标签:gen request对象 token led art mys 启动 span 接受
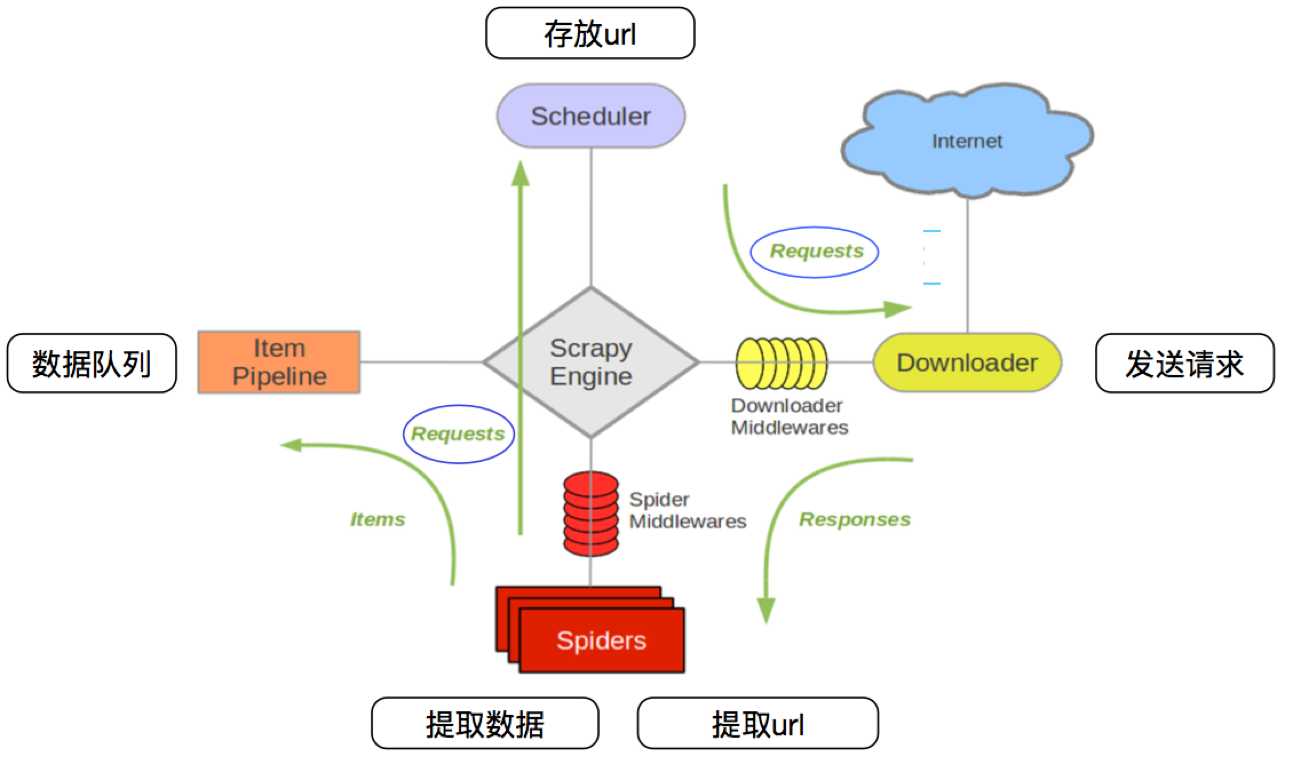
其流程可以描述如下:
注意:
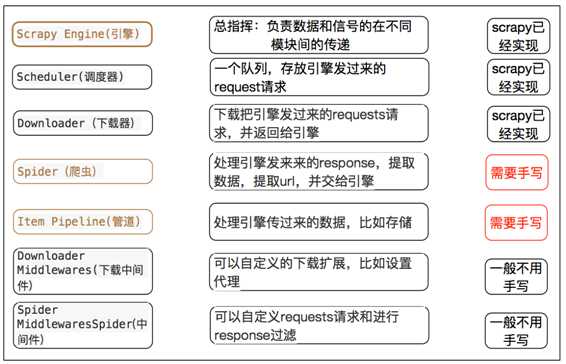
创建一个scrapy项目:scrapy startproject 项目名
生成一个爬虫:scrapy genspider 爬虫名 允许爬取的范围
提取数据:完善spider,使用xpath等方法
保存数据:pipeline中保存数据
命令:scrapy startproject +<项目名字>
示例:scrapy startproject myspider
生成的目录和文件结果如下:
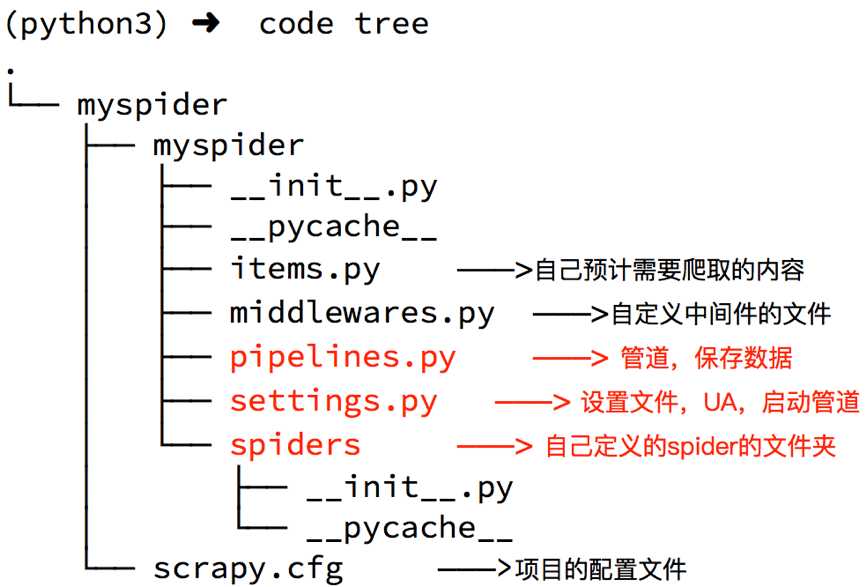
settings.py中的重点字段和内涵
USER_AGENT 设置uaROBOTSTXT_OBEY 是否遵守robots协议,默认是遵守CONCURRENT_REQUESTS 设置并发请求的数量,默认是16个DOWNLOAD_DELAY 下载延迟,默认无延迟COOKIES_ENABLED 是否开启cookie,即每次请求带上前一次的cookie,默认是开启的DEFAULT_REQUEST_HEADERS 设置默认请求头SPIDER_MIDDLEWARES 爬虫中间件,设置过程和管道相同DOWNLOADER_MIDDLEWARES 下载中间件命令:scrapy genspider +<爬虫名字> + <允许爬取的域名>
生成的目录和文件结果如下:

完善spider即通过方法进行数据的提取等操做:
注意:
response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法extract() 返回一个包含有字符串的列表extract_first() 返回列表中的第一个字符串,列表为空没有返回None

为什么要使用yield?
注意:
BaseItem,Request,dict,None

pipeline在settings中能够开启多个,为什么需要开启多个?
pipeline使用注意点
return item,否则后一个pipeline取到的数据为None值
标签:gen request对象 token led art mys 启动 span 接受
原文地址:https://www.cnblogs.com/skaarl/p/11919540.html