标签:定义 数据共享 这一 streaming 操作 size res val 如何
累加器:
场景:各种计数问题,这个计算需要在driver端合并。
作用:解决Driver端和Execute端数据共享问题。
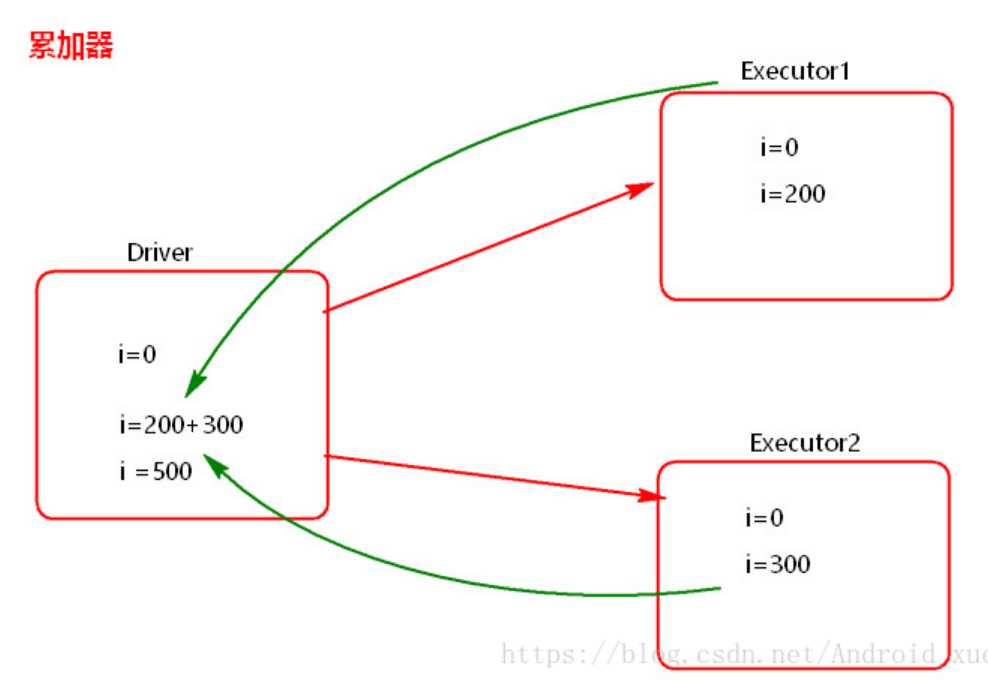
如图,需要将Driver端变量备份到Executor端,那么copy到Executor端的变量一定要是Executor级别的变量。那么如何自定义一个累加器呢,如何将累加器数据类型定义为Executor级别呢?
自定义累加器:
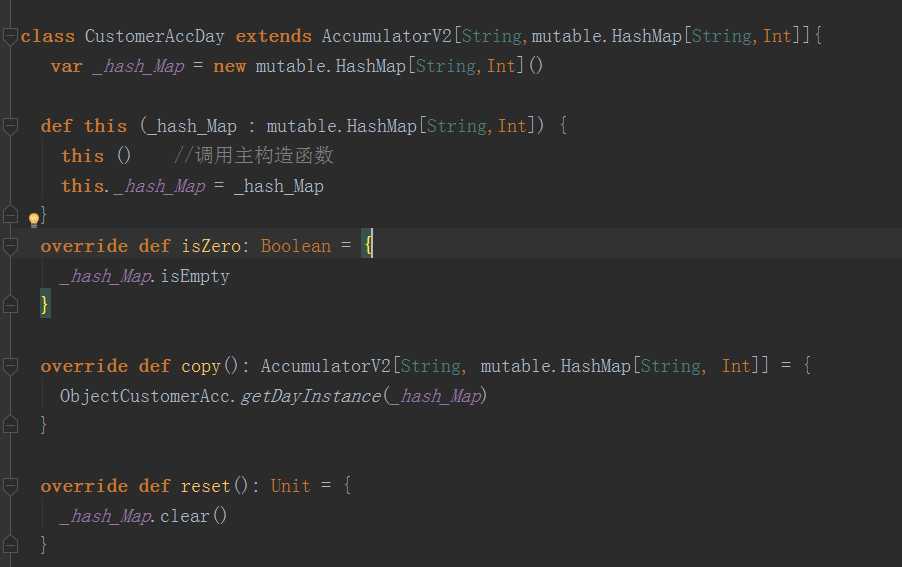
首先要继承AccumulatorV2,然后重写如下6个方法
add方法:指定元素相加。
copy方法:指定了对自定义累加器的复制操作。
isZero方法:返回该累加值是否为0
merge方法:合并两个相同类型的累加器。
reset方法:重置累加器。
value方法:返回累加器当前的值。
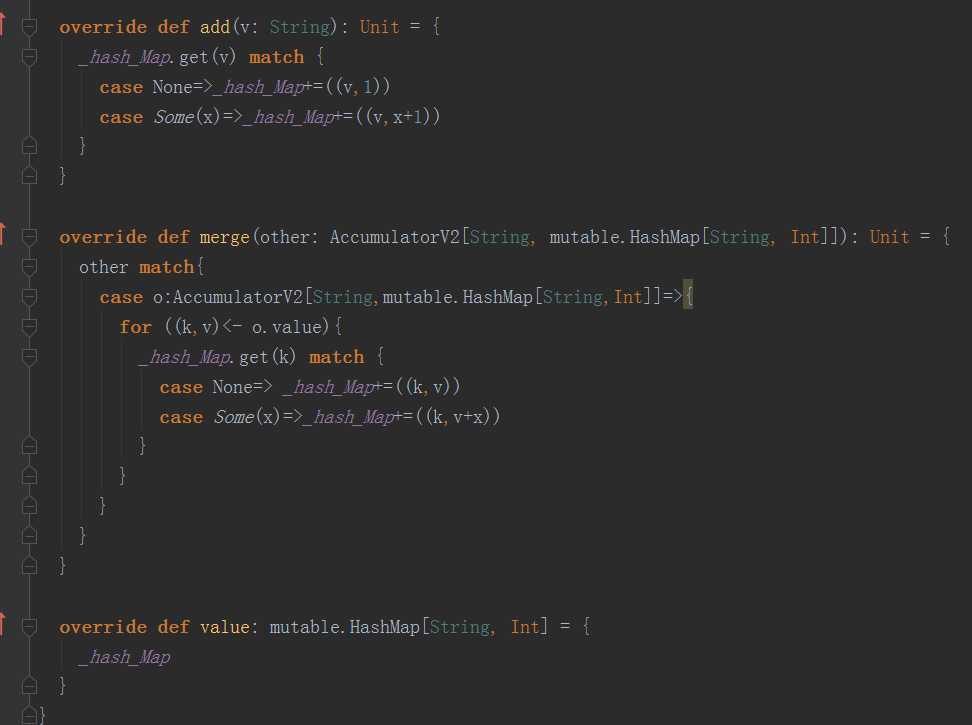
如何保证Executor端的变量级别是Executor级别的呢?
那么就是实现copy方法的时候做如下操作。

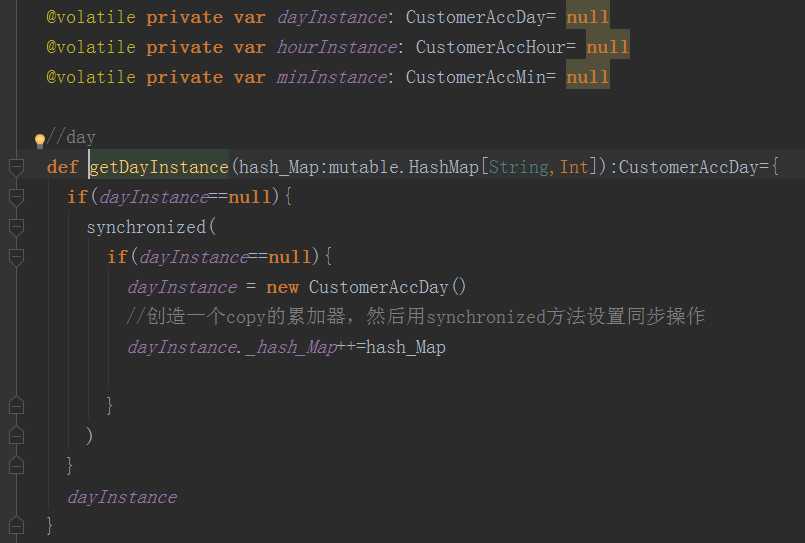
如何在spark streamming程序进行定义呢?
第一行是new 对象,并且通过构造器初始化。
第二行是将累加器注册到sc中,并且起别名为AccumulatorV2Day

如何在spark streamming程序中更新操作呢?
在action算子中进行更新
foreachPartition就是一个action算子。
在其中执行add操作。
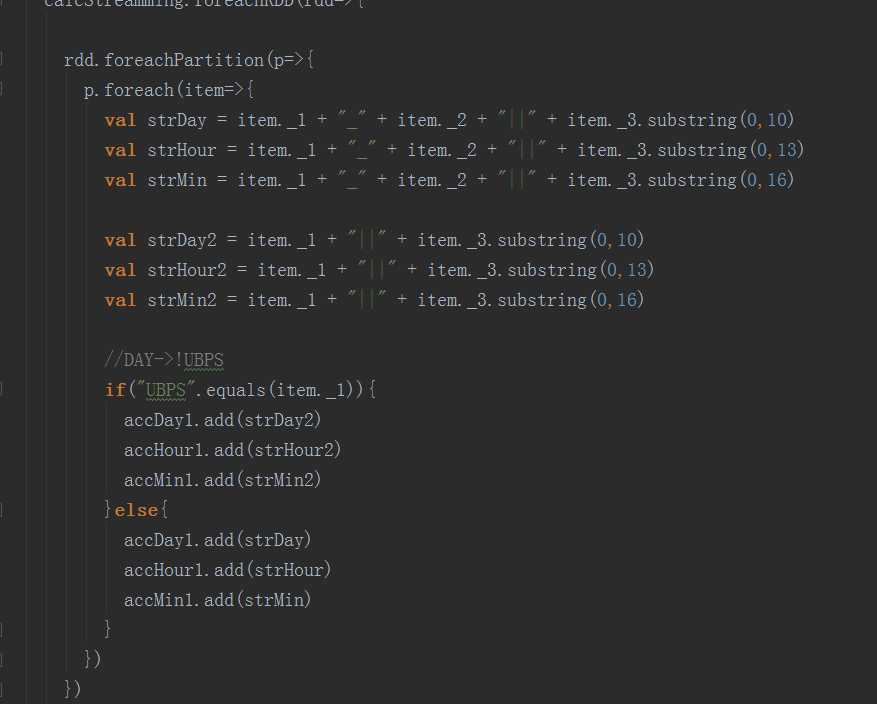
如果获取到累加器value的值呢?将累加器.value写在流级别行吗?
下面这一行代码的位置
累加器.value不能写在这里
DS.foreachRDD(rdd=>{
rdd.forPartition(p=>{
累加器.value不能写在这里
})
累加器.value应该写在这里。
})
累加器.value不能写在这里
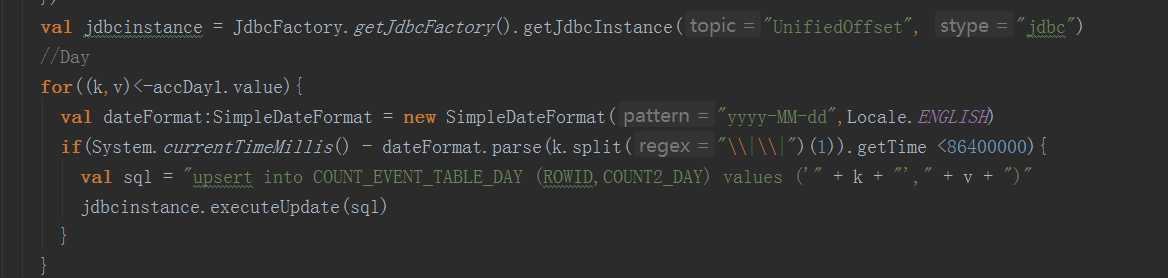
如何在spark streaming UI查看累加器相关数据呢?
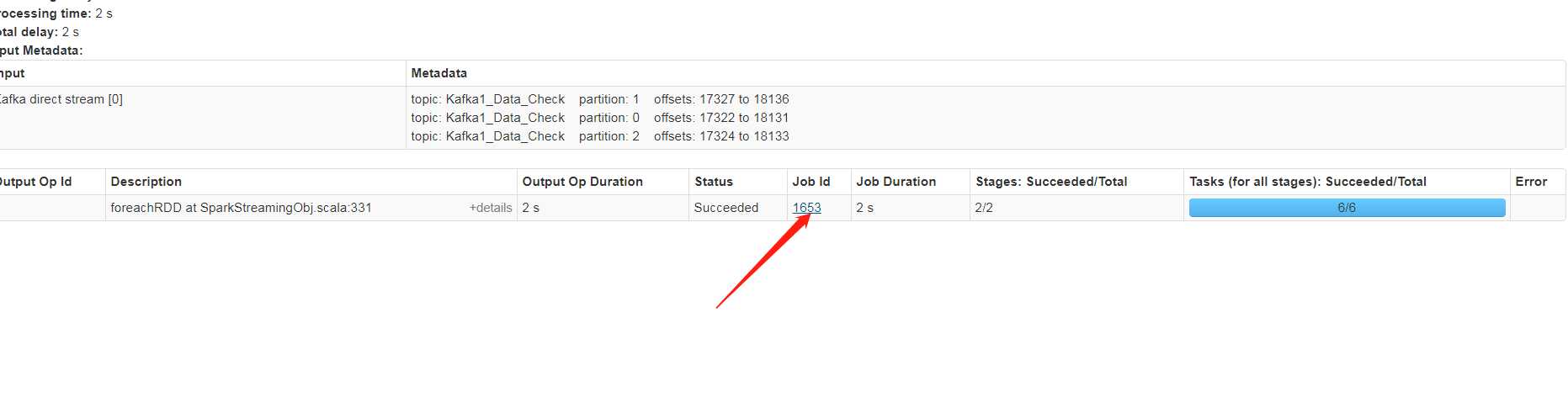
点击有数据的日期

点击1653
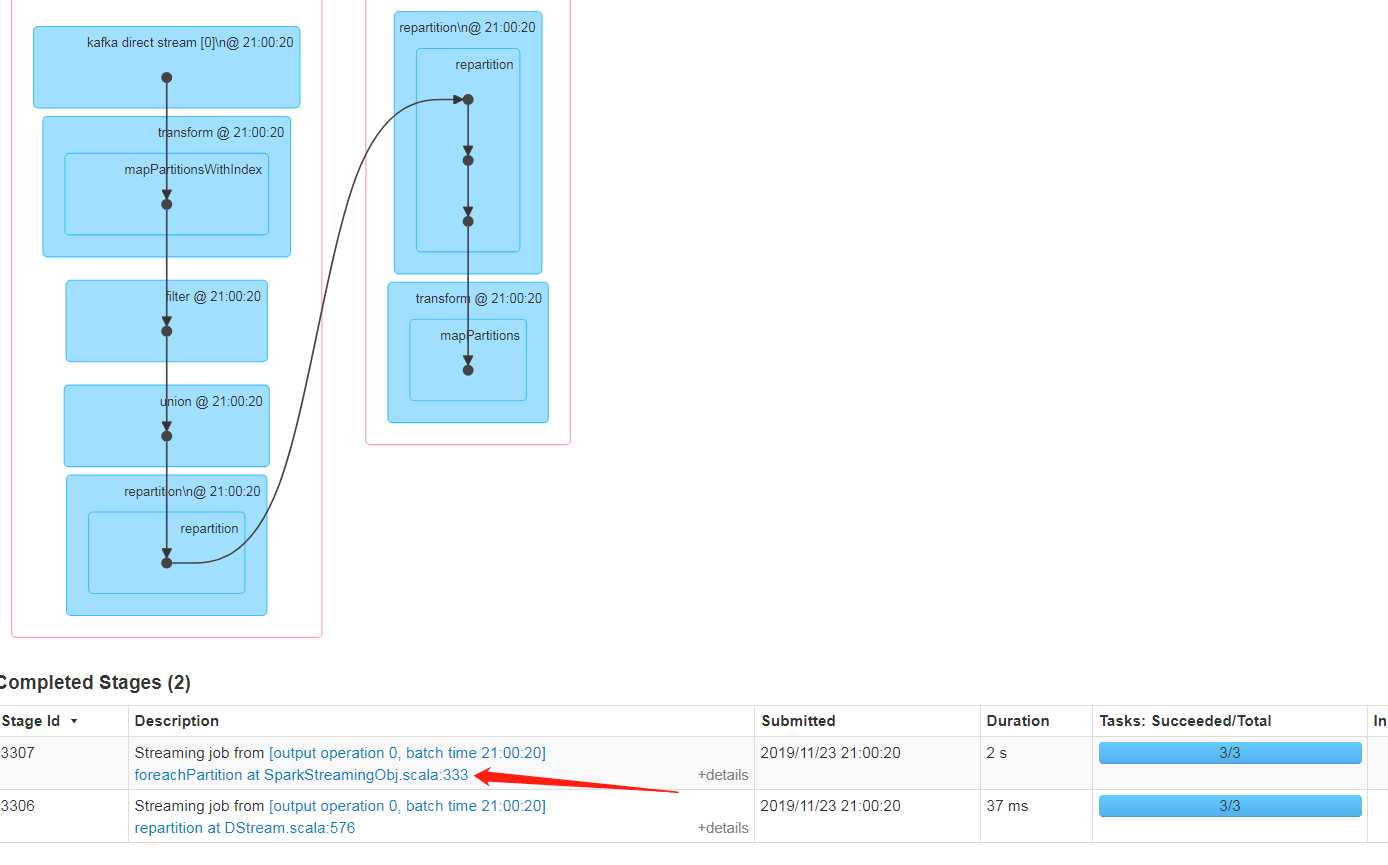
点击图中箭头的地方。
drive端集合后的值

各个分区的累加的值

写的不好,又不对的地方还请指教。
Spark Streamming 共享变量之_ 如何正确使用累加器
标签:定义 数据共享 这一 streaming 操作 size res val 如何
原文地址:https://www.cnblogs.com/BrentBoys/p/11919627.html