标签:lob server memory family hdfs gic tor perl 信息
HBase特点
1)海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
2)列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3)极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
4)高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5)稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
HBase的数据模型
HBase中的数据是以表的形式组织起来的,每张表都有自己属于的namespace(你可以把namespace看作Mysql中的数据库),表默认的话是创建在default这个namespace中。HBase中的表其实是一个类似于三层Map结构的模型,如下图:
一个Table中包含很多的rowKey,每一个rowkey就是对应着一行(row)数据;每一行数据包含了若干个列(column),每一个列由一个column family(列蔟)和column qualifier(列名)组成,当然column qualifier可以为空;每一个列包含了若干个版本的数据值,这个版本默认是数据插入时的服务器时间戳,版本数默认是1个,当然版本以及版本的数量是可以设置的。
HBase的架构
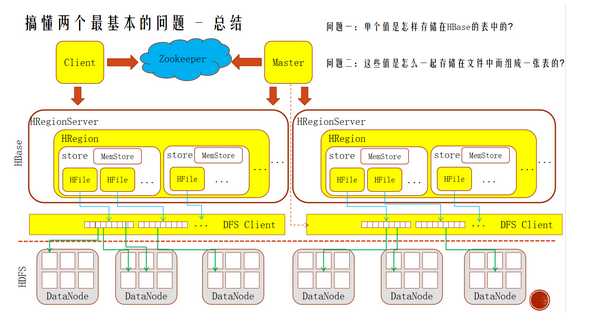
HBase也是遵守主从架构的技术,由一个主HMaster和若干个从HRegionServer组成。HBase中的一张表的数据由若干个HRegion组成,也就是说每一个HRegion负责管理一张表中的一段数据,HRegion都是分布式的存在于HRegionServer中(也就是说一个HRegionServer是管理多个HRegion的进程),所以说HRegion是HBase表中数据分布式存储的单位。那么一个HRegion中又是由若干个column family的数据组成(HRegion对应的表有几个column family,那么HRegion中就管理几个column family的数据);在HRegion中每个column family数据由一个store管理,每个store包含了一个memory store和若干个HFile组成,HFile的数据最终都会落地到HDFS文件中,所以说HBase依赖HDFS,存在HBase中的数据最终都会落地到HDFS中。
在HBase中还有一部分元数据信息,比如HMaster的状态信息、HRegionServer的状态信息以及HRegion的状态信息等,这些信息都是存储在zookeeper集群中,zookeeper集群在HBase中处于一个分布式协调服务的角色,客户端要连接HBase集群的话,也是直接连接zookeeper集群即可,客户端可以在zookeeper中找到需要和HBase的哪一个进程通讯。
Hfile
HBase依赖HDFS,存在HBase中的数据最终都会落地到HDFS中,HBase中的数据在HDFS中就是以HFile这种格式的文件组织起来的。一个HFile包含了若干个不同类型的Block,每一个Block的大小通常为8K到1M(默认是64K);Block的类型有Data Blocks、Index Blocks、Bloom filter Blocks以及Trailer block,一个Data Block包含一个magic数字和若干个KeyValue的数据。Index Blocks是记录每一个Data Block的数据位置(就是索引信息)用于随机读写
查看HFile内容:hbase org.apache.hadoop.hbase.io.hfile.HFile -f hfile_name
HBase的读写缓存机制
写缓存机制:所有的数据先写入到Memory Store中,如果Memory Store所占的内存符合下面的规则的话,则会将数据flush到磁盘中:
(1)、当一个Region中所有MemoryStore内存之和大于hbase.hregion.memstore.flush.size(默认大小是:134217728字节(128M))的时候,这个MemoryStore所在的Region中的所有MemoryStore都会写到磁盘
(2)、当一个HRegionServer中所有的MemoryStore加在一起的大小大于hbase.regionserver.global.memstore.upperLimit默认大小是堆内存的40%,那么这个HRegionServer中的所有的Region中的内存数据都会flush到磁盘中,当所有的内存使用达到
hbase.regionserver.global.memstore.lowerLimit的时候就不会flush了
读缓存机制:读缓存策略包含两种,一种是LruBlockCache,一种是BucketCache,其中默认是使用LruBlockCache
LruBlockCache是使用LRU的算法实现的缓存策略
如果要使用BucketCache的话,需要配置开启,BucketCache一般和LruBlockCache配合使用,配合使用的方式有两种:
(1)、LruBlockCache用于缓存Index和Bloom这种META block数据,而BucketCache用于缓存真的数据
(2)、BucketCache作为LruBlockCache的二级缓存使用
hbase运行原理
标签:lob server memory family hdfs gic tor perl 信息
原文地址:https://www.cnblogs.com/tesla-turing/p/11959823.html