标签:完全 img 树形结构 数据 事件 递归 tle 不同 value
1.什么是决策树
决策树是一种解决分类问题的算法。
决策树采用树形结构,使用层层推理来实现最终的分类。
决策树由下边几种元素组成:
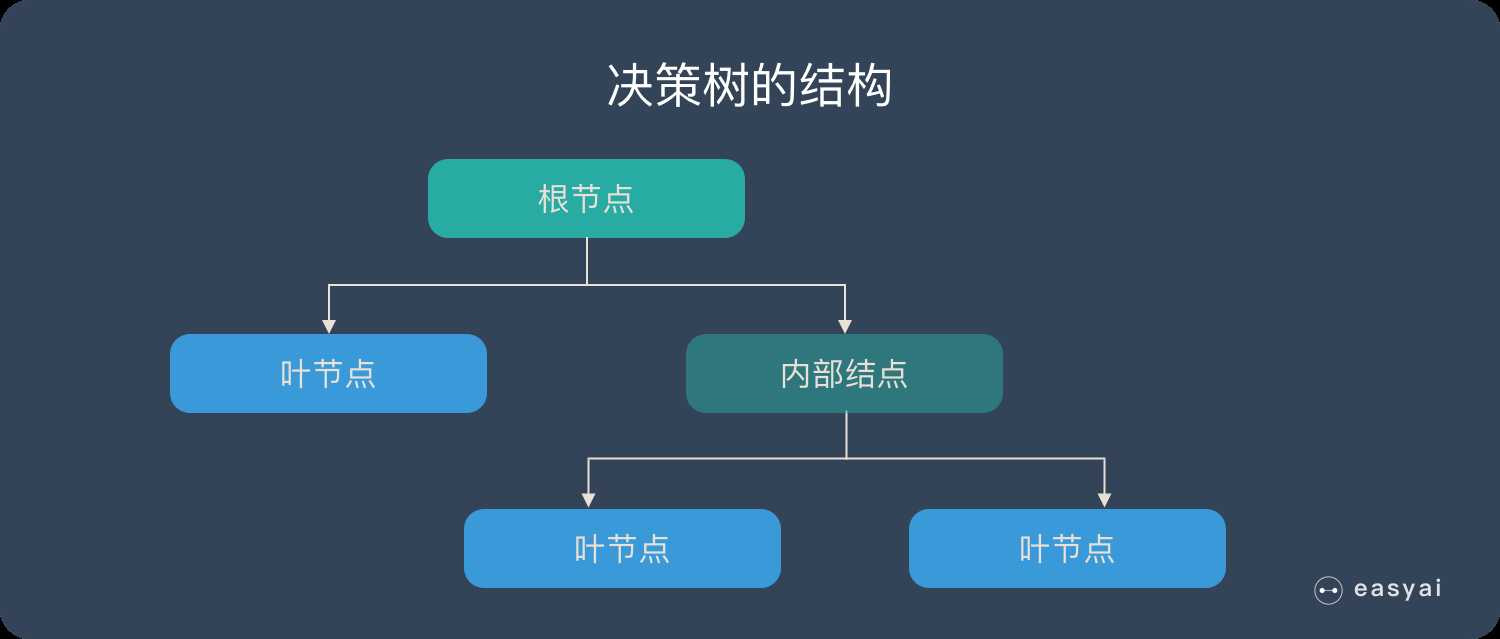
预测时,在树的内部节点处用某一属性值进行判断,根据判断结果决定进入哪个分支节点,直到到达叶节点处,得到分类结果。
这是一种有监督的学习算法,决策树的这些规则通过训练得到,而不是人工制定的.
决策树是最简单的机器学习算法,易于实现,可解释性强,完全符合人类的直观思维,有着广泛的应用.
2.决策树的原理
构造决策树:
构造决策树的关键步骤是分裂属性,所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。
3.决策树实战讲解鸢尾花分类问题
1 import numpy as np 2 3 from sklearn.tree import DecisionTreeClassifier 4 5 from sklearn import datasets 6 7 import matplotlib.pyplot as plt 8 %matplotlib inline 9 10 from sklearn import tree 11 from sklearn.model_selection import train_test_split
# 加载鸢尾花数据 iris=datasets.load_iris() X=iris[‘data‘] y=iris[‘target‘] # 查看鸢尾花类别的名字 feature_names=iris.feature_names # 将数据分为训练数据和测试数据,比例是4:1 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=1024)
# 训练数据,预测鸢尾花的种类 # entropy 熵 采用的分类标准是熵,也可以使用gini系数 max_depth 参数表示的是树的深度,默认是最大深度,当然,树的深度越大,精度越高, clf=DecisionTreeClassifier(criterion=‘entropy‘) clf.fit(X_train,y_train) y_=clf.predict(X_test) from sklearn.metrics import accuracy_score # 计算准确率 accuracy_score(y_test,y_)
# 查看树的结构 plt.figure(figsize=(18,12)) # filled填充颜色 _=tree.plot_tree(clf,filled=True,feature_names=feature_names) plt.savefig(‘./tree.jpg‘)
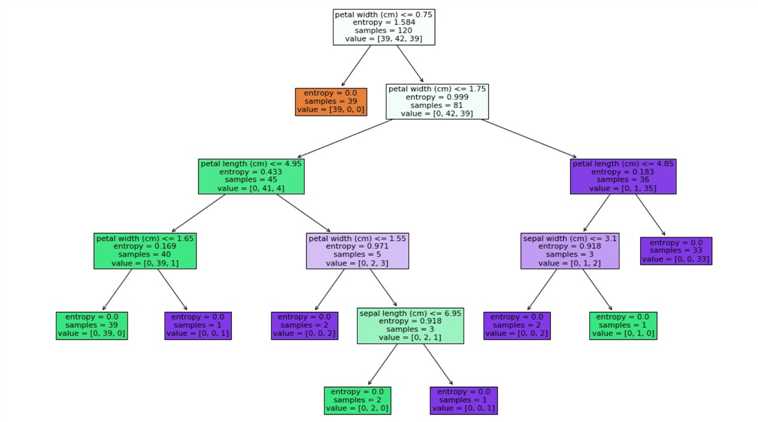
接下来分析一下这个棵树:
(1)其实是按照熵来划分的,那么什么是熵(entropy)呢,计算公式是什么?
熵其实是信息论与概率统计学中的概念,但是在机器学习中用到的也很多.信息熵公式:代表随机变量不确定度的度量
不确定性的变化跟什么有关呢?
一,跟事情的可能结果的数量有关;二,跟概率有关
所以熵的公式: 或者
信息论之父克劳德·香农,总结出了信息熵的三条性质:
上例中根节点的熵的计算:samples为样本的数量,values为每种花的数量,entropy为熵的值
39/120*np.log2(120/39)*2+42/120*np.log2(120/42)=1.584
之后每个节点的熵都是该计算公式,通过第一个节点的分类,直接将第一类花分出来
(2)对于第一个分类条件,他是根据属性进行划分
鸢尾花有四种属性,第一次分可以根据训练样本的方差,方差越大,说明越离散,越容易分开,之后再使用各种方法判断四种属性就可以了,简言之,这个分类挺麻烦的,不过不是没有依据的,就是根据花的四种属性(花萼的长宽,花瓣的长宽)分类.最终得到三种纯的鸢尾花.
(3)上述的熵也可以改为gini系数,其实是一样的,公式如下
标签:完全 img 树形结构 数据 事件 递归 tle 不同 value
原文地址:https://www.cnblogs.com/xiuercui/p/11962539.html