray(image) #打印存储格式 print(imageByteArray) #通过矩阵重构的方法还原为原本的图片矩阵 imageBGR=np.array(imageByteArray).reshape(300,300) cv2.imshow("cool",imageBGR) cv2.waitKey(0)
输出结果: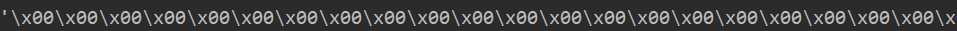
随机生成一个长度为120000的数组,后将其重构为 [300,400] 的矩阵:
import numpy as np import cv2 import os #随机生成一个长度为120000的数组 randomByteArray=bytearray(os.urandom(120000)) #重构为[300,400]的矩阵 flatNumpyArray=np.array(randomByteArray).reshape(300,400) cv2.imshow("cool",flatNumpyArray) cv2.waitKey(0)
输出结果: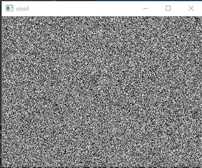
import numpy as np import cv2 #生成一个300*300矩阵 img=np.zeros((300,300)) #将矩阵的[0,0]位置数值修改为255 img[0,0]=255 cv2.imshow("img",img) cv2.waitKey(0)
输出结果:(红色箭头所指:修改的位置的颜色由原先的黑色变成白色)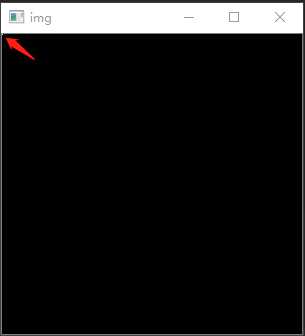
由此拓展,对一行或一列进行操作:
import numpy as np import cv2 #生成一个300*300矩阵 img=np.zeros((300,300)) #将第10列逐行向下位置的数值修改为255 img[:,10]=255 #将第10行逐列向右位置的数值修改为255 img[10,:]=255 cv2.imshow("img",img) cv2.waitKey(0)
输出结果:(画出了横竖两条白线)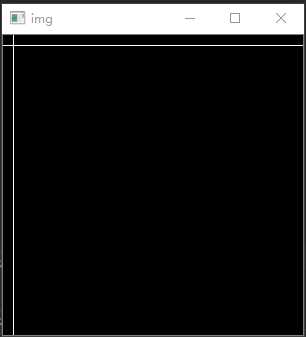
import numpy as np #[3,3]卷积核,用来计算中央像素与周围临近像素的亮度差值。如果一个像素比他周围的像素更加突出,就会提升其本身的亮度 kernel1=np.array([[-1,-1,-1], [-1,8,-1], [-1,-1,-1]]) #相反情况。减少中心像素的亮度,如果一个像素比其周围的像素更加昏暗,就会更进一步地减少 kernel2=np.array([[1,1,1], [1,-8,1], [1,1,1]])
用卷积核处理一张彩色图片:
import numpy as np import cv2 from scipy import ndimage #[3,3]卷积核,将读入的图像进行颜色提高 kernel1=np.array([[-1,-1,-1], [-1,8,-1], [-1,-1,-1]]) #[3,3]卷积核,将读入的图像进行颜色降低 kernel2=np.array([[1,1,1], [1,-8,1], [1,1,1]]) #读取当前目录下的lena.jpg图片 img=cv2.imread("lena.jpg",0) #ndimage:处理多维图像的函数库,其中包括图像滤波器、傅里叶变换、图像的旋转拉伸以及测量和形态学处理等 linghtImg1=ndimage.convolve(img,kernel1) linghtImg2=ndimage.convolve(img,kernel2) cv2.imshow("img1",linghtImg1) cv2.imshow("img2",linghtImg2) cv2.waitKey(0)
输出结果:(由于卷积核降低的程度较大,最后完全造成了失真)
import numpy as np def convolve(dateMat,kernel): #获取输入矩阵的行列数大小 m,n=dateMat.shape #获取卷积核的行列数大小 km,kn=kernel.shape #初始化生成全为1的输出矩阵,经计算得出输出矩阵的大小为:(m-km+1)*(n-kn+1) newMat=np.ones(((m-km+1),(n-kn+1))) #初始化生成一个全为1的卷积核 tempMat=np.ones(((km),(kn))) for row in range(m-km+1): for col in range(n-kn+1): for m_k in range(km): for n_k in range(kn): #平移计算覆盖区域对应元素值的大小 tempMat[m_k,n_k]=dateMat[(row+m_k),(col+n_k)]*kernel[m_k,n_k] #求和得到输出矩阵对应每个单位矩阵的元素值 newMat[row,col]=np.sum(tempMat) return newMat
OpenCV中提供了常用的卷积核函数——fileter2D,其具体使用如下:
cv2.filter2D(src,-1,kernel,dst)
注:src是目标图片,-1是指每个目标图片的通道位深数,一般要求目标图片和生成图片的位深数一样,kernel是图片所使用的卷积核矩阵。
标签:pac put compute python版本 框架 输入 c++ file tco
原文地址:https://www.cnblogs.com/Details-K/p/11894912.html