标签:start group 未使用 创建 mamicode python 表设计 模版 一半
就在本周,应该是在本周二,小编翻车啦~~~

之前有关注我的同学应该知道,小编在国庆节写了一只爬虫,来抓取自己的各个平台博客的访问量等一些数据,并且后面简单做了个报表,主要是靠 SQL 来统计数据。
这只爬虫小编部署到 Linux 服务器上以后,设置了整点定时抓取数据也没管过,倒是刚上线那段时间经常去报表平台看看统计报表。
想了解事情起因的同学可以看一下这两篇文章《Python 简易爬虫实战》 和 《小白 Python 爬虫部署 Linux》 。
然后,就在小编偶然上去看报表的时候,发现已经不同寻常的事情。
我靠,咋点了半天没反应。。。
感觉时间过了半个世纪,报表才渲染出来。

肯定哪里不对,小编赶紧用 Navicat 执行了一下报表的 SQL ,结果:
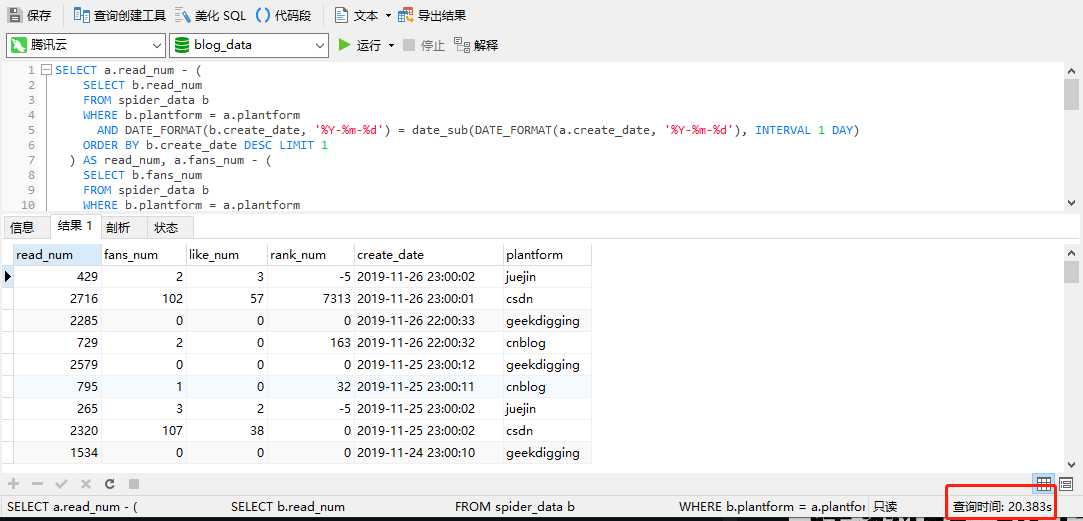
对的,你没看错,这句话执行了 20s+ ,小编当时的心里感觉有一万只羊驼奔腾而过。

有没有搞错,数据拢共 2k 多条,执行一下要 20s+ ,是在开玩笑么,小编当时都怀疑自己是不是用了一台假数据库。
emmmmmmmmmm,顺便介绍一下数据库配置,使用的是某云服务的 MySQL 库,硬件配置为 1H1G(1核1G)。
冷静下,深呼吸两个,小编不信邪,正好手上有一台 2H8G 的服务器,赶紧搭一个 Mysql 试一下,某云提供的一定是假数据库。
结果,emmmmmmmmmmm,还是直接给各位同学看吧。
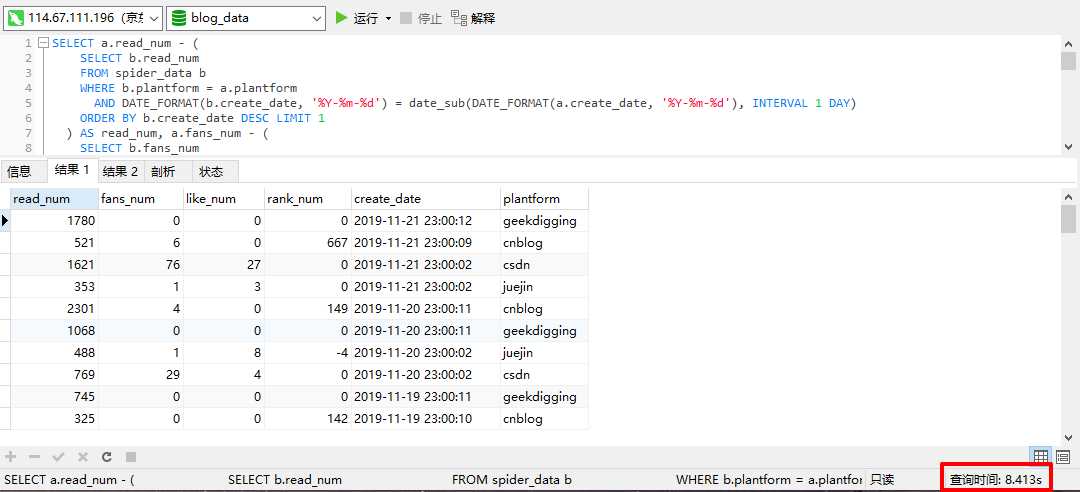
好吧,现在要正式这个错误。。。
不过服务器的核心数加了一倍(一个)时间数少了一半多,那理论上讲,如果小编用的是一台物理机,如果这台物理机有大几十核的 CPU ,就不会有问题啊~~~
果然,还是贫穷惹的祸。。。。
告辞。
当然,本文不会就这么结束:)
现在,已经发现错误了,接下来就是尤为关键的一步了,解决这个问题。
程序猿解决问题是有一个万能的模版,先用这个模版套一下:
emmmmmmmmmm,提问题的人是小编自己,所以,小编不能解决掉自己,那么,这就不是个问题,所以也就不需要解决了。。。。。。。。
不行,这个还是太影响使用体验,还是来正经的分析下这个问题。
首先看下数据库的表设计:
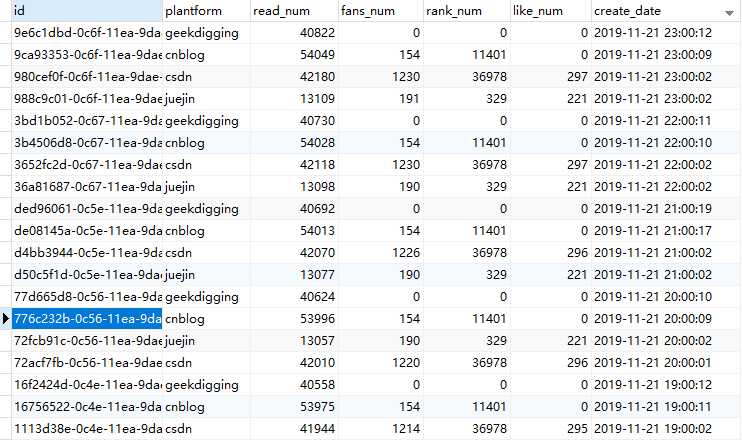
咳咳。
就这么一张表,当时比较懒,爬虫每次抓取的都是当时的截面数据,统计报表的 sql 需要动态的去算出每天的增量数据。具体算法是使用当天的最大值减去前一天的最大值,再进行分类统计。
看下小编的 sql 吧:
SELECT a.read_num - (
SELECT b.read_num
FROM spider_data b
WHERE b.plantform = a.plantform
AND DATE_FORMAT(b.create_date, '%Y-%m-%d') = date_sub(DATE_FORMAT(a.create_date, '%Y-%m-%d'), INTERVAL 1 DAY)
ORDER BY b.create_date DESC LIMIT 1
) AS read_num, a.fans_num - (
SELECT b.fans_num
FROM spider_data b
WHERE b.plantform = a.plantform
AND DATE_FORMAT(b.create_date, '%Y-%m-%d') = date_sub(DATE_FORMAT(a.create_date, '%Y-%m-%d'), INTERVAL 1 DAY)
ORDER BY b.create_date DESC LIMIT 1
) AS fans_num
, a.like_num - (
SELECT b.like_num
FROM spider_data b
WHERE b.plantform = a.plantform
AND DATE_FORMAT(b.create_date, '%Y-%m-%d') = date_sub(DATE_FORMAT(a.create_date, '%Y-%m-%d'), INTERVAL 1 DAY)
ORDER BY b.create_date DESC LIMIT 1
) AS like_num, (
SELECT b.rank_num
FROM spider_data b
WHERE b.plantform = a.plantform
AND DATE_FORMAT(b.create_date, '%Y-%m-%d') = date_sub(DATE_FORMAT(a.create_date, '%Y-%m-%d'), INTERVAL 1 DAY)
ORDER BY b.create_date DESC LIMIT 1
) - a.rank_num AS rank_num
, a.create_date,a.plantform
FROM (SELECT * FROM spider_data ORDER BY create_date DESC LIMIT 1000000000000000) a
GROUP BY DATE_FORMAT(a.create_date, '%Y-%m-%d'), a.plantform
ORDER BY a.create_date DESC;稍微长了一丢丢,不过从这个 sql 上,已经能看到明显的问题了,在做查询的时候,使用了大量的子查询。
至于为什么要这么写,当然是因为懒咯~~~
前面的爬虫已经将截面数据爬取到了,后面做统计当然是一句话搞定了。
结果就是这偷懒的一句话,酿造了今天的惨剧。

小编脑子里瞬间出现一种解决方案,在爬虫每次爬取数据的时候,就做一次结果数据处理,新建另外一张结果表,每次爬取完数据后,同时计算出结果数据,直接存入结果数据表中。
统计数据的报表直接取结果表中的数据,肯定快的飞起~~~
啥子,还要我改之前的爬虫代码,不知道程序猿都是懒癌晚期么,开神马玩笑!!!
瞬间大脑就将第一个方案推翻了,第二个折中的方案也悄然浮上心头。
每天凌晨做一个定时任务,定时的统计前一天的数据,这样的修改代价是最小的,但是就是每天只能看到前一天的统计数据。
这个方法好,只需要加一个定时任务就能搞定,但是就是有点改变目前现有的需求,好吧,还是可以接受的,为了解决这个问题,只能顺便解决一点自己了。
定时任务有好多种做法,一种是直接做在 Mysql 数据库上,还可以用 Python 写成脚本,在 Linux 上设置定时任务去调用对应的 Python 脚本。
小编这么懒的人,怎么可能去做 Linux 的定时任务,当然是直接使用 Mysql 的定时任务。
顺手查了一下百度,自 MySQL5.1.6 起,MySQL 增加了一个非常有特色的功能-事件调度器(Event Scheduler)。
意思就是小编目前使用的 Mysql 版本是 5.7 ,肯定是有定时任务功能。
首先在创建定时任务前需要先创建一个存储过程,然后给这个存储过程设置定时执行。
CREATE DEFINER=`root`@`%` PROCEDURE `TimerBlogData`()
BEGIN
INSERT INTO result_data (read_num, fans_num, like_num, rank_num, create_date, plantform) (
SELECT a.read_num - (
SELECT b.read_num
FROM spider_data b
WHERE b.plantform = a.plantform
AND DATE_FORMAT(b.create_date, '%Y-%m-%d') = date_sub(DATE_FORMAT(a.create_date, '%Y-%m-%d'), INTERVAL 1 DAY)
ORDER BY b.create_date DESC LIMIT 1
) AS read_num, a.fans_num - (
SELECT b.fans_num
FROM spider_data b
WHERE b.plantform = a.plantform
AND DATE_FORMAT(b.create_date, '%Y-%m-%d') = date_sub(DATE_FORMAT(a.create_date, '%Y-%m-%d'), INTERVAL 1 DAY)
ORDER BY b.create_date DESC LIMIT 1
) AS fans_num
, a.like_num - (
SELECT b.like_num
FROM spider_data b
WHERE b.plantform = a.plantform
AND DATE_FORMAT(b.create_date, '%Y-%m-%d') = date_sub(DATE_FORMAT(a.create_date, '%Y-%m-%d'), INTERVAL 1 DAY)
ORDER BY b.create_date DESC LIMIT 1
) AS like_num, (
SELECT b.rank_num
FROM spider_data b
WHERE b.plantform = a.plantform
AND DATE_FORMAT(b.create_date, '%Y-%m-%d') = date_sub(DATE_FORMAT(a.create_date, '%Y-%m-%d'), INTERVAL 1 DAY)
ORDER BY b.create_date DESC LIMIT 1
) - a.rank_num AS rank_num
, a.create_date,a.plantform
FROM (SELECT * FROM spider_data ORDER BY create_date DESC LIMIT 1000000000000000) a
WHERE DATE_FORMAT(a.create_date, '%Y-%m-%d') = DATE_FORMAT(date_sub(now(), interval 1 day), '%Y-%m-%d')
GROUP BY DATE_FORMAT(a.create_date, '%Y-%m-%d'), a.plantform
ORDER BY a.create_date DESC
);
END写好了可以使用 CALL TimerBlogData() 执行一下,看下数据是否可以正常写入,测试成功后就可以创建 MySQL 的定时任务了。
在 Mysql 上创建定时任务要先看一下当前是否已开启事件调度器,可以使用以下 SQL 进行查看:
SHOW VARIABLES LIKE 'event_scheduler';
SELECT @@event_scheduler;如果看到结果显示 ON ,则代表已经开启,如果看到的是 OFF ,则未开启,未开启的数据库需要先开启这个功能。
此功能可以通过修改数据库配置 my.cnf 文件来完成,在配置中添加 event_scheduler = 1 ,因为小编使用的是云服务,直接在数据库后台配置中完成修改即可。
接下来创建定时任务,如果使用 Navicat 图形化界面创建会比较简单,小编并未使用过,下面还是直接贴代码:
CREATE EVENT timer_blog_data
ON SCHEDULE EVERY 1 DAY STARTS DATE_ADD(DATE_ADD(CURDATE(), INTERVAL 1 DAY), INTERVAL 1 HOUR)
DO CALL TimerBlogData()设置定时任务为每天凌晨 1 点执行,任务名为:timer_blog_data 。
运行完成后,打开 Navicat 查看事件,右键选择设计事件:
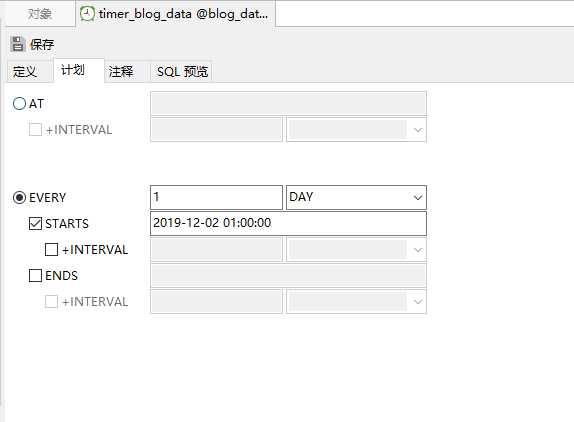
可以看到定时任务设置成功。
修改下统计报表的程序,讲取数规则从原来的 SQL 改为从结果表直接查询,部署服务器,重启。打开浏览器重新尝试。果然又成了秒开。
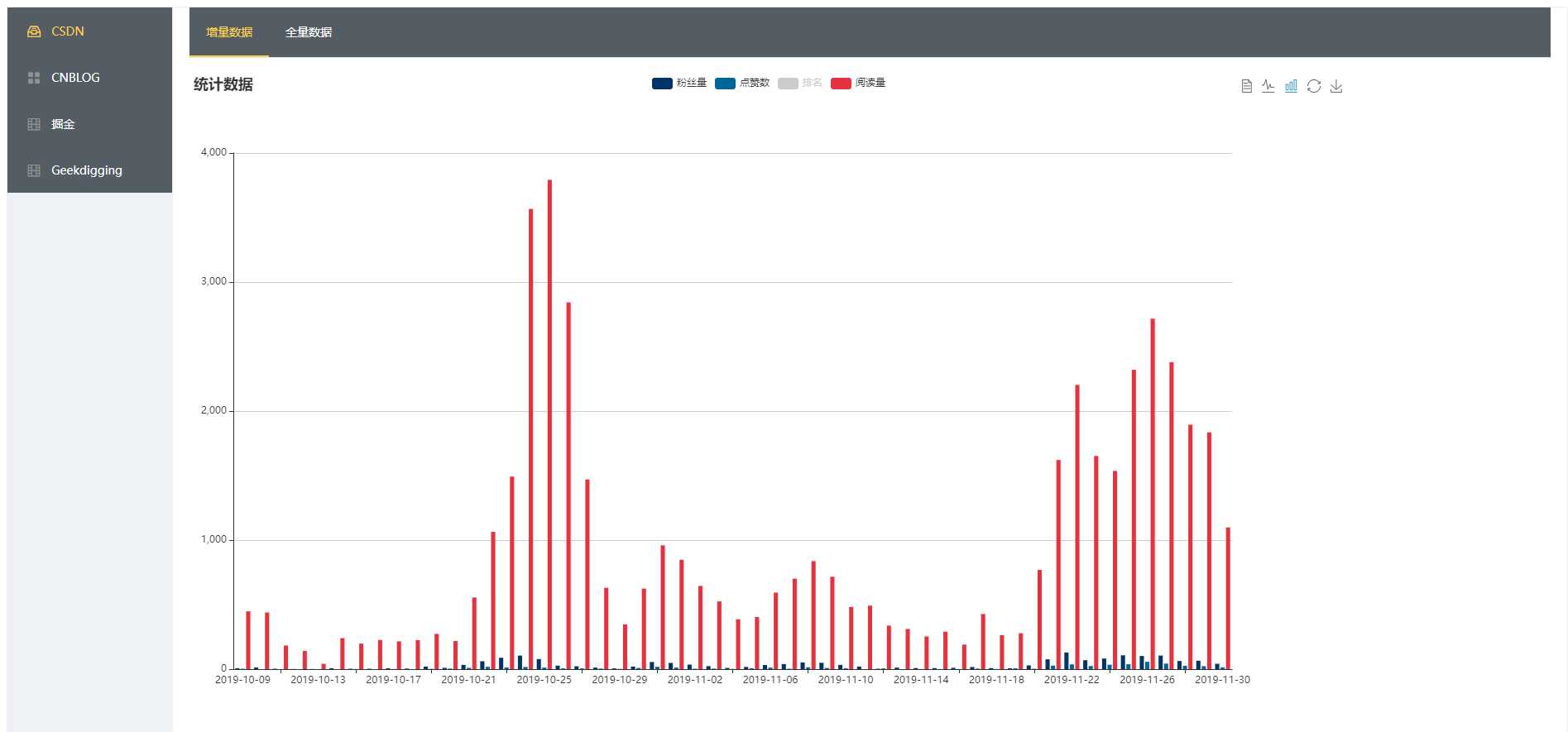
问题是解决了,还是要分析一下本次问题的。
从小编的 sql 中,可以看到每次查询,每一条数据的取出,都需要在子查询中重新检索整张表,并选择出对应的数据进行计算,而每次查询,都有 2k 多条数据会参加整体查询,每一条数据的查询,都包含了 4 个子查询,总体的运算量,好吧,小编承认确实有点大了。。。
优化的时候,主体的思路是降低当前查询的运算量,那解决方案就很好想了,要么是在每次写入数据的时候进行运算,相当于是整体的运算量分布到每次写入了,要么是添加一个定时任务,让大量的运算每天都只运行一次,后续的查询直接查询运算结果。
标签:start group 未使用 创建 mamicode python 表设计 模版 一半
原文地址:https://www.cnblogs.com/babycomeon/p/11966092.html