标签:个数 href 技术 line print rcu type 数据请求 png
1、请求Headers里
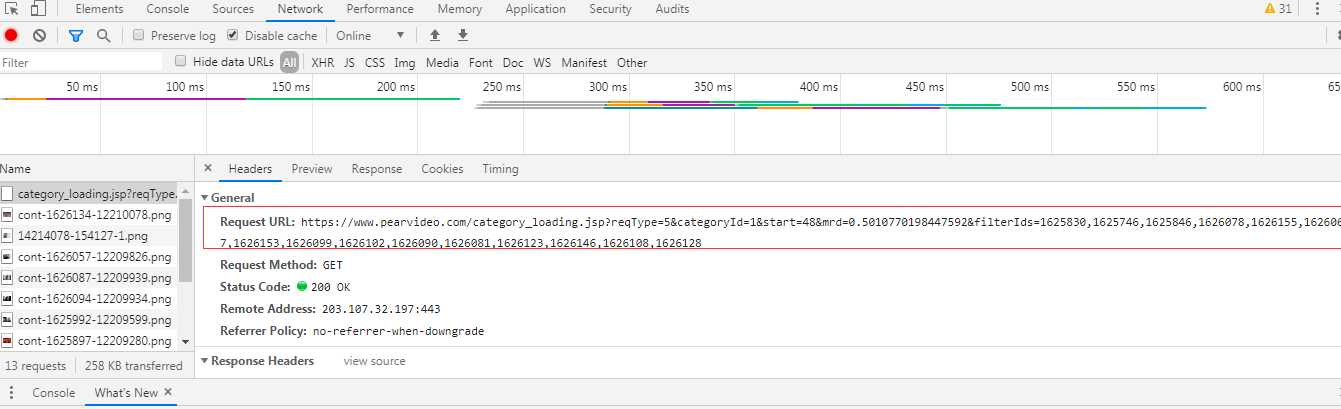
URL请求地址,分析得出加载视频个数
1625830,1625746,等等为加载更多视频过滤条件
2、去除后缀,拿原始链接可以请求数据
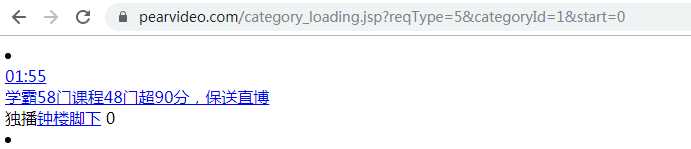
分析得知start=0 为第一个视频
3、查看源代码,下面为真实数据请求地址

4、代码
# 获取视频 import re res = requests.get(‘https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0‘) reg_text =‘<a href="(.*?)" class="vervideo-lilink actplay">‘ obj = re.findall(reg_text,res.text) print(obj) # ‘video_1626266‘列表集合 for url in obj: url = ‘https://www.pearvideo.com/‘+url res1 = requests.get(url) # 获取真实的视频资源请求地址 obj1 = re.findall(‘srcUrl="(.*?)"‘,res1.text) print(obj1) # [‘https://video.pearvideo.com/mp4/adshort/20191125/cont-1626232-14630171_adpkg-ad_hd.mp4‘] name = obj1[0].rsplit(‘/‘,1)[1] print(name) # cont-1626232-14630171_adpkg-ad_hd.mp4 # 发送请求资源 res2 = requests.get(obj1[0]) with open(name,‘wb‘)as f: # 流式保存 for line in res2.iter_content(): f.write(line)
标签:个数 href 技术 line print rcu type 数据请求 png
原文地址:https://www.cnblogs.com/xiaowangba9494/p/11930805.html