标签:并发 转换问题 分数 vertica alpha ips font 关系 样本
Abstract
许多图像到图像的翻译问题是有歧义的,因为一个输入图像可能对应多个可能的输出。在这项工作中,我们的目标是在一个条件生成模型设置中建立可能的输出分布。将模糊度提取到一个低维潜在向量中,在测试时随机采样。生成器学习将给定的输入与此潜在编码映射到输出。我们明确地鼓励输出和潜在编码之间的连接是可逆的。这有助于防止训练期间从潜在编码到输出的多对一映射也称为模式崩溃问题,并产生更多样化的结果。我们通过使用不同的训练目标、网络架构和注入潜在编码的方法来探索此方法的几个变体。我们提出的方法鼓励了潜在编码模式和输出模式之间的双射一致性。我们提出了对我们的方法和其他变种在视觉真实性和多样性方面进行了一个系统的比较。
1 Introduction
深度学习技术在条件图像生成方面取得了快速的进展。例如,网络已经被用来填补缺失的图像区域[20,34,47],给灰度图像添加颜色[19,20,27,50],并从草图生成逼真的图像[20,40]。然而,这个领域的大多数技术都集中于生成单个结果。在这项工作中,我们模拟一个潜在结果的分布,因为许多这些问题可能是多模态。例如,如图1所示,根据云的模式和光照条件,夜间捕获的图像在白天可能看起来非常不同。我们追求两个主要目标:产生(1)视觉上真实的和(2)多样化的结果,同时保持对输入的忠实。

从高维输入到高维输出分布的映射具有挑战性。表示多模态的一种常用方法是学习一个低维潜在编码,它应该表示输入图像中不包含的可能输出的各个方面。在推理时,确定性生成器使用输入图像和随机采样的潜在编码来产生随机采样的输出。现有方法的一个常见问题是模式崩溃[14],即只有少量的实际样本在输出中得到表示。我们系统地研究了这个问题的一系列解。
我们从pix2pix框架[20]开始,它已经被证明可以为各种图像到图像的翻译任务提供高质量的结果。该方法训练一个基于输入图像的生成器网络,有两个损失:
(1)一个回归损失,产生与已知成对真实图像相似的输出;
(2)一个可学习的判别器损失,以获得真实感。
作者注意到,随意附加一个随机抽取的潜在编码不会产生不同的结果。相反,我们建议鼓励输出和潜在空间之间的双射。我们不仅执行将潜在编码(以及输入)映射到输出的直接任务,而且还联合学习从输出返回到潜在空间的编码器。这将阻止两个不同的潜在编码生成相同的输出(非单射映射)。在训练期间,可学习的编码器试图传递足够的信息到生成器,以解决任何关于输出模式的歧义问题。例如,当从夜间图像生成白天图像时,潜在向量可能编码关于天空颜色、地面灯光效果和云模式的信息。按顺序组合编码器和生成器将导致恢复相同的图像。相反的应该产生相同的潜在编码。
在这项工作中,我们通过探索几个目标函数来实例化这个想法,灵感来自于无条件生成建模的文献:
cVAE-GAN(条件变分自动编码器GAN):一种方法是首先将真实图像编码到潜在空间中,给生成器一个有噪声的“peek”到期望的输出中。使用这个“peek”连同输入图像,生成器应该能够重建特定的输出图像。为了保证在测试时间内可以使用随机抽样,利用kl散度对潜在分布进行正则化,使其接近标准正态分布。这种方法在VAEs[23]和VAE-GANs[26]的无条件设置中得到了推广。
cLR-GAN(条件潜在回归GAN):另一种方法是首先向生成器提供一个随机绘制的潜在向量。在这种情况下,产生的输出看起来不一定像真实图像,但它应该看起来是真实的。然后编码器尝试从输出图像中恢复潜在向量。该方法可视为“潜回归模型”的条件式[8,10],也与InfoGAN[4]有关。
BicycleGAN:最后,我们将这两种方法结合起来,在两个方向上加强潜在编码和输出之间的联系,从而提高性能。我们证明了我们的方法可以在大量的图像转换问题中产生多样化和视觉上吸引人的结果,明显比其他基线更多样化,包括在pix2pix框架中添加噪音。除了损失函数外,我们还研究了几种编码器网络的性能,以及将潜在代码注入生成器网络的不同方法。
我们对这些变量进行了系统的评估,使用人来判断图片真实感和使用感知距离度量[52]来评估输出的多样性。代码和数据可以通过https: //github.com/junyanz/BicycleGAN.
2 Related Work
Generative modeling 生成模型. 自然图像分布的参数化建模是一个具有挑战性的问题。传统上,这个问题是通过使用受限的Boltzmann机器[41]和自动编码器来解决的[18,43]。变分自编码器[23]提供了一种有效的方法,使用训练时网络中潜在分布的重新参数化构建的随机性。另一种不同的方法是自回归模型[11,32,33],该模型对自然图像统计建模有效,但由于其序列预测特性,在推理时速度较慢。生成对抗网络[15]克服了这一问题,它将随机值从一个简单的样本分布(例如,一个低维高斯分布)映射到网络的单个前向传播的输出图像中。在训练过程中,使用判别器网络对样本进行判断,判别器网络将样本从目标分布和生成器网络中区分出来。GANs最近非常成功[1、4、6、8、10、35、36、49、53、54]。我们的方法建立在VAE[23]和InfoGAN[4]或潜在回归因子[8,10]的条件模型的基础上,共同优化它们的目标。我们将在3.4节中重新讨论这种联系。
Conditional image generation条件图像生成. 上述所有方法都可以简单地条件化。虽然有条件的VAEs[42]和自回归模型[32,33]已经显示出了该方法的希望[16,44,46],图像到图像的有条件的GANs已经导致了结果质量的显著提高。然而,这种质量是以牺牲多模态为代价获得的,因为在相关的上下文条件下,生成器学会了在很大程度上忽略随机噪声向量[20,34,40,45,47,55]。事实上,甚至有研究表明,忽略噪音可以得到更稳定的训练[20,29,34]。
Explicitly-encoded multimodality显式编码的多模态. 表达多模态的一种方法是显式编码,并将其作为输入图像之外的额外输入提供。例如,在iGAN [54], pix2pix [20], Scribbler[40]和交互式着色[51]中,使用了颜色和形状涂鸦等界面作为条件设置。并发工作[2,3,13]探索的一个有效的设置是使用混合的模型。这些方法虽然可以产生多个离散的答案,但不能产生连续的变化。虽然在无条件和文本条件设置中生成多模态输出已经取得了一定程度的成功[7,15,26,31,36],但条件图像到图像的生成仍然远远达不到同样的结果,除非像上面讨论的那样进行显式编码。在这项工作中,我们学习了条件图像生成模型,通过加强潜在空间和图像空间之间的紧密联系来建模多种模式的输出。
3 Multimodal Image-to-Image Translation
我们的目标是学习两个图像域之间的多模态映射,例如,边缘和照片,或日夜图等等。考虑输入域A⊂RH×W×3,被映射到一个输出域B⊂RH×W×3。在训练中,我们从这两个领域给出了一个数据集的配对实例,{(A∈Α, B∈B)},代表一个联合分布p (A, B)。重要的是要注意,可能会有多个合理的配对实例B将对应一个输入实例A,但训练数据集通常只包含一个这样的一对。然而,在测试期间给定一个新的实例A,我们的模型应该能够生成一组不同的输出B^’s,对应于分布p(B| A)中的不同模式。
虽然条件GANs在图像到图像的转换任务中取得了成功[20,34,40,45,47,55],但它们主要局限于在给定输入图像A的情况下生成一个确定性的输出B^。
另一方面,我们想要学习可以从给定A的真正的条件分布中采样输出B^,并且产生的结果是多样的和真实的。为此,我们学习了一个低维潜在空间z∈RZ,它封装了不表现在输入图像中的输出模式中的模糊方面。例如,鞋子的草图可以映射到各种颜色和纹理,这些颜色和纹理可以在这个潜在编码中被压缩。然后,我们学习了到输出的一个确定性映射G:(A, z)→B。为了使随机抽样成为可能,我们希望从先验分布p(z)中提取潜码向量z;在这项工作中我们使用一个标准的高斯分布N (0,I)。
我们首先讨论对现有方法的简单扩展,并讨论其优缺点,从而推动我们在后续小节中提出的方法的发展。
3.1 Baseline: pix2pix+noise (z → B^)
最近提出的pix2pix模型[20]在图像到图像的转换设置中显示了高质量的结果。它使用条件对抗网络[15,30]来帮助产生感知上真实的结果。GANs通过将它们的目标设定为对抗性游戏来训练生成器G和判别器D。判别器试图区分数据集中的真实图像和生成器生成的虚假样本。随机绘制的噪声z被加入试图诱导随机性。我们在图2(b)中说明了这个公式,并在下面描述它。
![]()
为了鼓励生成器的输出匹配输入并稳定训练过程,在输出和真实图像中使用L1损失函数:
![]()
最终的损失函数添加上GAN和L1术语和参数λ:
![]()
在这种情况下,几乎没有激励生成器利用编码随机信息生成的噪声矢量。Isola等人的[20]注意到,噪声在初步实验中被生成器忽略,在最终实验中被去除。这与[29,34]在条件设置下的观察结果一致,也与无条件情况下观察到的模态崩塌现象一致[14,39]。在本文中,我们探索了不同的方法来显式地强制潜在编码捕获相关信息。
3.2 Conditional Variational Autoencoder GAN: cVAE-GAN (B → z → B^ )
迫使潜在代码z的一个方法是“有用”的即使用一个编码函数E直接映射真实图像B到z。生成器G使用潜在编码z和输入图像A合成所需的输出B^。整体模型可以很容易理解为中间带着潜在编码z与成对的A连接得到的B的重构 —— 类似于一个自动编码器[18]。图2(c)给出了更好的解释。
该方法已成功地应用于无对抗目标的无条件变分自编码器[23]中。扩展到有条件的情况下,潜在编码z的分布Q(z | B)使用带着高斯假设的编码器E来获得,Q (z | B) = E (B)。为了反映这一点,将公式1修改为使用重构参数技巧对z∼E(B)进行采样,允许直接反向传播[23]:
![]()
我们还对等式2中的L1 损失项进行了相应的更改,从而得到L1VAE(G) = EA,B∼p(A,B),z∼E(B)||B−G(A, z)||1。此外,E(B)编码产生的潜在分布被限制在接近随机高斯分布的情况下,以便在推理时对未知的B进行采样。
![]()
KL散度为:
![]()
然后形成了cVAE-GAN的目标函数,即VAE-GAN的有条件版本:
![]()
作为基线,我们还考虑了此方法的确定性版本,即,去掉KL散度,编码z = E(B)。我们称之为cAE-GAN,并在实验中进行了对比。由于cAE-GAN不能保证潜在空间z的分布,使得z的测试时间采样变得困难。
3.3 Conditional Latent Regressor GAN: cLR-GAN (z → B^ → z^ )
我们探索了另一种使用嵌入z的潜在编码的强制生成器网络方法,同时保持接近实际测试时间分布p(z),但是从潜在编码的角度接近的。如图2(d)所示,我们得到一个随机绘制的潜在编码z并试图恢复z^ = E (G (A, z))。注意,这里的编码器E是生产z^点估计的,而在前一节中的编码器则是用于一个高斯分布预测:
![]()
还包括了在B^上使用的判别器损失LGAN (G, D)(公式1中),鼓励网络生成真实的结果,完整的损失可以写成:
![]()
不使用真实图像B的L1损失。噪声向量是随机产生的,因此预测的B^不一定需要贴近真实图像,但需要是真实的。上述目标函数与“潜在回归”模式(4、8、10)相似,生成的样本B^被编码生成一个潜在向量。
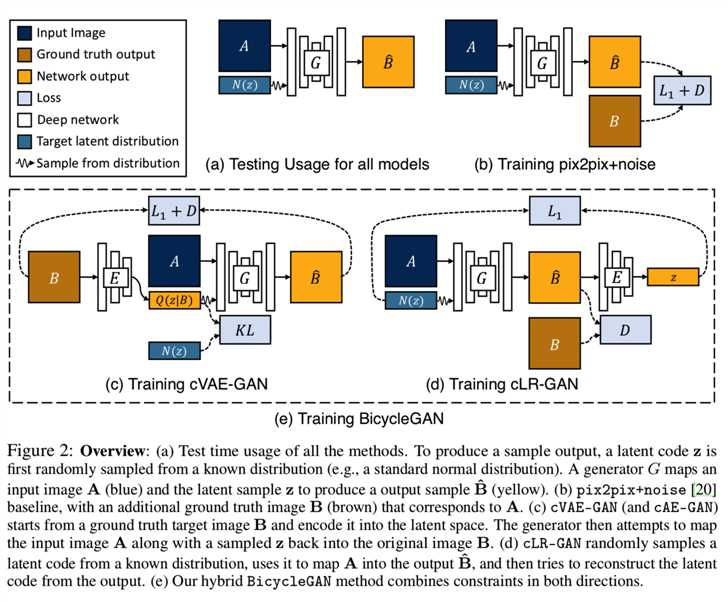
3.4 Our Hybrid Model: BicycleGAN
我们将cVAE-GAN和cLR-GAN的目标结合在一个混合模型中。对于cVAE-GAN,编码是从真实数据中学习的,但随机潜在编码在测试时可能不会产生真实的图像—KL损失可能没有得到很好的优化。也许更重要的是,对抗分类器D在训练中没有机会看到前一次采样的结果。在cLR-GAN中,潜在空间很容易从一个简单的分布中采样,但是对生成器进行训练时没有看到真实的输入-输出对的好处。我们建议训练时使用两个方向上的约束,旨在利用两个周期(B→z→B^和z→B^→z^),因此得到BicycleGAN名称:
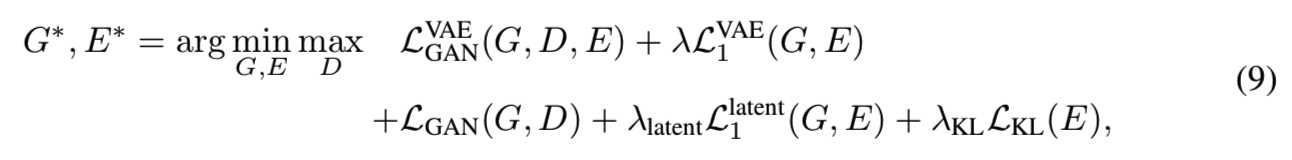
超参数λ、λlatent和λKL用来控制每项的相对重要性
Larsen等人发现,在无条件GAN环境中,使用来自之前的N (0, I)分布和编码的E (B)分布的样本能进一步改善结果。因此,我们还报告了一种变体,即上面所示的完整目标函数(公式9),但没有在潜在空间L1latent的重建损失。我们称它为cVAE-GAN++,因为它是基于cVAE-GAN的,带有一个额外的损失LGAN(G, D), 1个,让判别器可以看到从先前随机抽取的样本。
4 Implementation Details
代码和附加结果可以在https://github.com/junyanz/ BicycleGAN上找到。有关数据集、体系结构和训练程序的详细信息,请参阅我们的网站。
Network architecture网络结构. 对于生成器G,我们使用U-Net[37],它包含一个具有对称跳跃连接的编码器-解码器架构。当输入和输出对之间存在空间对应关系时,该结构在单模态图像预测设置中产生了较好的结果。对于判别器D,我们使用了两个不同尺度的PatchGAN判别器[20],其目的是预测70×70和140×140重叠图像块的真假。对于编码器E,我们用两个网络进行了实验:(1)ECNN: 带有几个卷积和下采样层的CNN和(2)EResNet:一个带有几个残差块的分类器[17]。
Training details训练细节. 我们在最小二乘GANs (LSGANs)变体[28]上建立模型,该模型使用最小二乘目标代替交叉熵损失。LSGANs通过稳定的训练产生高质量的结果。我们还发现,不将判别器D设置在输入A上可以得到更好的结果(也在[34]中讨论过),因此选择对所有方法执行相同的操作。在我们所有的实验中设置了参数λimage = 10,λlatent = 0.5和λKL = 0.01。我们在cVAE-GAN和cLR-GAN模型中为生成器和编码器设置了权重。对于编码器,在cLR-GAN中只使用预测平均值。我们观察到,使用两个独立的判别器与共享权重相比,会产生更好的视觉效果。在保持E不变的情况下,我们只更新了潜在编码(公式7)上的L1损失L1latent(G, E)。我们发现同时优化G和E的损失会鼓励G和E隐藏潜在编码的信息而不学习有意义的模式。我们使用Adam[22]从零开始训练我们的网络,批量大小为1,学习率为0.0002。我们选择所有数据集的潜在维度|z| = 8。
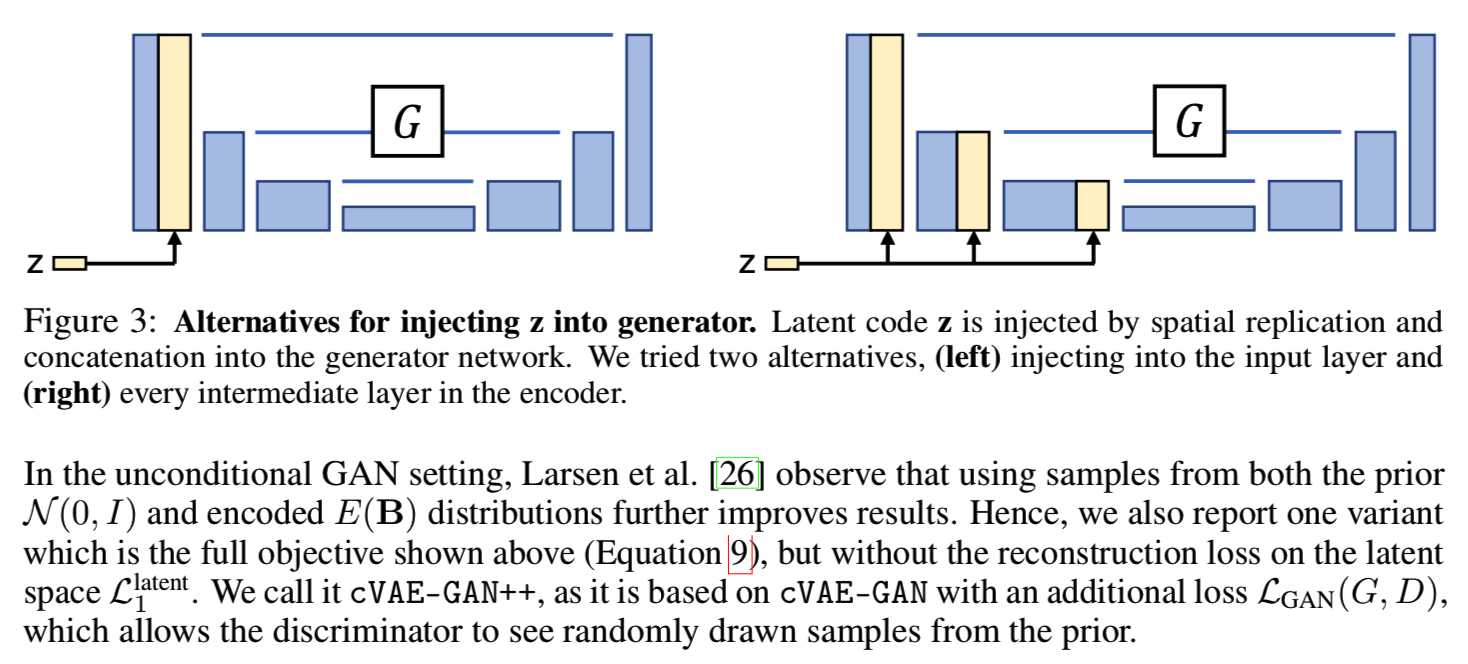
将潜在编码z注入生成器。我们探索两种传播潜在编码z到输出的方式,如图3所示:
(1)add_to_input:我们空间复制Z-dimensional的潜在编码z成一个H×W×Z大小的张量,将它与H×W×3大小的输入图像连接
(2)add_to_all:在空间复制到适当的大小后,我们添加z到网络G的每个中间层。
5 Experiments
数据集. 我们测试了之前工作中的几个图像到图像的转换问题,包括边缘→照片[48,54],谷歌地图→卫星[20],标签→图像[5],户外夜间→白天图像[25]。这些问题都是一对多的映射。我们对所有模型进行256×256图像的训练。
方法. 对第3节中描述的模型进行评估:pix2pix+noise, cAE-GAN, cVAE-GAN, cVAE-GAN++, cLR-GAN,和我们的混合模型BicycleGAN。

5.1 Qualitative Evaluation
我们在图5中显示了定性比较结果。我们观察到,pix2pix+噪音通常产生一个单一的真实输出,但不产生任何有意义的变化。cAE-GAN增加了输出的变化,但通常以很大的成本来保证结果的质量。关于facades的示例如图4所示。

我们在cVAE-GAN中观察到更多的变化,因为潜在空间被鼓励对有关真实输出的信息进行编码。然而,该空间的密度并不高,因此随机抽取样本可能会在输出中产生伪影。cLR-GAN的输出变化较小,有时会出现模式崩溃。然而,在混合这些方法后,在BicycleGAN中观察到的结果既多样又真实。请查看我们的网站,以获得完整的结果。
5.2 Quantitative Evaluation
我们对我们的六个变量和基线的多样性、现实性和潜在空间分布进行了定量分析。我们定量测试了谷歌地图→卫星数据集。
多样性. 我们计算深度特征空间中随机样本的平均距离。预训练的网络在图像生成应用中被用作“感知损失”[9,12,21],以及作为生成建模中保留的“验证”分数,例如评估生成模型[39]的语义质量和多样性,或灰度化[50]的语义准确性。
在图6中,我们使用[52]1提出的LPIPS度量来显示多样性得分。对于每个方法,计算1900对随机生成的输出B^(从100个输入图像中采样得到)之间的平均距离图像。对于B∈B域中真实图像的随机对,平均变异量为.262。因为我们是测量样本B^对应于一个特定的输入A,系统为了保证忠实于输入得到的输出B^应该不超过.262这一点。
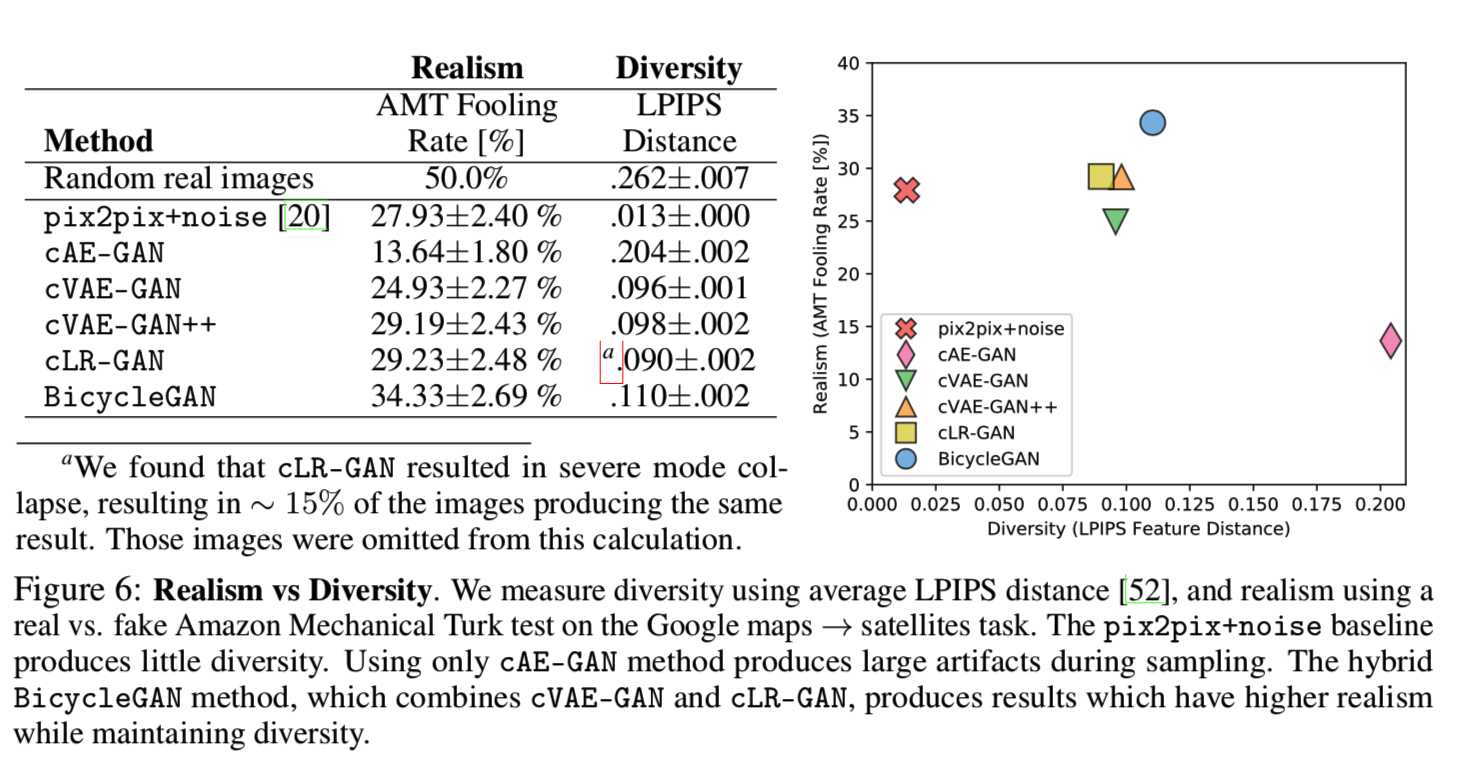
pix2pix系统[20]产生一个单点估计值。向系统中添加噪声, pix2pix+noise会产生一个较小的多样性分数,这证实了在[20]中添加噪声不会产生较大的变化。使用cAE-GAN模型将一个真实图像B编码为一个潜在编码z确实增加了变异。cVAE-GAN、cVAE-GAN++、和BicycleGAN模型都对潜在空间进行了显式约束,而cLR-GAN模型通过抽样对潜在空间进行了隐式约束。这四种方法都产生相似的多样性得分。我们注意到,多样性得分高也可能意味着产生了非自然的图像,导致了无意义的变化。接下来,我们将研究样本的视觉真实感。
视觉真实性. 为了判断我们结果的视觉真实性,我们使用人类的判断,如[50]中提出的,后来在[20,55]中使用。测试按随机顺序向受试者展示一幅真实生成的图像,每幅1秒钟,要求受试者识别假图像,并测量“欺骗”率。图6(左)显示了方法之间的真实性。pix2pix+noise模型获得了很高的真实感分数,但是没有很大的多样性,正如前面所讨论的。cAE-GAN有助于产生多样性,但这是以视觉真实性为代价的。由于习得潜在空间的分布不明确,随机样本可能来自该空间的无人区。在潜在空间中加入kl散度损失,用于cVAE-GAN模型,恢复视觉真实感。此外,正如预期的那样,在cVAE-GAN++模型中检查随机绘制的z向量会略微增加真实感。cLR-GAN从预先定义的分布中随机抽取z向量,生成类似的真实度和多样性得分。然而,cLR-GAN模型导致了大模式崩溃——大约15%的输出产生了与输入图像无关的相同结果。完整的BicycleGAN得到了最好的两个结果,因为它没有遭受模式崩溃,也有最高的真实性得分的显著优势。
编码器结构. 在pix2pix中,Isola等人[20]对判别器和生成器进行了广泛的ablation研究。在这里,我们关注两个编码器架构的性能,ECNN和EResNet,应用于maps和facades数据集。我们发现,对于验证数据集上的图像重建损失||B−G(A, E(B))||1, EResNet对输出图像进行了更好的编码,如表1所示。我们在最终的模型中使用了EResNet。

注入潜在编码方法. 对于相同的重构损失||B−G(A, E(B))||1,我们评估了两种注入潜在编码z的方式:add_to_input和add_to_all (第4节有讲)。表1显示了两种方法具有相似的性能。这表明U_Net[37]可以很好地将信息传播到输出,而不需要从z中添加额外的跳跃连接。在最终的模型中我们使用了add_to_all方法来注入噪音
潜在编码长度. 我们研究图7中BicycleGAN模型结果关于潜在编码{2,8,256}维数的变化。一个非常低维的潜在代码可能会限制可以表达的多样性的数量。相反,一个非常高维的潜在代码可能会对输出图像的更多信息进行编码,代价是使采样变得困难。z的最佳长度在很大程度上取决于单独的数据集和应用程序,以及输出中有多少歧义。

6 Conclusions
综上所述,我们评估了几种解决条件图像生成中模式崩溃问题的方法。我们发现,通过组合多个目标来鼓励潜在空间和输出空间之间的双射映射,我们获得了更加现实和多样化的结果。我们看到了许多未来工作的有趣途径,包括直接在潜在空间中执行一个分布,该分布对语义上有意义的属性进行编码,从而允许使用用户可控制的参数进行图像到图像的转换。
BicycleGAN: Toward Multimodal Image-to-Image Translation - 1 - 论文学习,成对数据
标签:并发 转换问题 分数 vertica alpha ips font 关系 样本
原文地址:https://www.cnblogs.com/wanghui-garcia/p/11733605.html