标签:-o 举例 title pop 分表 nbsp orm 请求 extc
from : https://zhuanlan.zhihu.com/p/85660050
对于预算扣减/库存扣减类场景,我们需要根据业务对已有预算/库存做减法,拿发券的场景来举例:
本文介绍的方案还可以作为秒杀类业务中的一部分
对于预算的扣减需求,可以用2条简单的sql来理解:
insert into budget_log (biz_no, budget_code) values (#{bizNo}, #{budget_code})其中biz_no表示一次扣减的唯一标识,budget_code是一个预算计划的唯一标识
update budget set amount = amount - #{amt} where budget_code = #{budgetCode} and amount >= #{amt}但是如果对并发的要求是百级别,仅仅依靠这两条sql或许可以满足需求,但是想要达到数十万以上的并发支撑,这样是远远不够的。
我曾经使用的库(全库能支持6k的tps)能支持到300次扣减,数据库资源发挥不出来。为什么会出现这种情况呢?6k的tps只能发挥出600tps的能力(300次流水插入+300次预算扣减),因为数据库在执行扣减sql时,会加上行锁,所有的扣减都会在此排队
很多人会使用缓存解决问题,使用缓存后,并发往往能达到要求,但是缓存的另一个问题在于无法保持强一致,且缓存有宕机的风险,宕机后相关数据丢失,对于有强一致需求的场景,使用缓存并不合适,需要考虑基于数据库的方案,
前面说过,扣减sql有行锁导致并发量无法提高,那么我们可以将数据进行拆分,将一行数据拆分成多行,分布在不同的表上,可更进一步使用分库分表的方式提高并发量。
按照我使用的DB的能力,DB能支持6k的tps,一次预算扣减需要一次写流水和一次扣减操作,那么可以算出,DB每秒可支持3000次预算扣减业务,而在单行上只能支持300次扣减业务,我们可以分10个表,将单行转变为10行
假如有100万预算,分10个表,每个表10万,扣减方案如下图:
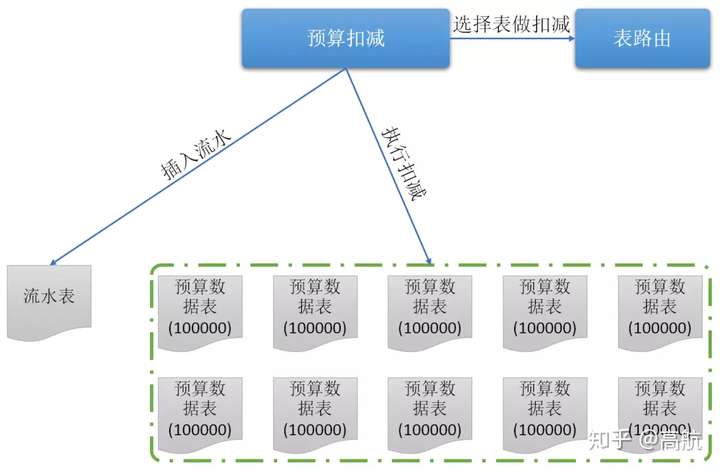
分表扣减
通过分表的方案后,能支撑秒级3000次的扣减业务,但是这样还不够,如果想要支撑数十万,依然远远不够。
通过前面的计算,我们知道,分表后,可将单个数据库的性能发挥到极限,想要再进一步提高支持的并发量,可以再加上分库的方式,使用分库分表的方案,单库秒级只能支撑3000次扣减业务,那么如果分100库,则秒级可支撑30万次扣减业务,如下图:
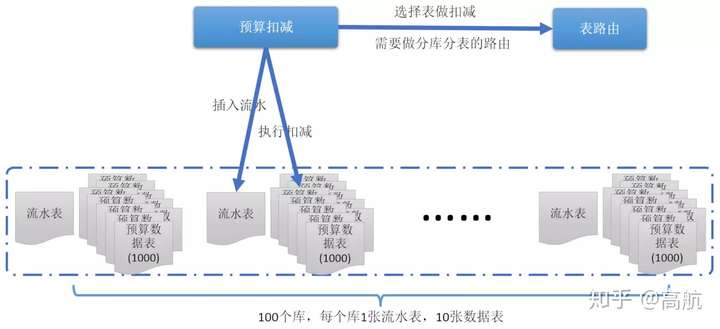
分库分表方案
还是假设有100万预算,当我们使用100库1000表后,单行转变成了1000行,处理能力可扩大1000倍,每个表1000预算
需要注意的是:
通过分库分表的方式,我们确实可以达到非常高的并发量的支持,但是如果结合实际情况,我们会发现以下问题:
如果流量不均,那么每容易出现某些表很快就扣完了,有些表扣的比较慢,这样导致系统整体容量降低
我们可以通过按需分配的方式解决这个问题,我们将每个表上的一行数据称为一个分桶,我们增加总桶的概念,初始时,预算都在总桶中,然后依次给每个分桶分配少量的预算,比如100(具体的分配金额可根据实际场景确定),那么初始分配后,每个分桶100,1000个分桶一共10万,总桶中还有90万,当一个分桶扣完后,立即向总桶申请一定的预算,这样可以保证分桶中的预算大体上是按流量分配的,方案如下图:
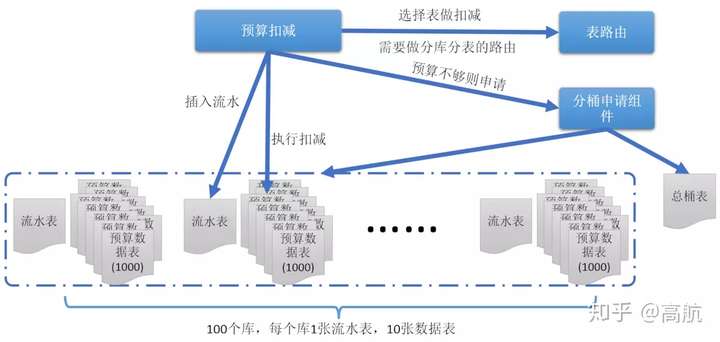
预算申请
当总桶无预算时,预算申请都会失败,而当预算申请失败后,某些库可能会出现无预算可扣的情况,在这种场景下,如果换到有预算的库做预算的扣减,那么就可能会出现库被打挂的风险,举个例子:
假设业务上有10万的tps,100库平均每个库1000,当总桶无预算可申请,其中的99个库慢慢的扣完后,10万的tps会打到剩下的一个有预算的库上,这个库肯定无法承受秒级10万的扣减业务
如何解决这个问题呢?在前面描述的按需申请预算的基础上做一个限制,分库路由规则中,如果业务被分到了无预算可扣减的库上,则返回扣减失败,给调用方返回预算已扣完,因为流量大体上是均衡的,所以这样做的问题并不大
本文介绍的方案是基于分库分表的,脱离我们这个方法,最后聊一聊分库分表的作用,根据经验,我认为分库分表可解决以下问题:
所以,在数据量并不大的情况下,也是有分库分表的场景和必要性的
标签:-o 举例 title pop 分表 nbsp orm 请求 extc
原文地址:https://www.cnblogs.com/liuqingsha3/p/11907757.html