标签:img rri 注意力 mic 机制 小技巧 固定 大小 丢失
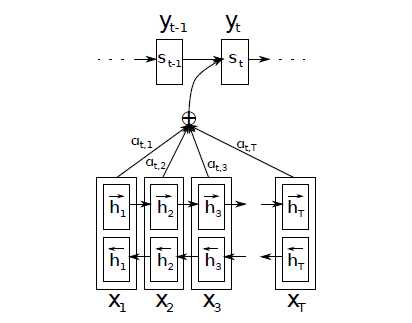
双方向:第\(i\)个输入词对应的隐状态包括了\(\overrightarrow{h}_i\)和\(\overleftarrow{h}_i\),前者编码了\(x_0\)到\(x_i\)的信息,后者编码了\(x_i\)及之后的信息,防止信息丢失
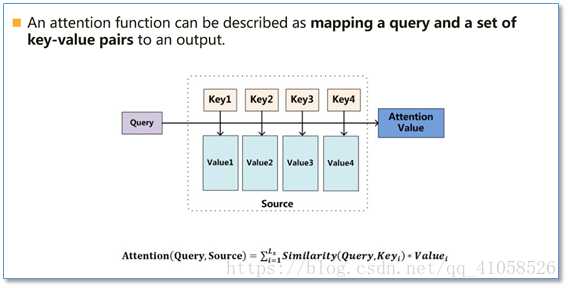
本质:一个查询(query)到一系列(键key-值value)对的映射
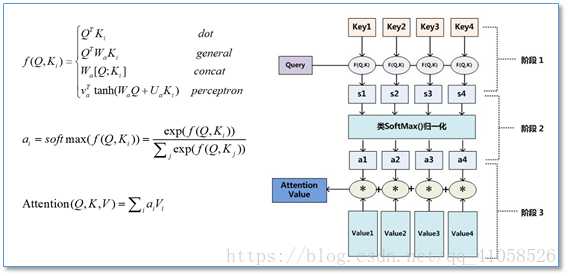
标签:img rri 注意力 mic 机制 小技巧 固定 大小 丢失
原文地址:https://www.cnblogs.com/weilonghu/p/11923017.html