标签:back round image auto 统计 观测 评分卡模型 splay 效果
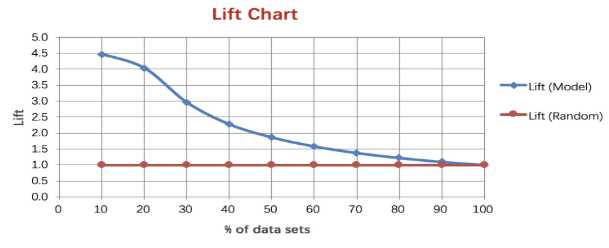
Lift图衡量的是,与不利用模型相比,模型的预测能力“变好”了多少,lift(提升指数)越大,模型的运行效果越好。
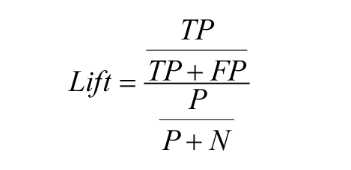
TP:划一个阈值后的正样本。
P:总体的正样本。
在模型评估中,我们常用到增益/提升(Gain/Lift)图来评估模型效果,其中的Lift是“运用该模型”和“未运用该模型”所得结果的比值。以信用评分卡模型的评分结果为例,我们通常会将打分后的样本按分数从低到高排序,取10或20等分(有同分数对应多条观测的情况,所以各组观测数未必完全相等),并对组内观测数与坏样本数进行统计。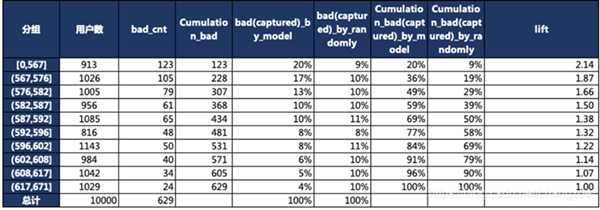
第一行lift值=(123/913)/(629/10000)
第二行lift值=((123+105)/(913+1026))/(629/10000)
标签:back round image auto 统计 观测 评分卡模型 splay 效果
原文地址:https://www.cnblogs.com/gczr/p/11923552.html