标签:http 状态 img 效率 重置 控制 code jpg 信息
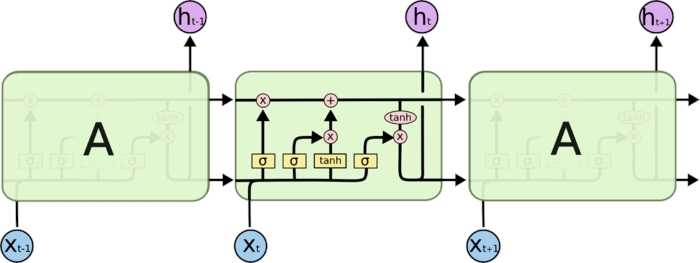
记忆单元\(c_t\):每个单元都有
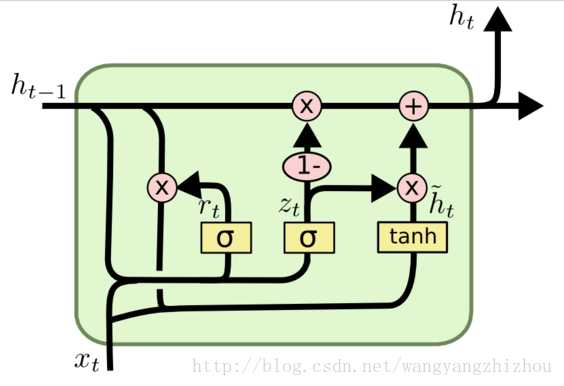
LSTM和GRU
原文地址:https://www.cnblogs.com/weilonghu/p/11922994.html