标签:视频 不同 cal spl cos scale info 中间 来源
视频来源:新竹清华大学:并行计算与并行编程课程
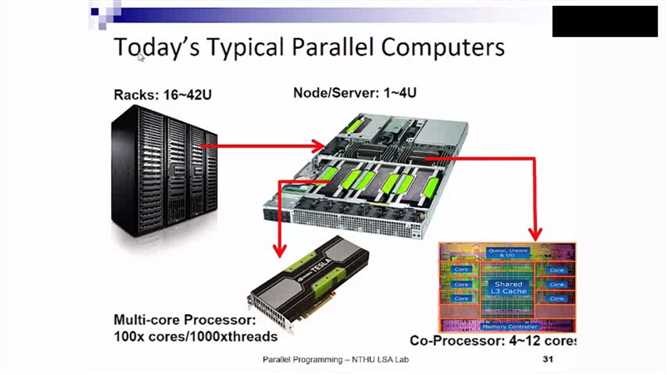
概念: 相比常规计算机 超级计算机 具有高层次的计算能力。 计算能力性能的评估标准 FLOPS, 每秒处理的浮点操作数。
快的原因:(1)最新的硬件技术 (2)软件库的优化 (3) 定制系统的配置 (4)资源及金钱的消耗
通信主要用 infiniband, 计算能力的目标:达到 1EFlop(10^18)/s 即 exascale computing。
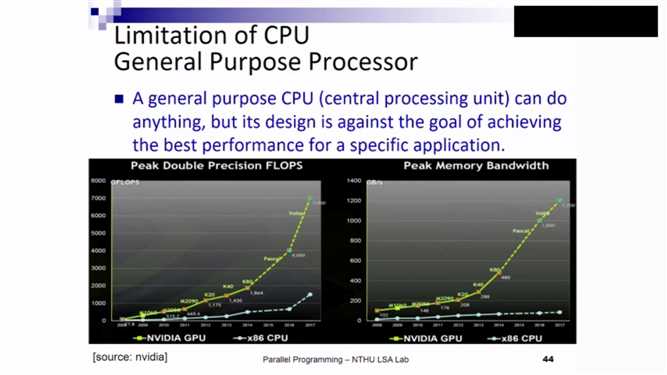
CPU的限制:卡之间的交流及数据的划分也会有性能延时。
GPU架构如下(向量做计算)
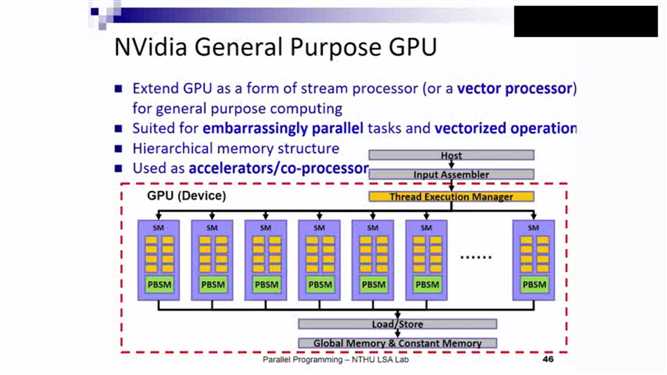
每个processor独有内存,不同processor之间的内存只有通过global memory 进行shared。但二者之间不同内存速度差距很大。
CPU架构如下(element做计算)

TPU(矩阵做计算)

并行计算的网络技术:并行计算性能大部分卡在网络沟通的部分。同时,同步十分棘手。

网络拓扑:
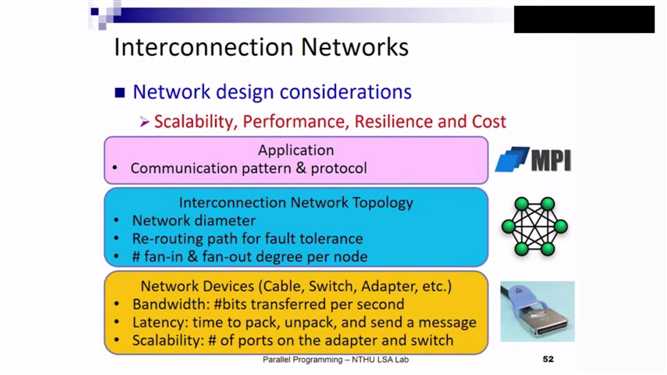
需要进行考虑的因素:规模,性能,弹性,花费
物理底层:网络设备(Cable,Switch,Adapter)带宽:每秒传输的比特。Latency:打包,解包,发送消息所需的时间。Scalability:adapter及switch的接口。
软体网络拓扑:Network diameter,节点最远传输距离(最糟情况),砍掉某个节点后系统的稳定性。每个节点的fan-in 及fan-out。
应用:MPI 交流模式及protocol。
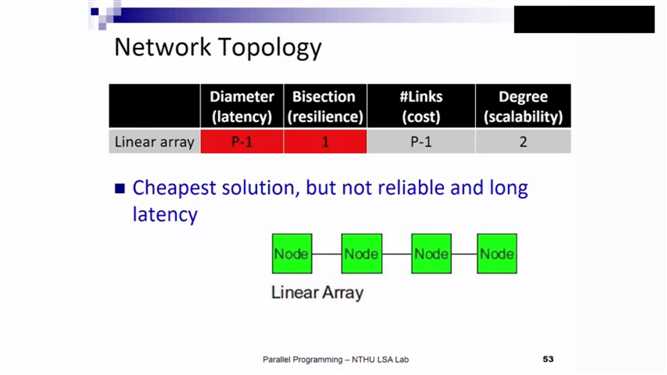
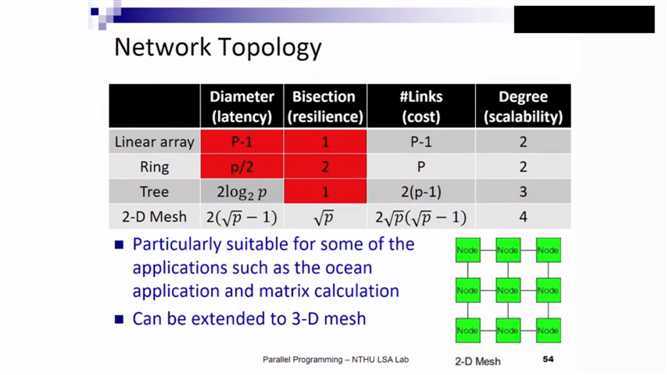
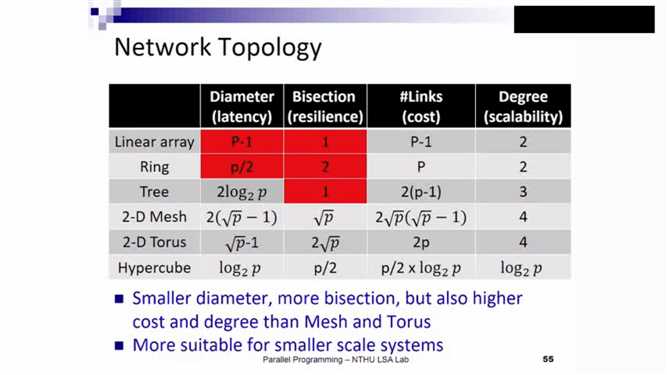
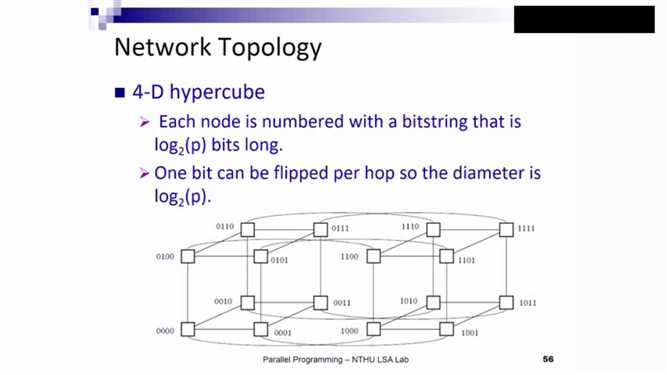
由于Hypercube的cost耗费过多,目前,用的最广的仍是Mesh形态。
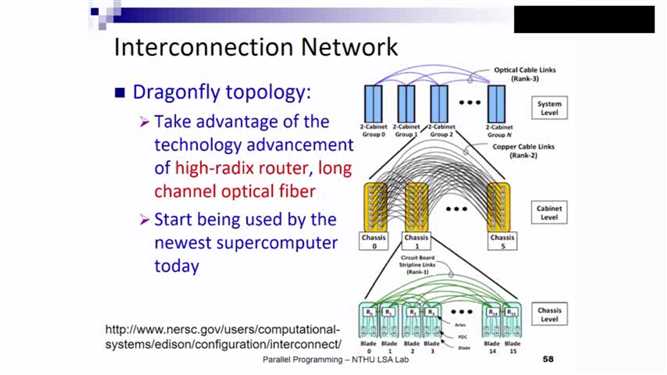
Dragonfly Topology:局部连接更密集,类似蜻蜓的翅膀,纹路密集,局部性能较好,通过单个线与全局进行联系。
InfiniBand:目前最好的 high throughout low latency传输资料的技术。
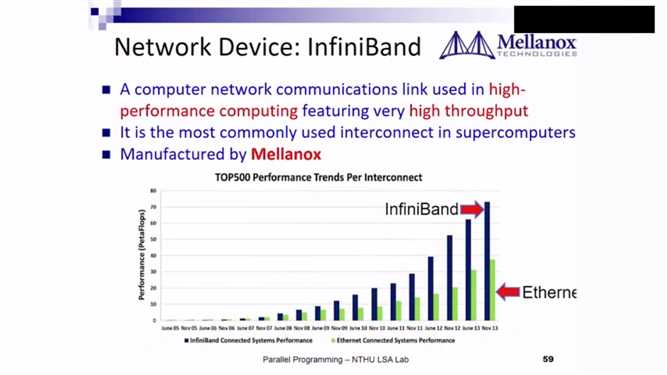
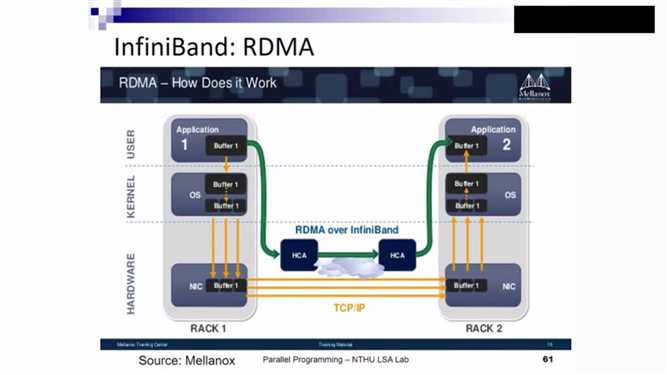
InfiniBand比Ethernet快的原因:二者prototcal 十分不一样,Ethernet传资料时,直接向channel扔,而channel只有一个,易发生冲突,冲突后将资料扔掉,浪费了资源,随着冲突增加,性能降低。而InfiniBand首先是开辟一个空间, 再传资料,没有冲突发生,因此效率会高。同时,可以绕过CPU/OS将资料一次写入远端,节省了中间很多的复制工作。
二者比较图如下

标签:视频 不同 cal spl cos scale info 中间 来源
原文地址:https://www.cnblogs.com/fourmi/p/11922666.html