标签:补充 随机 一个 杭州 contain data 应该 www 用户
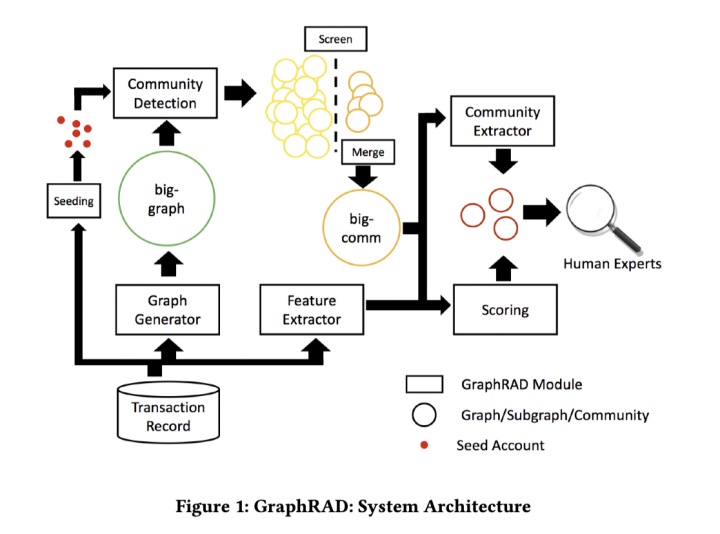
论文:《GraphRAD: A Graph-based Risky Account Detection System》
作者:Jun Ma(Amazon),Danqing Zhang(Berkeley)
来源:MLG ‘ 18
本文介绍Amazon基于图的欺诈交易账户检测系统,相比LOCKINFER 和 OddBall,本文是面向实际业务设计的检测系统,并使用了标签数据。
早期做过十分类似的项目,在可视化关联分析的基础上,为案件调查人员提供智能风险团伙分析服务。所以个人还是比较认可的,在整个系统设计及社区发现模块比较有借鉴价值。
应用场景:黑产通过窃取支付信息在Amazon的在线零售商户购买商品获利。
假设:在“欺诈社区”中欺诈账户间连接紧密,而与社区外的账户连接稀疏。
检测系统目标:给予账户之间关系图和一批黑种子,系统检测出有潜在风险的社区及账户供专家调查。并满足以下特性:
大概思路是:通过最近交易事件提取一批黑种子账户,构建账户之间关系网络,然后识别和过滤社区,然后为社区中节点打分,然后返回结果。
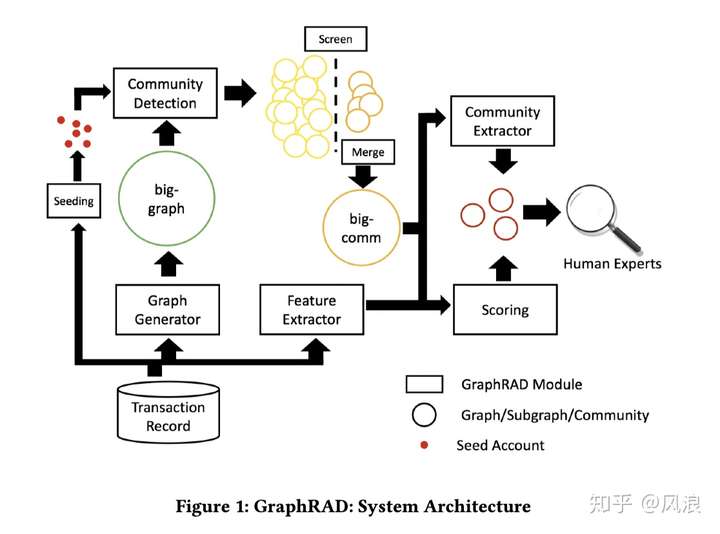
流程介绍:
最后给专家提供社区结构和节点评分以供调查使用。
数据来源:最近的交易事件
例如 有两个交易事件:
因为账户A和账户B共享同一个收货地址,故他们会有一条边,以此来建立账户与账户之间关系网络。
实践中如共享同一个设备、同一个IP都可以作为连边条件。
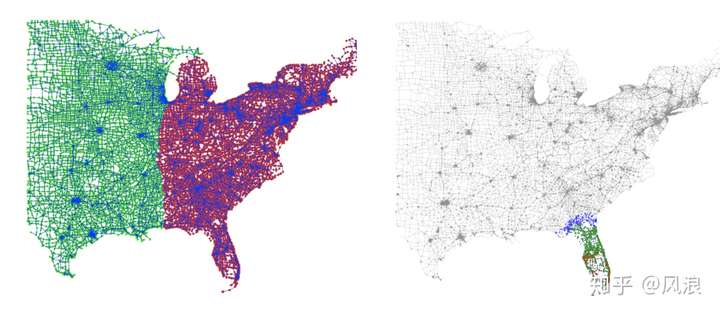
该模块是本文的比较有意思的地方,不是对网络进行全局的划分,而是先以欺诈账户为种子节点,找到每一个种子节点所在的局部社区,然后对这一个个局部社区进行过滤和合并成一个大社区,最后对这大社区进行划分,得到一个个不重叠的社区。
这样做的优势是:
下图比较是直观的一个全局和局部社区发现的对比:
以黑种子节点为输入,使用基于Personal Pagerank局部社区算法ACL,该算法比较经典, 复杂度仅取决于输出结果。
算法使用电阻率(conductance)作为评价指标(模块度是全局的):

后面会补上对ACL的解读。
因为局部社区发现返回的结果是一个个围绕着黑种子的局部社区,必然会有冗余
另外局部社区规模非常小,可能是不存在是个体风险,而不是群体风险。
故需要对局部社区进行过滤,本文是先过滤掉规模较小的局部社区,然后对每个局部社区建一个风险评分模型,再过滤掉风险较低局部社区(y怎么定义用什么特征没仔细说)。
(个人觉得过滤环节不用做太多的操作,简单原则。另外对社区评分模型不好做的,考验泛化能力,还不如用规则)
过滤完后再对这一个个局部社区进行合并,组成一个“大社区“(其实就是将所有节点和边都放在一起)。
因为局部社区发现用的是基于personal pagerank 的方法,可以得到每个节点的一个pagerank 向量,表示节点与其他节点的相似度。将该一个个向量转换成矩阵,并用层次聚类的方法得到最终的社区。 社区数量k的设置控制社区规模,方便专家分析。
在“大社区”上为每个节点打上一个分数,方便专家分析时确定优先级及过滤低评分的节点。
本文对比了Node2vec、GCN和在基于图惩罚项的模型给节点评分,发现基于图惩罚项的模型效果是最好的(也许是样本量有限?按理说应该是GCN好)。
基于图惩罚项的模型即在有监督损失如交叉熵中加入图的惩罚项(相邻节点的预测结果是相近的),这样在训练时不仅考虑了有标签节点,也考虑了无标签的相邻节点,故称为半监督学习。
特征是用了决策引擎中的规则,标签y定义即是否欺诈。
“大社区“
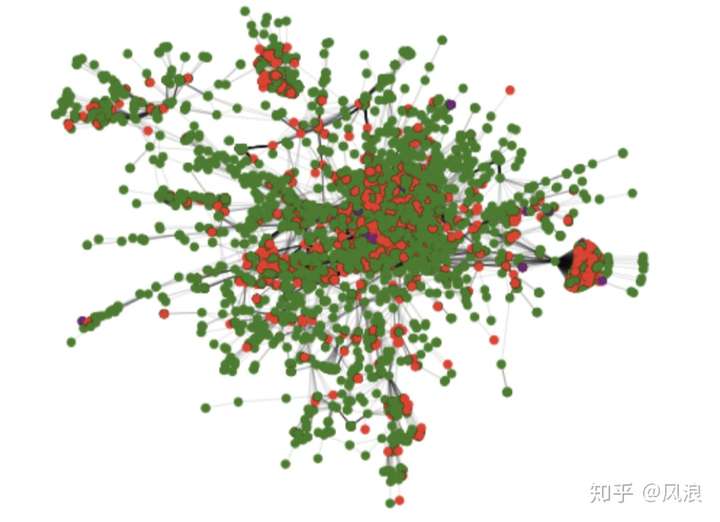
最终返回的一个个社区
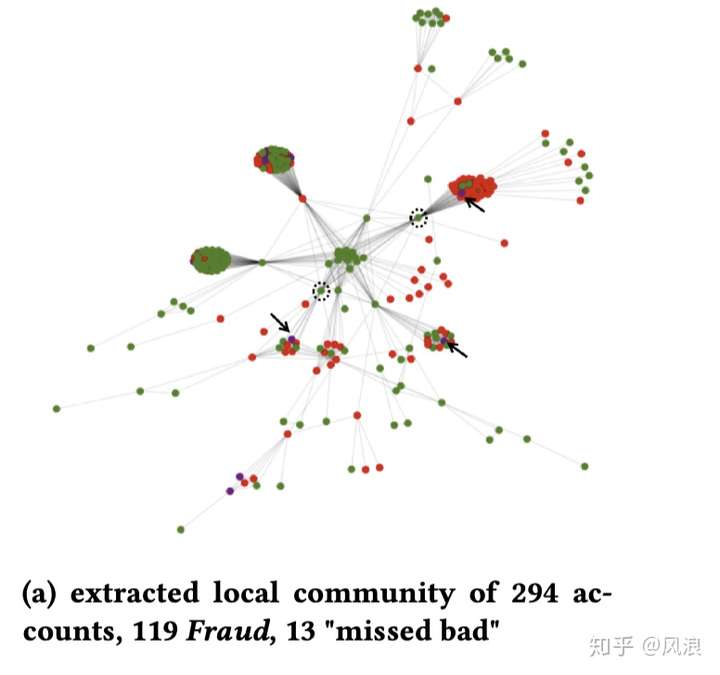
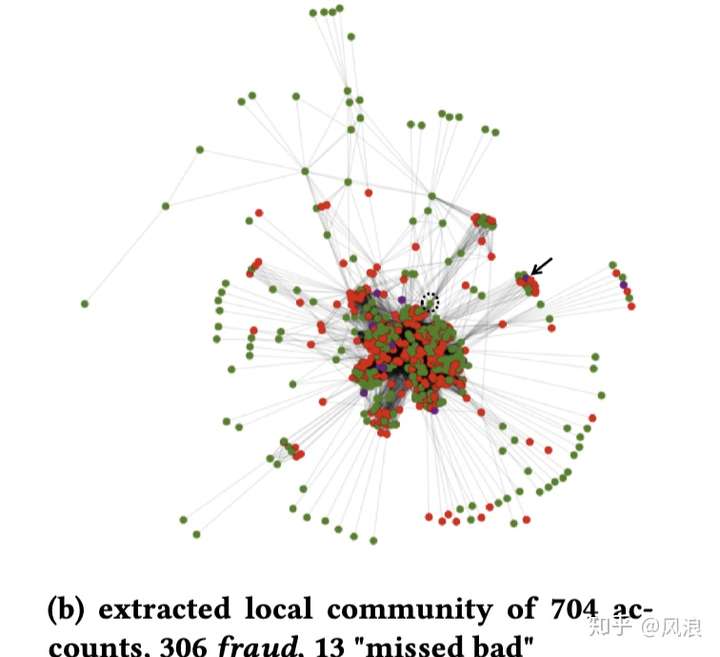
该检测系统目标是 发现更多规则引擎没有发现的欺诈账户,而不是去跟规则引擎去PK,故评价标准是“missed bad” ——检测到的未发现的欺诈账户占比 (通过专家标注,用比例的原因是对于准确率的考量)
首先与随机抽样对比,系统每一个模块的missed bad情况,证明好的系统每一个模块检测比例应该是递增的:
上述模块中的missed bad 没有考虑,被决策引擎判为正常的欺诈账户,故真实结果应该会更高。
另外对比简单规则——欺诈节点直接相连的邻居认为是欺诈的对比,GraphRAD检测还是有比较大的增益的。

标签:补充 随机 一个 杭州 contain data 应该 www 用户
原文地址:https://www.cnblogs.com/bonelee/p/11948963.html