标签:出现 lines 程序 内核线程 工作 out sdn 意思 roc
前面介绍了I/O多路复用模型,那有了I/O复用,有了epoll已经可以使服务器并发几十万连接的同时,还能维持比较高的TPS,难道还不够吗?比如现在在使用epoll的时候一般都是起个任务,不断的去巡检事件,然后通知处理,而比较理想的方式是最好能以一种回调的机制,提供一个编程框架,让程序更有结构些,另一方面,如果希望每个事件通知之后,做的事情能有机会被代理到某个线程里面去单独运行,而线程完成的状态又能通知回主任务,那么"异步"的进制就必须被引入。所以这个章节主要介绍下"编程框架"。
Reactor模式是处理并发I/O比较常见的一种模式,用于同步I/O,中心思想是将所有要处理的I/O事件注册到一个中心I/O多路复用器上,同时主线程/进程阻塞在多路复用器上;一旦有I/O事件到来或是准备就绪(文件描述符或socket可读、写),多路复用器返回并将事先注册的相应I/O事件分发到对应的处理器中。
Reactor是一种事件驱动机制,和普通函数调用的不同之处在于:应用程序不是主动的调用某个API完成处理,而是恰恰相反,Reactor逆置了事件处理流程,应用程序需要提供相应的接口并注册到Reactor上,如果相应的事件发生,Reactor将主动调用应用程序注册的接口,这些接口又称为“回调函数”。用“好莱坞原则”来形容Reactor再合适不过了:不要打电话给我们,我们会打电话通知你。
Reactor模式与Observer模式在某些方面极为相似:当一个主体发生改变时,所有依属体都得到通知。不过,观察者模式与单个事件源关联,而反应器模式则与多个事件源关联 。
在Reactor模式中,有5个关键的参与者:
这部分内容主要来自:https://blog.csdn.net/russell_tao/article/details/17452997
https://blog.csdn.net/u013074465/article/details/46276967
传统编程方法
就好像是到了银行营业厅里,每个窗口前排了长队,业务员们在窗口后一个个的解决客户们的请求。一个业务员可以尽情思考着客户A依次提出的问题,例如:
“我要买2万XX理财产品。“
“看清楚了,5万起售。”
“等等,查下我活期余额。”
“余额5万。”
“那就买 5万吧。”
业务员开始录入信息。
”对了,XX理财产品年利率8%?”
“是预期8%,最低无利息保本。“
”早不说,拜拜,我去买余额宝。“
业务员无表情的删着已经录入的信息进行事务回滚。
“下一个!”
IO复用方法
用了IO复用则是大师业务员开始挑战极限,在超大营业厅里给客户们人手一个牌子,黑压压的客户们都在大厅中,有问题时举牌申请提问,大师目光敏锐点名指定某人提问,该客户迅速得到大师的答复后,要经过一段时间思考,查查自己的银袋子,咨询下LD,才能再次进行下一个提问,直到得到完整的满意答复退出大厅。例如:大师刚指导A填写转帐单的某一项,B又来申请兑换泰铢,给了B兑换单后,C又来办理定转活,然后D与F在争抢有限的圆珠笔时出现了不和谐现象,被大师叫停业务,暂时等待。
这就是基于事件驱动的IO复用编程比起传统1线程1请求的方式来,有难度的设计点了,客户们都是上帝,既不能出错,还不能厚此薄彼。
当没有Reactor时,我们可能的设计方法是这样的:大师把每个客户的提问都记录下来,当客户A提问时,首先查阅A之前问过什么做过什么,这叫联系上下文,然后再根据上下文和当前提问查阅有关的银行规章制度,有针对性的回答A,并把回答也记录下来。当圆满回答了A的所有问题后,删除A的所有记录。
某一瞬间,服务器共有10万个并发连接,此时,一次IO复用接口的调用返回了100个活跃的连接等待处理。先根据这100个连接找出其对应的对象,这并不难,epoll的返回连接数据结构里就有这样的指针可以用。接着,循环的处理每一个连接,找出这个对象此刻的上下文状态,再使用read、write这样的网络IO获取此次的操作内容,结合上下文状态查询此时应当选择哪个业务方法处理,调用相应方法完成操作后,若请求结束,则删除对象及其上下文。
这样,我们就陷入了面向过程编程方法之中了,在面向应用、快速响应为王的移动互联网时代,这样做早晚得把自己玩死。我们的主程序需要关注各种不同类型的请求,在不同状态下,对于不同的请求命令选择不同的业务处理方法。这会导致随着请求类型的增加,请求状态的增加,请求命令的增加,主程序复杂度快速膨胀,导致维护越来越困难,苦逼的程序员再也不敢轻易接新需求、重构。
Reactor是解决上述软件工程问题的一种途径,它也许并不优雅,开发效率上也不是最高的,但其执行效率与面向过程的使用IO复用却几乎是等价的,所以,无论是nginx、memcached、redis等等这些高性能组件的代名词,都义无反顾的一头扎进了反应堆的怀抱中。
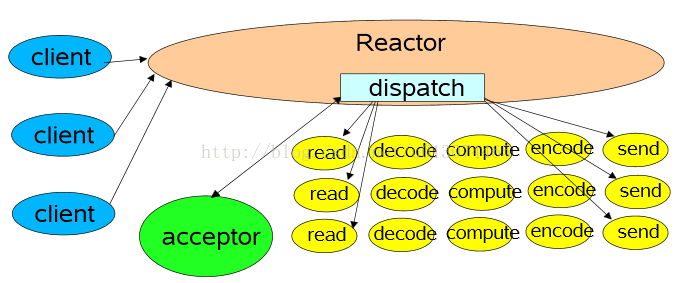
Reactor模式可以在软件工程层面,将事件驱动框架分离出具体业务,将不同类型请求之间用OO的思想分离。通常,Reactor不仅使用IO复用处理网络事件驱动,还会实现定时器来处理时间事件的驱动(请求的超时处理或者定时任务的处理),就像下面的示意图:
这幅图有5点意思:
参考资料:http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
在web服务中,很多都涉及基本的操作:read request、decode request、process service、encod reply、send reply等。
这是最简单的Reactor单线程模型。Reactor线程是个多面手,负责多路分离套接字,Accept新连接,并分派请求到处理器链中。该模型适用于处理器链中业务处理组件能快速完成的场景。不过这种单线程模型不能充分利用多核资源,所以实际使用的不多。
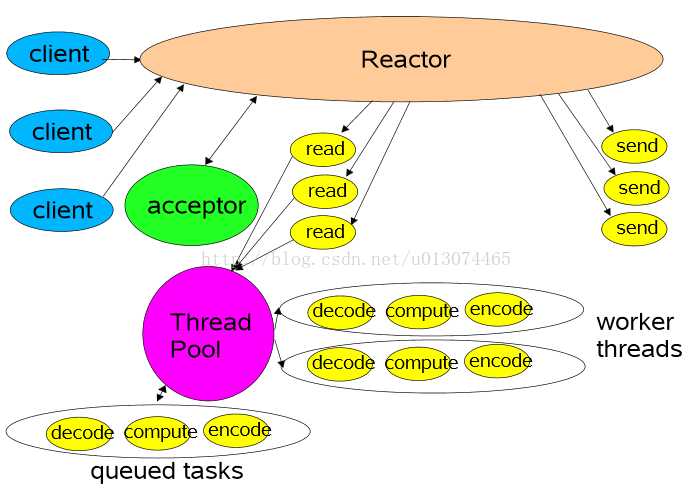
该模型在事件处理器(Handler)链部分采用了多线程(线程池),也是后端程序常用的模型。
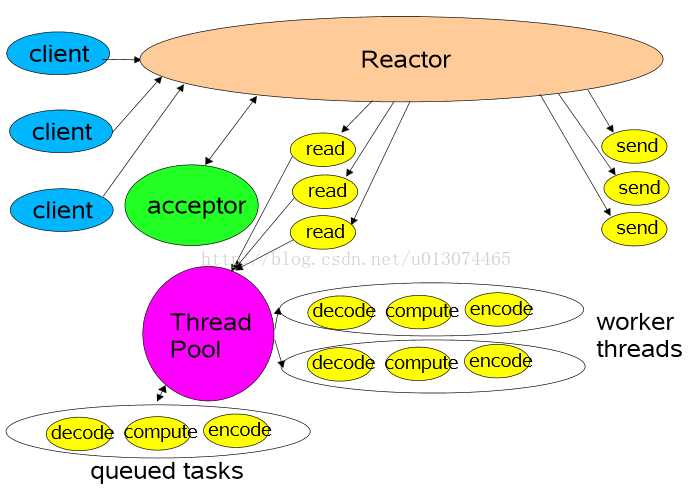
比起第二种模型,它是将Reactor分成两部分,mainReactor负责监听并accept新连接,然后将建立的socket通过多路复用器(Acceptor)分派给subReactor。subReactor负责多路分离已连接的socket,读写网络数据;业务处理功能,其交给worker线程池完成。通常,subReactor个数上可与CPU个数等同。
Proactor是和异步I/O相关的。
在Reactor模式中,事件分离者等待某个事件或者可应用多个操作的状态发生(比如文件描述符可读写,或者是socket可读写),事件分离器就把这个事件传给事先注册的处理器(事件处理函数或者回调函数),由后者来做实际的读写操作。
在Proactor模式中,事件处理者(或者代由事件分离者发起)直接发起一个异步读写操作(相当于请求),而实际的工作是由操作系统来完成的。发起时,需要提供的参数包括用于存放读到数据的缓存区,读的数据大小,或者用于存放外发数据的缓存区,以及这个请求完后的回调函数等信息。事件分离者得知了这个请求,它默默等待这个请求的完成,然后转发完成事件给相应的事件处理者或者回调。
可以看出两者的区别:Reactor是在事件发生时就通知事先注册的事件(读写由处理函数完成);Proactor是在事件发生时进行异步I/O(读写由OS完成),待IO完成事件分离器才调度处理器来处理。
举个例子,将有助于理解Reactor与Proactor二者的差异,以读操作为例(类操作类似)。
在Reactor(同步)中实现读:
Proactor(异步)中的读:
对比几个常见的I/O编程框架:libevent,libev,libuv,aio,boost.Asio。
libevent是一个C语言写的网络库,官方主要支持的是类linux操作系统,最新的版本添加了对windows的IOCP的支持。在跨平台方面主要通过select模型来进行支持。
设计模式 :libevent为Reactor模式;
层次架构:livevent在不同的操作系统下,做了多路复用模型的抽象,可以选择使用不同的模型,通过事件函数提供服务;
可移植性 :libevent主要支持linux平台,freebsd平台,其他平台下通过select模型进行支持,效率不是太高;
事件分派处理 :libevent基于注册的事件回调函数来实现事件分发;
涉及范围 :libevent只提供了简单的网络API的封装,线程池,内存池,递归锁等均需要自己实现;
线程调度 :libevent的线程调度需要自己来注册不同的事件句柄;
发布方式 :libevent为开源免费的,一般编译为静态库进行使用;
开发难度 :基于libevent开发应用,相对容易,具体可以参考memcached这个开源的应用,里面使用了 libevent这个库。
libevent/libev是两个名字相当相近的I/O Library。既然是库,第一反应就是对api的包装。epoll在linux上已经存在了很久,但是linux是SysV的后代,BSD及其衍生的MAC就没有,只有kqueue。
libev v.s libevent。既然已经有了libevent,为什么还要发明一个轮子叫做libev?
http://www.cnblogs.com/Lifehacker/p/whats_the_difference_between_libevent_and_libev_chinese.html
http://stackoverflow.com/questions/9433864/whats-the-difference-between-libev-and-libevent
上面是libev的作者对于这个问题的回答,下面是网摘的中文翻译:
就设计哲学来说,libev的诞生,是为了修复libevent设计上的一些错误决策。例如,全局变量的使用,让libevent很难在多线程环境中使用。watcher结构体很大,因为它们包含了I/O,定时器和信号处理器。额外的组件如HTTP和DNS服务器,因为拙劣的实现品质和安全问题而备受折磨。定时器不精确,而且无法很好地处理时间跳变。
总而言之,libev试图做好一件事而已(目标是成为POSIX的事件库),这是最高效的方法。libevent则尝试给你全套解决方案(事件库,非阻塞IO库,http库,DNS客户端)libev 完全是单线程的,没有DNS解析。
libev解决了epoll, kqueuq等API不同的问题。保证使用livev的程序可以在大多数 *nix 平台上运行(对windows不太友好)。但是 libev 的缺点也是显而易见,由于基本只是封装了 Event Library,用起来有诸多不便。比如 accept(3) 连接以后需要手动 setnonblocking 。从 socket 读写时需要检测 EAGAIN 、EWOULDBLOCK 和 EINTER 。这也是大多数人认为异步程序难写的根本原因。
libuv是Joyent给Node做的I/O Library。libuv 需要多线程库支持,其在内部维护了一个线程池来 处理诸如getaddrinfo(3) 这样的无法异步的调用。同时,对windows用户友好,Windows下用IOCP实现,官网http://docs.libuv.org/en/v1.x/
Boost.Asio类库,其就是以Proactor这种设计模式来实现。
参见:Proactor(The Boost.Asio library is based on the Proactor pattern. This design note outlines the advantages and disadvantages of this approach.),
其设计文档链接:http://asio.sourceforge.net/boost_asio_0_3_7/libs/asio/doc/design/index.html
http://stackoverflow.com/questions/11423426/how-does-libuv-compare-to-boost-asio
linux有两种aio(异步机制),一是glibc提供的(bug很多,几乎不可用),一是内核提供的(BSD/mac也提供)。当然,机制不等于编程框架。
最后,本文介绍的同步Reactor模型比较多,后面的章节会以boost.Asio库为基础讲解为什么需要异步编程
标签:出现 lines 程序 内核线程 工作 out sdn 意思 roc
原文地址:https://www.cnblogs.com/goya/p/11961521.html