标签:style blog http io ar 使用 sp strong 数据
继续上篇来写。为了使这个神经网络满足我们需要,我们能够改变的东西有:
(0)输入输出的格式和质量
(1)各个神经元的权重值W
(2)偏置bias,这个改变从广义上说,也算是改变权重W0
(3)激活函数
(4)神经网络层数
(5)每一层神经元个数
(6)神经网络的结构
那么问题又来了,这些参数怎么改变呢?我们一部分一部分的进行讲解。
一、激活函数的选取
下面列出几个激活函数数学定义以及Matlab中的相应函数,大家可以在matlab中用函数画一下,看看他们到底是怎么一个函数。
(1) 线性函数 ( Liner Function )
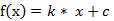
Matlab中可以使用:purelin函数
(2) 阈值函数 ( Threshold Function )
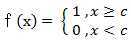
Matlab中可以使用:hardlim和hardlims函数,值域分别为[0,1]和[-1,1]
(3) S形函数 ( Sigmoid Function )
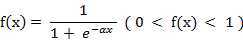
Matlab中可以使用:logsig函数
(4) 双极S形函数
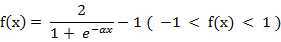
Matlab中可以使用:tansig函数
上面列出了几个激活函数,当然还可以选择其他的激活函数,那么到底怎么选择呢?目前我看到的是:就是使用Matlab默认的,或者瞎试,哪个好用哪个。不过我觉得,等对神经网络理解比较透彻了,应该对如何选择会有更深入的认识。
二、各个神经元的权重值W和偏置bias
我们输入网络数据,再输出数据,就是为了改变W和bias,使网络更符合要求,对于如何修改W和bias,是借助于一定的训练算法和学习算法来完成的。这些训练算法和学习算法,对应于Matlab中就是一些训练函数和学习函数。注意:训练用英文train来表示,学习用learn来表示。
接下来问题是:这些算法是依据什么原理设计的呢?总结下来有下面两种训练算法:有监督学习算法和无监督学习算法。
1.有监督学习算法,也叫有教师学习算法等等,但是记住英文名就可以了:Supervised Learning,简单来说就是:我们输入许多数据,经过神经网络后会有输入数据,根据这个输出数据和期望的输出数据的差值大小,进而来调整权重和bias。有下面两点注意:
(1)期望输出哪里来的?其实我们用一些数据来训练网络,那么肯定得有输入输出数据,这个输出就是我们的期望输出数据,而网络的输出就是实际输出,随着不停的调整权重和bias,这个差值会越来越小。例如输出大于期望,那么就可以减小权重,或者使bias更负一些等等。
(2)初始权重和bias如何选择?默认是随机分配的,因此对于我们创建的神经网络,每一次训练运行,结果都会不同的,就是因为初始权重和bias是随机的。想保存最好的一次状态,可以save filename net来进行保存。
2.无监督学习算法,也叫无教师学习算法等等,但是记住英文名就可以了:UnSupervised Learning,大概思想是:当两个神经元同时处于激发状态时两者间的连接权会被加强,否则被减弱。具体不再详细讲解。
为什么会有这么多算法呢?你想啊,我们学习编程过程中,连一个排序,就有好多好多算法,所以这里神奇的神经网络有这么多算法,也不奇怪了。
补充一点:很多人问,train和learn到底有什么区别呢?可以看下面的回答:
简单来说,就是train是全局的调整权重和bias,而learn是调整局部的神经元的权重和bias。
三、神经网络层数、每一层神经元个数、神经网络的结构
简单来说就是选择不同的网络,如BP,RBF、Hopfield等网络,有机会在介绍这些具体的网络时,可以深入的讲一讲。
四、输入输出的格式和质量
1.输入输出数据的质量:保证输入数据准确完整等等就行,这里不做深入讲解,具体可以看看数据预处理。
2.输入输出数据的格式:这里涉及到的就是数据的归一化问题,这里简单说一下。
输入输出数据的归一化简单来说:就是利用一定的算法,把输入输出数据归一到[0,1]区间或者[-1,1]之间,原因如下:
(1)输入输出数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。例如有些输入数值是高度,而有些是温度,纯数字大小很差别很大。
(2)数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。
(3)由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
(4)S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X),f(100)与f(5)只相差0.0067。
知道了为什么要归一化,那么如何进行归一化呢?两个公式
(1)y = ( x - min )/( max - min ),那么数据x就化简到[0,1]之间了。
(2)y = 2 * ( x - min ) / ( max - min ) - 1,那么数据x就化简到[-1,1]之间了。
知道了数学上的公式,那么在Matlab中如何使用呢?
使用一个统一的公式:mapminmax,具体用法:
============================
最近帮朋友弄了微信公众号,每天早上6点30分,发送一个60秒的语音,有兴趣的朋友不妨关注一下。
微信号:歪理邪说(wailixs)
二维码:

标签:style blog http io ar 使用 sp strong 数据
原文地址:http://www.cnblogs.com/wuguanglei/p/4059995.html