标签:业务用例 通用 利用 电影 步骤 sso use tin format
业务领域建模的概念
领域建模是描述业务用例实现的对象模型。它是对业务角色和业务实体之间应该如何联系和协作以执行业务的一种抽象。业务对象模型从业务角色内部的观点定义了业务用例。该模型为产生预期效果确定了业务人员以及他们处理和使用的对象(“业务类和对象”)之间应该具有的静态和动态关系。它注重业务中承担的角色及其当前职责。这些模型类的对象组合在一起可以执行所有的业务用例。(百度百科)
业务领域建模的原因
分析系统和设计系统不是同一个人,这种割裂导致需求分析的结果无法直接进行设计编程,而能够进行编程运行的代码却扭曲需求,导致客户运行软件后才发现很多功能不是自己想要的,而且软件不能快速跟随需求变化。DDD(领域驱动设计)则打破了这种隔阂,提出了领域模型概念,统一了分析和设计编程,使得软件能够更灵活快速跟随需求变化。对于复杂的业务场景,事务脚本很难应对,容易造成代码的“一锅粥”,系统的腐化速度和复杂性呈指数级上升。目前比较有效的治理办法就是领域建模,因为领域模型是面向对象的,在封装业务逻辑的同时,提升了对象的内聚性和重用性,因为使用了通用语言(Ubiquitous Language),使得隐藏的业务逻辑得到显性化表达,使得复杂性治理成为可能。
业务领域建模的步骤
初步建模:建模也是一个不断迭代的过程,所以一开始可以简单点来,就采用两步建模法抓住一些核心概念:首先从User Story找名词和动词,然后用UML类图画出领域模型。建模不是一个一次性的工作,往往随着业务的变化以及我们对业务的理解越来越深入才能看清系统的全貌,所以迭代重构是免不了的
模型重构:随着我们对模型对象、对业务理解的越来越深入、越来越透彻,我们会不断的调整演化我们的模型,所以建模不是一个one-time off的工作,而是一个持续不断演化重构的过程。每一次的精化之后,开发人员应该对领域知识有了更加清晰的认识。这使得理解上的突破成为可能,之后,一系列快速的改变得到了更符合用户需要并更加切合实际的模型。其功能性及说明性急速增强,而复杂性却随之消失。
聚合根:聚合根(Aggregate Root)是DDD中的一个概念,是一种更大范围的封装,把一组有相同生命周期、在业务上不可分隔的实体和值对象放在一起考虑,只有根实体可以对外暴露引用,也是一种内聚性的表现。
使用领域服务:有些领域中的动作,它们是一些动词,看上去却不属于任何对象。它们代表了领域中的一个重要的行为,所以不能忽略它们或者简单地把它们合并到某个实体或者值对象中。当这样的行为从领域中被识别出来时,最佳实践是将它声明成一个服务。这样的对象不再拥有内置的状态。它的作用仅仅是为领域提供相应的功能。
确定边界上下文:边界上下文(Bounded Context)在DDD里面是一个非常重要的概念,Bounded Context明确地限定了模型的应用范围,在Context中,要保证模型在逻辑上统一,而不用考虑它是不是适用于边界之外的情况。在其他Context中,会使用其他模型,这些模型具有不同的术语、概念、规则和Ubiquitous Language的行话。
业务领域建模的方法
四色建模法是由 Peter Coad发明的一种建模方法,将抽象出来的对象分成四种原型:
1.moment-interval:这种对象表示那些在某个时间点存在,或者会存在一段时间的,这样的对象往往表示了一次外界的请求,比如一次询价(Quotation),一次购买(Sale),这样的对象表示的都是系统的价值所在,所以也是最重要的一类对象,一般用粉红色来表示。这样的对象一般都有一个起始时间和终止时间,以及一个唯一的标识号,用来唯一的标识这一次客户请求,比如 PolicyNo。
2.Role:这种对象表示的是一种角色,往往由人或者物来承担,会有相应的责任和权利,一般一个 moment-interval 对象会关联多个 Role,比如说一次询价(Quotation)涉及到两个 Role, 询价人(Quoter)和询价的产品(Product for Quotation), 这类对象是除 moment-interval 对象外最重要的一类对象,一般用黄色来表示。这类对象一般都有一些被 moment-interval 对象请求的操作,用来完成它们的职责。
3.Party:Place or Thing, 这种对象往往表示的是一种客观存在的事物,例如:人,组织,产品,配件等等,这些事物往往会在一种 moment-interval 中扮演某个 Role, 比如某个人会在一次购买中扮演 Customer 的角色,也可以在询价中扮演询价人的角色。这类对象第三重要,所以一般用绿色来表示。这类对象一般都有 Name, Address 等属性。
4.Description:这种对象一般是分类用或者描述性的对象,一般某个 Thing, Place,Party会属于某个 Description,主要用来表示一类事物,它的属性一般都是这一类事物都有的属性,这类对象一般用蓝色来表示。这类对象一般都有 type, defaultValue 等属性。
工程实践
我的工程实践是基于情感词典的影视评论数据分析。
♦ 1) Collect application domain information
– focus on the functional requirements – also consider other requirements and documents
本项目将构建一个基于情感词典的分析系统,针对影视评论能够很好的提取出文本的情感词、情感值以及主题词,使用户能够处理大量评论数据集,从而为用户提供更有价值的影视数据参考,使得电影的评价更加可靠,让人们了解电影票房、口碑等真实情况。
♦ 2) Brainstorming
– listing important application domain concepts – listing their properties/attributes – listing their relationships to each other
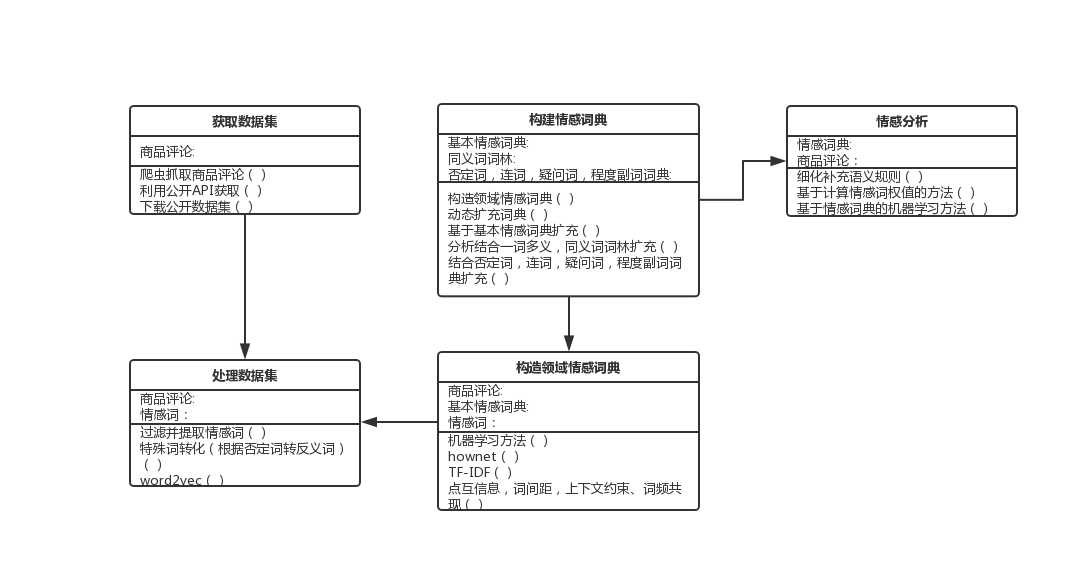
1.获取数据集:本项目所针对的目标是豆瓣影视评论,获取数据集的主要方式有通过网络爬虫技术进行获取、下载公开的数据集或者利用开源的API进行获取。
2.对数据进行预处理:对原始数据进行去重、缺失值填充、分词、去除停用词、词频统计和词性标注,并将文本进行向量化。
3.构建领域情感词典:
第一步: 词典基础部分包括台湾大学中文情感极性词典(NTUSD)、清华大学李军中文褒贬义词典(TSING)、知网情感词典(HOWNET)、Boson情感词典和否定词、停用词、程度副词词典,再加上电影领域的特定词语和网络热词,经过整合去重得到一个褒义词词典和一个贬义词词典;
第二步: 通过经验和对数据集的观察, 人工采集规则, 其中主要的几种规则有: “名词+形容词”及“名词+副词+形容词”、“动名词+形容词”及“动词+名词”等;
第三步: 对语料集进行分句处理, 即以“。”“! ”“?”等对评论文本进行切分;
第四步: 利用分词系统对评论文本进行分词和词性标注, 依据收集到的规则找出新的情感词;
第五步: 根据两个词的共现程度 PMI [10] 判断情感词的情感倾向, 当两个词与基准情感词的 PMI 差值大于某一阈值, 则较大的一方的情感极性为新词的情感极性。
4.构建情感词典:将新词录入基础情感词典中 。
5.情感分析:主要的内容是利用文本分词与领域情感词典的匹配情况,按照特定的匹配规则得到文本的情感值,并且运用LDA模型提取出情感词所对应的主题(特征),得到文本的情感词-情感值-主题词序对
♦ 3) Classifying the domain concepts into:
– classes – attributes / attribute values – relationships
• association, inheritance, aggregation
1.获取数据集:商品评论:爬虫抓取商品评论(),利用公开API获取(),下载公开数据集()。
2.处理数据集:影视评论-去重()、分词()、去停用词()、word2vec()。
3.构建情感词典:基础词典、否定词、停用词、程度副词、电影领域特定词 。
4.构建领域词典:影视评论:基本情感词典:情感词:机器学习方法(),hownet(),TF-IDF(),点互信息,词间距,上下文约束、词频共现()。
5.情感分析:情感词典:商品评论:细化补充语义规则(),基于计算情感词权值的方法(),基于情感词典的机器学习方法()。
♦ 4) Document result using UML class diagram
标签:业务用例 通用 利用 电影 步骤 sso use tin format
原文地址:https://www.cnblogs.com/haorw/p/11919530.html