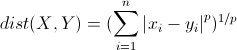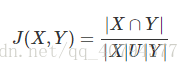标签:推理 测量 参考 sha 向量空间 pow tps 组成 原理
更新中
最近更新时间:
2019-12-02 16:55:02
写在前面:
本人是喜欢这个方向的学生一枚,写文的目的意在记录自己所学,梳理自己的思路,同时share给在这个方向上一起努力的同学。写得不够专业的地方望批评指正,欢迎感兴趣的同学一起交流进步。
在很多NLP任务中,都涉及到语义相似度的计算,例如:
在搜索场景下(对话系统、问答系统、推理等),query和Doc的语义相似度;
feeds场景下Doc和Doc的语义相似度;
在各种分类任务,翻译场景下,都会涉及到语义相似度语义相似度的计算。
所以在学习的过程中,希望能够更系统的梳理一下这方面的方法。
向量空间模型简称 VSM,是 VectorSpace Model 的缩写。在此模型中,文本被看作是由一系列相互独立的词语组成的,若文档 D 中包含词语 t1,t2,…,tN,则文档表示为D(t1,t2,…,tN)。由于文档中词语对文档的重要程度不同,并且词语的重要程度对文本相似度的计算有很大的影响,因而可对文档中的每个词语赋以一个权值 w,以表示该词的权重,其表示如下:D(t1,w1;t2,w2;…,tN,wN),可简记为 D(w1,w2,…,wN),此时的 wk 即为词语 tk的权重,1≤k≤N。关于权重的设置,我们可以考虑的方面:词语在文本中的出现频率(tf),词语的文档频率(df,即含有该词的文档数量,log N/n。很多相似性计算方法都是基于向量空间模型的。
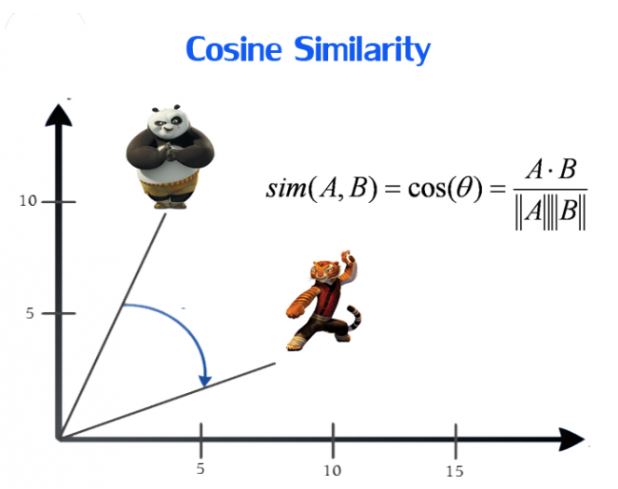
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
两个向量间的余弦值可以通过使用欧几里得点积公式求出:
![]()
余弦相似性θ由点积和向量长度给出,如下所示(例如,向量A和向量B):

这里的![]() 分别代表向量A和B的各分量。
分别代表向量A和B的各分量。
问题:表示方向上的差异,但对距离不敏感。
关心距离上的差异时,会对计算出的每个(相似度)值都减去一个它们的均值,称为调整余弦相似度。
代码:

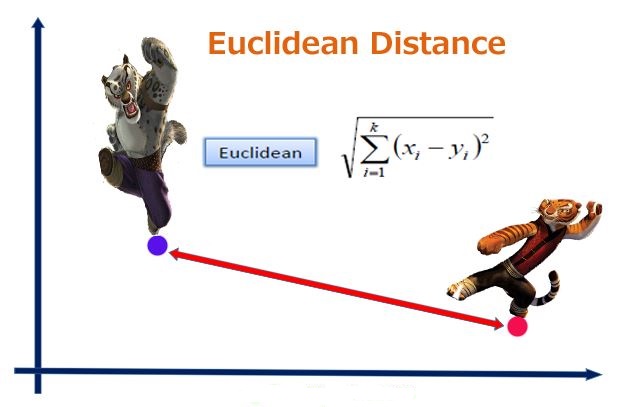
考虑的是点的空间距离,各对应元素做差取平方求和后开方。能体现数值的绝对差异。
代码:
代码:
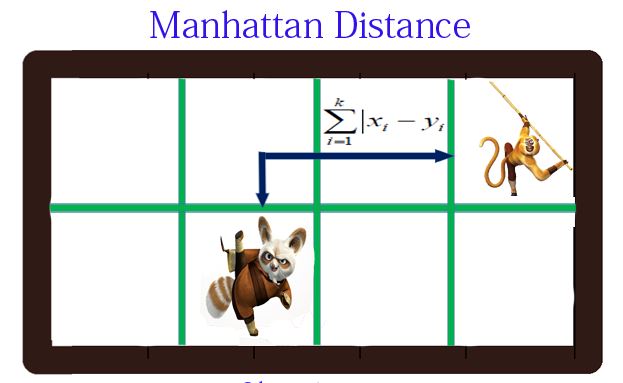
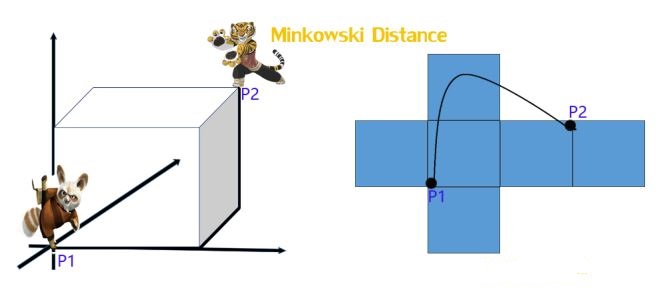
明氏距离是欧氏距离的推广,是对多个距离度量公式的概括性的表述。
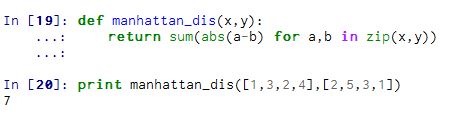
代码:
标签:推理 测量 参考 sha 向量空间 pow tps 组成 原理
原文地址:https://www.cnblogs.com/shona/p/11971310.html