标签:位置 常用 要求 信息 左右 mat 目的 离散化 包含
主席树,又名可持久化线段树,函数式线段树(我也不知道啥意思)。之所以叫主席树是因为发明人黄嘉泰姓名缩写是hjt(知道是谁吧)
首先,可持久化线段树,顾名思义它是持久的,它支持询问过去版本,也就是说在过去某一次操作时的树,那么这怎么实现呢?
例题1:
给你一个长度为\(n\)的数组\(a_1,a_2,...,a_n\),现在有\(m\)次操作:
1.将\(a_i\)变为\(x\)
2.询问在第k次操作后,\(\Sigma_{i=l}^r a_i\)的值
样例输入
4
1000 200 30 4
5
1 3 50
1 2 600
2 0 1 4
2 1 1 4
2 2 1 4样例输出
1234
1254
1654和以往不同,现在询问是对某一次的操作后的序列做询问。
如果用线段树维护区间和,那我们需要存下每次修改完后的线段树。
一个线段树需要 O(n) 的空间,显然不能存下 n 颗线段树,但是我们可以从这里找找突破口。
不妨先考虑最基本的线段树
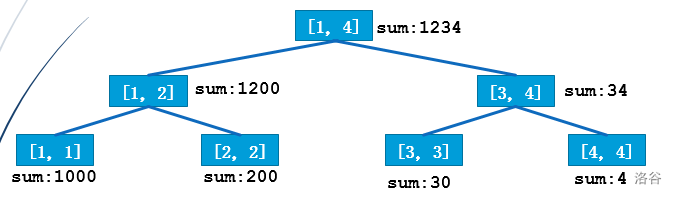
第一次操作:把第 3 个位置改为 50
可以发现的是,这颗线段树和上一颗线段树只有 \(logn\) 个节点发生了变化。
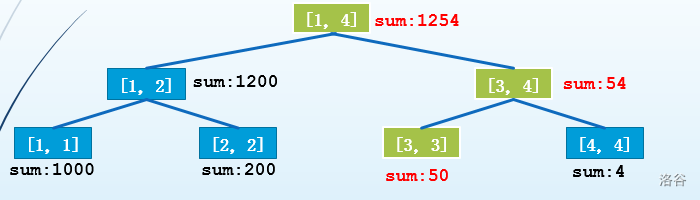
第二次操作:把第 2 个位置改为 600
可以发现的是,这颗线段树和上一颗线段树同样也只有 \(logn\) 个节点发生了变化
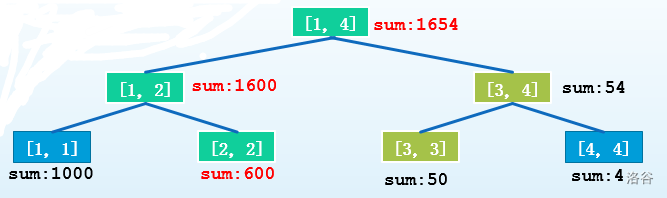
我们发现,每一次单点修改,发生改变的节点只有 \(logn\) 个,就是从根节点到那个点对应的叶节点的路径上的所有节点。
那么对于每次修改,我们只要存下来这新的 \(logn\) 个节点,尽可能的利用上一颗树的信息,就可以存下一颗新的线段树!
对于这棵树来说
第一次操作:把第 3 个位置改为 50。
我们只要新建 log n 个新点,并且尽可能的利用上一颗树的信息。
这就是第一次操作后的线段树。
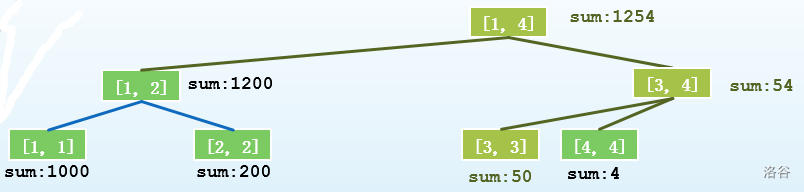
第二次操作:把第二个位置改成50
第二次操作后的线段树
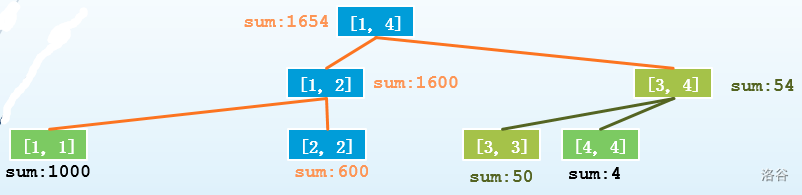
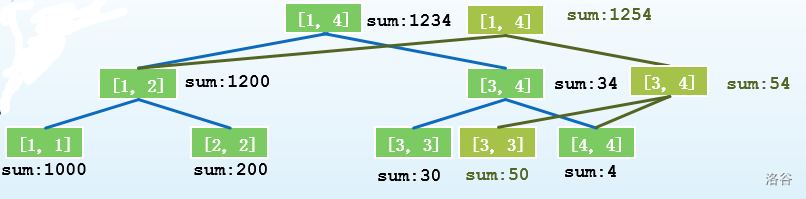
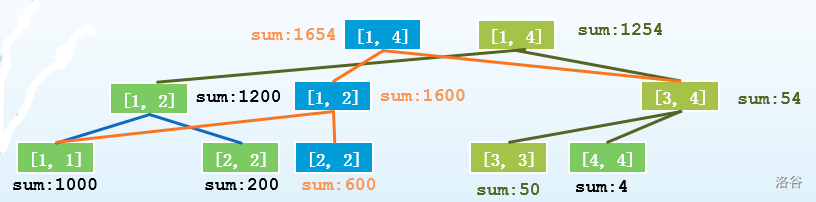
把三棵树都列出来:
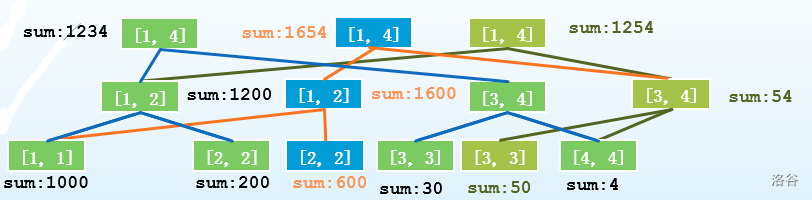
那么我们只需要记录每棵树的根节点,就可以直接查询了
由这个例子可以发现,每次修改操作都会增加\(logn\)个点,所以空间复杂度变成了\(nlogn\),一般开20倍的数组就行了
时间复杂度依旧是\(O(mlogn)\)
注意实现的时候不能用\(2x\)和\(2x+1\)表示左右节点了,所以我们开Ls和Rs数组记录左右儿子
例题2:
如题,你需要维护这样的一个长度为 \(N\) 的数组,支持如下几种操作
此外,每进行一次操作(对于操作2,即为生成一个完全一样的版本,不作任何改动),就会生成一个新的版本。版本编号即为当前操作的编号(从1开始编号,版本0表示初始状态数组)
建树:
void build(int &cnt, int l, int r)
{
cnt = ++iCnt;
if(l == r)
{
iSum[cnt] = iA[l];
return;
}
int mid = (l + r) >> 1;
build(iLs[cnt], l, mid);
build(iRs[cnt], mid+1, r);
}修改:
void ins(int &cnt, int pre, int l, int r, int q, int v)
{
cnt = ++iCnt;
iLs[cnt] = iLs[pre],iRs[cnt] = iRs[pre],iSum[cnt] = iSum[pre];
if(l == r)
{
iSum[cnt] = v;
return ;
}
int mid = l + r >> 1;
if(q <= mid) ins(iLs[cnt], iLs[pre], l, mid, q, v);
if(q > mid) ins(iRs[cnt], iRs[pre], mid+1, r, q, v);
}查询:
int query(int cnt, int l, int r, int q)
{
if(l == r) return iSum[cnt];
int mid = l + r >> 1;
if(q <= mid) return query(iLs[cnt], l, mid, q);
if(q > mid) return query(iRs[cnt], mid+1, r, q);
}完整代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 1000005;
int iRt[N * 20], iSum[N * 20], iLs[N * 20], iRs[N * 20], iCnt, n, m, iA[N];
void build(int &cnt, int l, int r)
{
cnt = ++iCnt;
if(l == r)
{
iSum[cnt] = iA[l];
return;
}
int mid = (l + r) >> 1;
build(iLs[cnt], l, mid);
build(iRs[cnt], mid+1, r);
}
void ins(int &cnt, int pre, int l, int r, int q, int v)
{
cnt = ++iCnt;
iLs[cnt] = iLs[pre],iRs[cnt] = iRs[pre],iSum[cnt] = iSum[pre];
if(l == r)
{
iSum[cnt] = v;
return ;
}
int mid = l + r >> 1;
if(q <= mid) ins(iLs[cnt], iLs[pre], l, mid, q, v);
if(q > mid) ins(iRs[cnt], iRs[pre], mid+1, r, q, v);
}
int query(int cnt, int l, int r, int q)
{
if(l == r) return iSum[cnt];
int mid = l + r >> 1;
if(q <= mid) return query(iLs[cnt], l, mid, q);
if(q > mid) return query(iRs[cnt], mid+1, r, q);
}
int main()
{
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i++) scanf("%d", &iA[i]);
build(iRt[0], 1, n);
for(int i = 1, cnt, opt, x, y; i <= m; i++)
{
scanf("%d%d", &cnt, &opt);
if(opt == 1)
{
scanf("%d%d", &x, &y);
ins(iRt[i], iRt[cnt], 1, n, x, y);
}
else if(opt == 2)
{
scanf("%d", &x);
printf("%d\n", query(iRt[cnt], 1, n, x));
iRt[i] = iRt[cnt];
}
}
}例题3:
给定 \(n\) 个整数构成的序列,将对于指定的闭区间查询其区间内的第 \(k\) 小值。
输入格式
第一行包含两个正整数 \(n,m\),分别表示序列的长度和查询的个数。
第二行包含 \(n\) 个整数,表示这个序列各项的数字。
接下来 \(m\) 行每行包含三个整数 \(l, r, k\), 表示查询区间 \([l, r]\) 内的第 \(k\) 小值。
这个题虽然和上一道看起来没什么关系,但是它也可以用主席树做,具体思想的话就是对数据离散化之后建一棵值域线段树,其中每一个节点存的是在这个节点表示的范围内出现了多少个数,然后按照顺序把序列中的每一个数添加到线段树中并记录历史版本
比如:
4 1
1 3 4 2
2 4 2刚开始先建一棵空树
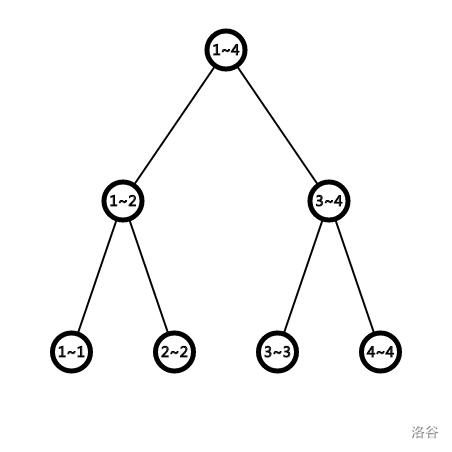
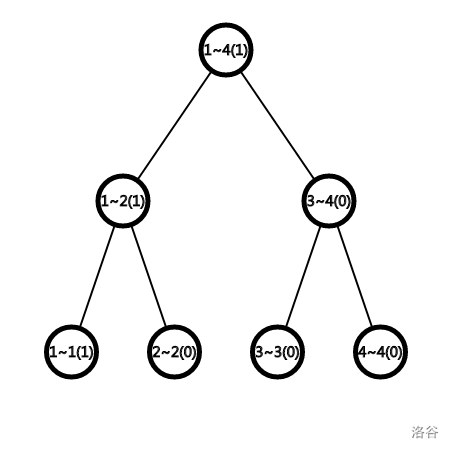
按照顺序一个个添加
Tree1
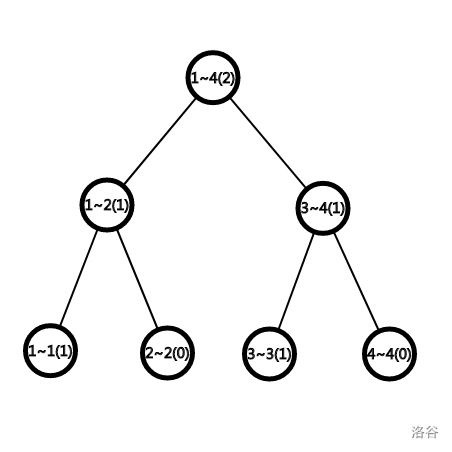
Tree2
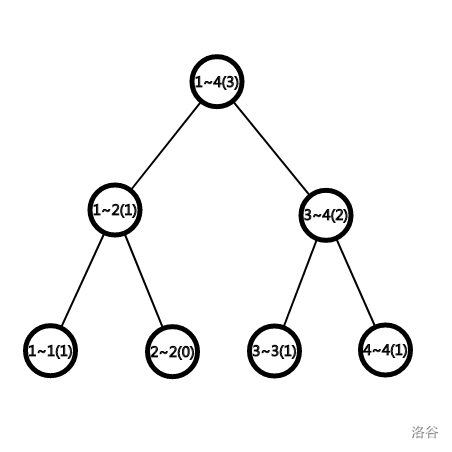
Tree3
Tree4
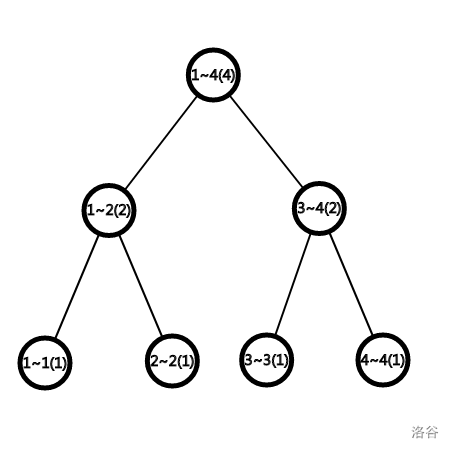
由于主席树的形式比较难画(其实是我懒),这里就不给出了
我们发现由于每个点存的信息是区间和的形式,所以是满足可加减性的
具体来说:
对于样例中的query操作,要求查询区间\([2,4]\)中的第2小值
我们单独把第1棵树和第4棵树取出来
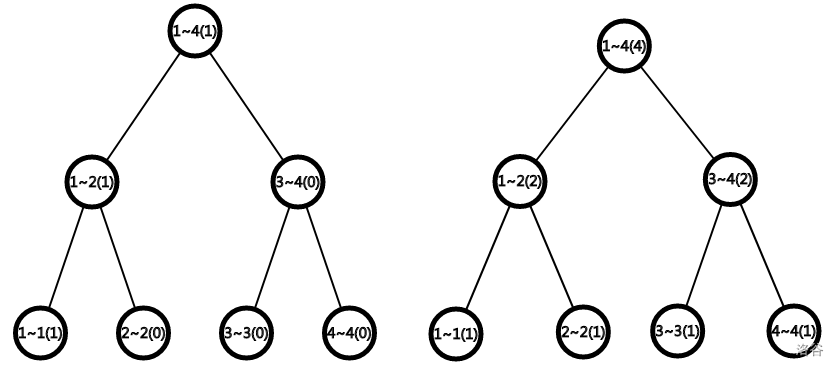
我们观察对应节点的特征。如果把第四棵树的1~4的节点的值和第一棵树1~4的节点的值相减,得到差3,发现3正好是在操作2~4中插入的范围在1~4中的数的个数
同样的,对1~2这个节点做差得到1,1就是在操作2~4中插入的范围在1~2中的数的个数
这就是刚才提到的可加减性
那么这道题的做法自然也就出来了:每一次查询操作\([l,r]\)对第\(l-1\)棵树和第\(r\)棵树做差。记当前节点的左儿子的差为\(\Delta v\)。如果\(k<=\Delta v\),说明第k大的数在左边区间,就到左儿子去寻找,否则就到右儿子去寻找,直到\(l =r\)时返回这个节点的值
int query(int nl, int nr, int l, int r, int k)
{
if(l == r) return iNum[l];
int x = sT[sT[nr].Ls].Val - sT[sT[nl].Ls].Val;
int mid = l + r >> 1;
if(x >= k) return query(sT[nl].Ls, sT[nr].Ls, l, mid, k);
else return query(sT[nl].Rs, sT[nr].Rs, mid+1 , r, k-x);
}完整代码:
#include<bits/stdc++.h>
using namespace std;
const int N = 200005;
int iNum[N], iNumber[N], iCnt, iCntNum;
int iRt[N];
struct sTree
{
int Ls,Rs,Val;
}sT[N*20];
void build(int &cnt, int l, int r)
{
cnt = ++iCnt;
if(l == r) return;
int mid = l + r >> 1;
build(sT[cnt].Ls, l, mid);
build(sT[cnt].Rs, mid + 1, r);
}
void add(int &cnt, int pre, int l, int r, int pos)
{
cnt = ++iCnt;
sT[cnt] = sT[pre];
sT[cnt].Val++;
if(l == r) return;
int mid = l + r >> 1;
if(pos <= mid) add(sT[cnt].Ls, sT[pre].Ls, l, mid, pos);
else add(sT[cnt].Rs, sT[cnt].Rs, mid+1, r, pos);
}
int query(int nl, int nr, int l, int r, int k)
{
if(l == r) return iNum[l];
int x = sT[sT[nr].Ls].Val - sT[sT[nl].Ls].Val;
int mid = l + r >> 1;
if(x >= k) return query(sT[nl].Ls, sT[nr].Ls, l, mid, k);
else return query(sT[nl].Rs, sT[nr].Rs, mid+1 , r, k-x);
}
int main()
{
int n, m;
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i++) scanf("%d", &iNum[i]), iNumber[i] = iNum[i];
sort(iNum + 1, iNum + 1 + n);
iCntNum = unique(iNum + 1, iNum + 1 + n) - iNum - 1;
build(iRt[0], 1, iCntNum);
for(int i = 1; i <= n; i++)
{
int position = lower_bound(iNum + 1, iNum + 1 + iCntNum, iNumber[i]) - iNum;
add(iRt[i], iRt[i-1], 1, iCntNum, position);
}
for(int i = 1, l, r, k; i <= m; i++)
{
scanf("%d%d%d", &l, &r, &k);
printf("%d\n", query(iRt[l - 1], iRt[r], 1, iCntNum, k));
}
return 0;
}例题4:
n个集合 m个操作
操作:
1 a b 合并a,b所在集合2 k 回到第k次操作之后的状态(查询算作操作)3 a b 询问a,b是否属于同一集合,是则输出1否则输出0一看到回到第k次操作之后的状态就可以想到主席树
很自然想到对每一次操作建一棵树,叶子节点存储父亲,然后就是裸的并查集了
然而这里有一个问题:暴力并查集的复杂度是\(O(n^2)\),需要优化
我们想到最常用的路径压缩,但在这里显然是行不通的,因为不断地查询修改会导致复杂度超出限制
所以这道题要选择按秩合并
按秩合并其实是一种启发式合并的思想,就是把含有较少节点的集合合并到含有较多节点的集合,而这个节点个数的表示就在于树的高度,即高度小的树合并到高度大的树,这样就可以防止树的优美性质被破坏,即树退化成链。当两个集合的秩相等的时候,就随便找一个集合合并,然后秩加一。详情可以百度搜索按秩合并
int find(int cnt, int pos)
{
int f = query(cnt, 1, n, pos);
if(pos == iFa[f]) return f;
return find(cnt, iFa[f]);
}
void add(int cnt, int l, int r, int pos)//更新秩
{
if(l == r)
{
iDeep[cnt]++;
return;
}
int mid = l + r >> 1;
if(pos <= mid) add(sT[cnt].Ls, l, mid, pos);
else add(sT[cnt].Rs, mid+1, r, pos);
}小结:
1.主席树的特征就是访问历史版本或者可以通过历史版本达到求解问题的目的
2.主席树的核心思想就是重复利用,这一点在很多题目中都可以见到。当你复杂度超标时不妨想一想有没有什么东西被重复算过,能不能优化这一部分多余的时间
标签:位置 常用 要求 信息 左右 mat 目的 离散化 包含
原文地址:https://www.cnblogs.com/lcezych/p/11923001.html