标签:成功 tor 随机森林 种子 inf state spl rac 不同
来源: 决策树的思想来源非常朴素,程序设计中的条件分支结构就是if - then 结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
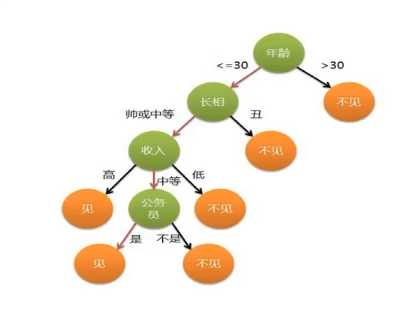
举例:是否见相亲对象
信息的单位: 比特 (bit)

如果不知道任何球队的信息,每支球队得冠概率相等。
以二分法预测,最少需要使用5次才能预测到准确结果。 5 = log32 (以2为底)
5 = -(1/32log1/32 + 1/32log1/32 + ......)
开放一些信息,则小于5bit, 如1/6 德国,1/6 巴西, 1/10 中国
5 > -(1/6log1/4 + 1/6log1/4 + ....)
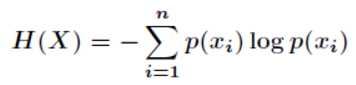
定义: 特征A对训练数据集D的信息增益g(D,A), 定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A) 之差,即:
g(D,A) = H(D) - H(D | A)
注: 信息增益表示得知特征 X 的信息而使得类 Y的信息的不确定性减少的程度。

以不同特征下的信贷成功率为例
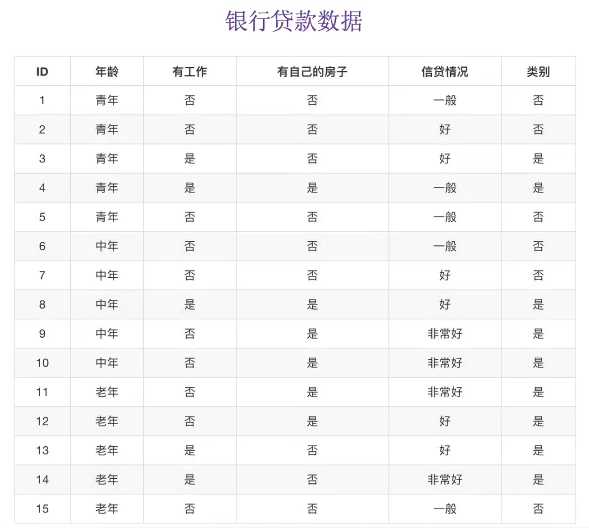
令A1, A2, A3, A4 分别表示年龄,有工作,有房子和信贷情况4个特征,则对应的信息增益为:
g(D,A1) = H(D) - H(D|A1)
其中,g(D,A2) = 0.324 , g(D,A3) = 0.420 , g(D,A4) = 0.363
相比而言,A3特征(有房子)的信息增益最大,为最有用特征。
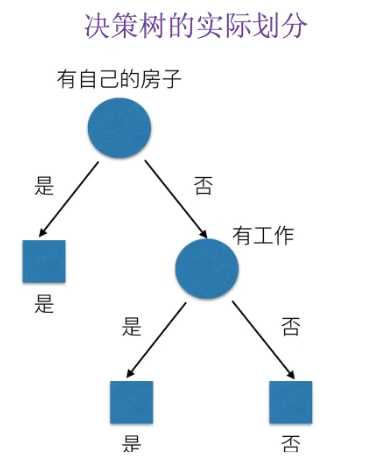
所以决策树的实际划分为:
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
"""
泰坦尼克数据描述事故后乘客的生存状态,该数据集包括了很多自建旅客名单,提取的数据集中的特征包括:
票的类别,存货,等级,年龄,登录,目的地,房间,票,船,性别。
乘坐等级(1,2,3)是社会经济阶层的代表,其中age数据存在缺失。
"""
def decision():
"""
决策树对泰坦尼克号进行预测生死
:return: None
"""
# 1.获取数据
titan = pd.read_csv('./titanic_train.csv')
# 2.处理数据,找出特征值和目标值
x = titan[['Pclass', 'Age', 'Sex']]
y = titan[['Survived']]
# print(x)
# 缺失值处理 (使用平均值填充)
x['Age'].fillna(x['Age'].mean(), inplace=True)
print(x)
# 3.分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 4. 进行处理(特征工程) 特征,类别 --> one_hot编码
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient='records'))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient='records')) # 默认一行一行转换成字典
print(x_train)
# 5. 用决策树进行预测
dec = DecisionTreeClassifier()
dec.fit(x_train, y_train)
# 预测准确率
print("预测的准确率:", dec.score(x_test, y_test))
# 导出决策树
export_graphviz(dec, out_file='./tree.dot', feature_names=['Pclass', 'Age', 'Sex'])
return None
if __name__ == '__main__':
decision()标签:成功 tor 随机森林 种子 inf state spl rac 不同
原文地址:https://www.cnblogs.com/hp-lake/p/11931462.html