标签:接下来 mic receiver 有一个 man mit stream 启动 信息
Spark Streaming应用也是Spark应用,Spark Streaming生成的DStream最终也是会转化成RDD,然后进行RDD的计算,所以Spark Streaming最终的计算是RDD的计算,那么Spark Streaming的原理当然也包含了Spark应用通用的原理。Spark Streaming作为实时计算的技术,和其他的实时计算技术(比如Storm)不太一样,我们可以将Spark Streaming理解为micro-batch模式的实时计算,也就是说Spark Streaming本质是批处理,就是这个批处理之间的时间间隔是非常的小,这个时间间隔最小是500ms,基本上可以适合企业中80%的实时计算场景。
在实时计算的步骤中,Spark Streaming当然也包含了实时接收数据过程、数据的transformation过程以及数据结果输出过程三个最基本的过程。Spark Streaming在数据接收的部分包括基于Receiver模式以及Direct模式(Kafka Direct),接下来详细的讲解下基于Receiver模式的Spark Streaming应用的原理。
当我们使用spark-submit提交一个Spark Streaming应用的时候,向集群申请到资源并且初始化需要的Executor后,Spark Streaming应用的执行过程包括两部分:一个是StreamingContext的初始化,一个是Spark Streaming应用对Receiver实时接收到的数据的实时计算。以下分别介绍
StreamingContext的初始化:
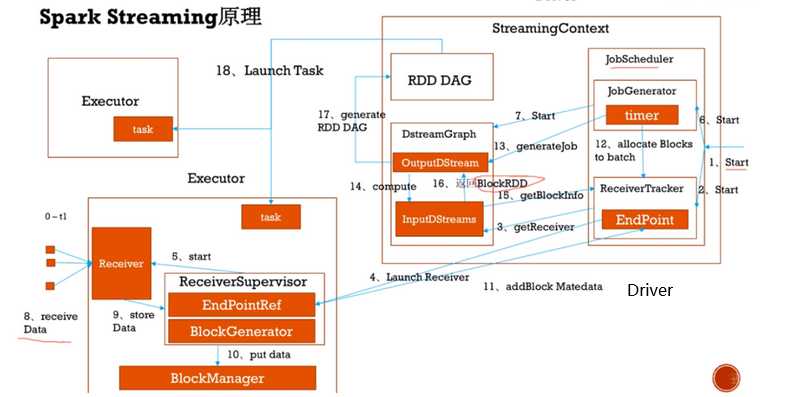
StreamingContext的初始化的时候,会初始化DStreamGraph和JobScheduler两个模块,其中DStreamGraph包含了InputDStream和OutputDStream两个DStream,InputDStream中包含了Receiver信息,OutputDStream包含了最终结果的输出信息,这两个DStream之间就是一系列的业务Transformations。JobScheduler中包含了JobGenerator和ReceiverTracker,JobGenerator中有一个定时器,用于定时的触发并生成批次定时任务,ReceiverTracker用于跟踪Receiver接收的数据,当ReceiverTracker初始化的时候会从DStreamGraph中InputDStream拿到Receiver,然后在一个Executor上启动这个Receiver,至此StreamingContext的初始化完成
Spark Streaming应用对Receiver实时接收到的数据的实时计算
Receiver将实时接收到的数据存储在Executor的内存中,由BlockManager管理,存储完数据后会告诉ReceiverTracker数据块存储的位置,方便ReceiverTracker跟踪定位;当我们设定的batch interval时间到了的时候,JobGenerator就会告诉ReceiverTracker定位所有这个batch interval收集到的数据,并且生成一个定时任务,这个定时任务就会根据ReceiverTracker定位到的所有的数据块生成一个BlockRDD(这个是RDD链中的第一个需要执行的),并且根据InputDStream和OutputDStream两个DStream之间的一系列的业务Transformations生成RDD链,最后生成RDD DAG,进行RDD的计算任务的提交,这个时候就来到了Spark RDD的任务提交的原理的,可以参考Spark Core中的内容
Spark Streaming应用中每一个batch interval中接收到的数据组成的RDD有多少个分区。
BlockRDD的分区数(或者说并行度) = batch interval / block interval
其中batch interval就是我们初始化StreamingContext的时候指定的批处理时间间隔
block interval是指接收到的数据生成数据块的时间间隔,这个时间间隔可以通过spark.streaming.blockInterval来配置,默认是200ms,这个值最小可以设置为50ms
SparkStreaming运行原理
标签:接下来 mic receiver 有一个 man mit stream 启动 信息
原文地址:https://www.cnblogs.com/tesla-turing/p/11959342.html