除了redis,还可以使用另外一个神器----Celery。Celery是一个异步任务的调度工具。
Celery是Distributed Task Queue,分布式任务队列,分布式决定了可以有多个worker的存在,列表表示其是异步操作,即存在一个产生任务提出需求的工头,和一群等着被分配工作的码农。
在python中定义Celery的时候,我们要引入Broker,中文翻译过来就是"中间人"的意思,在这里Broker起到一个中间人的角色,在工头提出任务的时候,把所有的任务放到Broker里面,在Broker的另一头,一群码农等着取出一个个任务准备着手做。
这种模式注定了整个系统会是个开环系统,工头对于码农们把任务做的怎样是不知情的,所以我们要引入Backend来保存每次任务的结果。这个Backend有点像我们的Broker,也是存储信息用的,只不过这里存的是那些任务的返回结果。我们可以选择只让错误执行的任务返回结果到Backend,这样我们取回结果,便可以知道有多少任务执行失败了。
Celery 介绍
在Celery中几个基本的概念,需要先了解下,不然不知道为什么要安装下面的东西。概念:Broker,Backend。
Broker:
broker是一个消息传输的中间件,可以理解为一个邮箱。每当应用程序调用celery的异步任务的时候,会向broker传递消息,而后celery的worker将会取到消息,进行程序执行,好吧,这个邮箱可以看成是一个消息队列,其中Broker的中文意思是经纪人,其实就是一开始说的消息队列,用来发送和接受信息。这个broker有几个方案可供选择:RabbitMQ(消息队列),Redis(缓存数据库),数据库(不推荐),等等
什么是backend?
通常程序发送的消息,发完就完了,可能都不知道对方什么时候接受了,为此,celery实现了一个backend,用于存储这些消息以及celery执行的一些消息和结果,Backend是在Celery的配置中的一个配置项CELERY_RESULT_BACKEND,作用是保存结果和状态,如果你需要跟踪任务的状态,那么需要设置这一项,可以是Database backend,也可以是Cache backend.
对于brokers,官方推荐是rabbitmq和redis,至于backend,就是数据库,为了简单可以都使用redis。
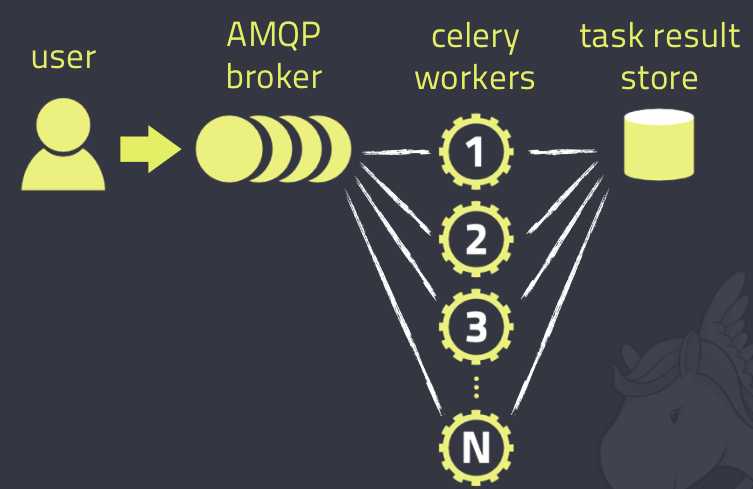
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成,包括,RabbitMQ,Redis,MongoDB..............
任务执行单元
Worker是celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP,redis,memcached,mongodb,SQLAlchemy,Django
安装Redis,它的安装比较简单:

然后进行配置,一般都在项目的config.py文件里配置:

URL的格式为:
redis://:password@hostname:port/db_number
URL Scheme后的所有字段都是可选的,并且默认为localhost的6479端口,使用数据库0。我的配置是:
redis://:password@ubuntu:6379/5
安装Celery,我是用标准的Python工具pip安装的,如下:

使用Celery
使用celery包含三个方面:1,定义任务函数 2,运行celery服务 3,客户应用程序的调用
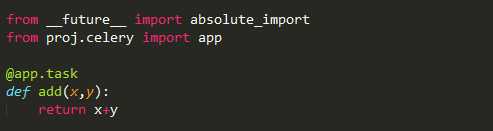
创建一个文件tasks.py输入下列代码:
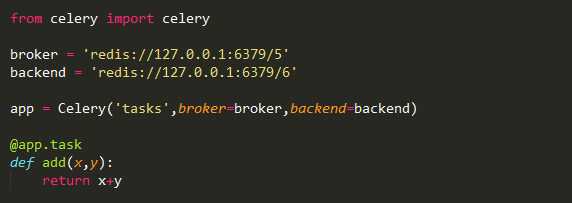
上述代码导入了celery,然后创建了celery实例app,实例化的过程中指定了任务名tasks(和文件名一致),传入了broker和backend。然后创建了一个任务函数add。下面启动
celery服务,在当前命令行终端运行:

目录结构(celery -A tasks worker --loglevel=info这条命令当前工作目录必须和tasks.py所在的目录相同,即进入tasks.py所在目录执行这条命令)
调用delay函数即可启动add这个任务,这个函数的效果是发送一条消息到broker中去,这个消息包括要执行的函数,函数的参数以及其他消息,具体的可以看Celery官方文档。这个时候worker会等待broker中的消息,一旦收到消息就会立刻执行消息。
注意:如果把返回值赋值给一个变量,那么原来的应用程序也会被阻塞,需要等待异步任务返回的结果,因此,实际使用中,不需要把结果赋值。
使用配置文件
Celery的配置比较多,可以在官方配置文档:http://docs.celeryproject.org/en/latest/userguide/configuration.html 查询每个配置项的含义。
上述的使用是简单的配置,下面介绍一个更健壮的方式来使用celery。首先创建一个python包,celery服务,姑且命名为proj。目录文件如下:

首先是celery.py
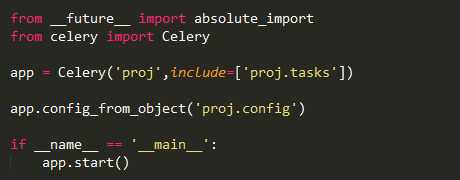
这一次创建app,并没有直接指定broker和backend。而是在配置文件中。
config.py

剩下的就是tasks.py
使用方法也很简单,在proj的同一级目录执行celery:
celery -A proj worker -l info
现在使用任务也很简单,直接在客户端代码调用proj.tasks里的函数即可。
Scheduler(定时任务,周期性任务)
一种常见的需求是每隔一段时间执行一个任务
在celery中执行定时任务非常简单,只需要设置celery对象的CELERYBEAT_SCHEDULE属性即可。
配置如下
config.py
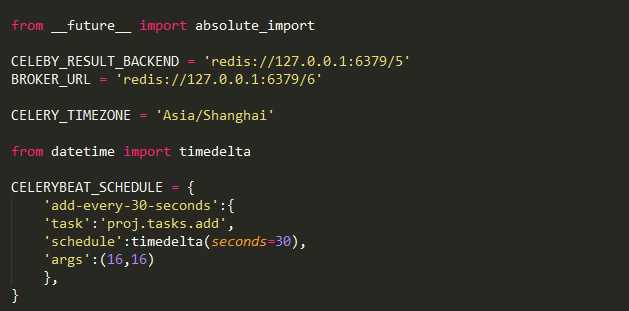
注意配置文件需要指定时区,这段代码表示每隔30秒执行add函数,一旦使用了scheduler,启动celery需要加上-B参数。
celery -A proj worker -B -l info
参考链接:https://blog.csdn.net/freeking101/article/details/74707619
celery
celery:中文翻译为芹菜.celery是python开发的一个简单,灵活可靠的处理大量任务的分发系统,它可以让任务的执行完全脱离主程序,甚至可以分配到其他主机上运行,我们通常用它来实现异步任务和定时任务,异步任务比如是发送邮件、或者文件上传, 图像处理等等一些比较耗时的操作 .
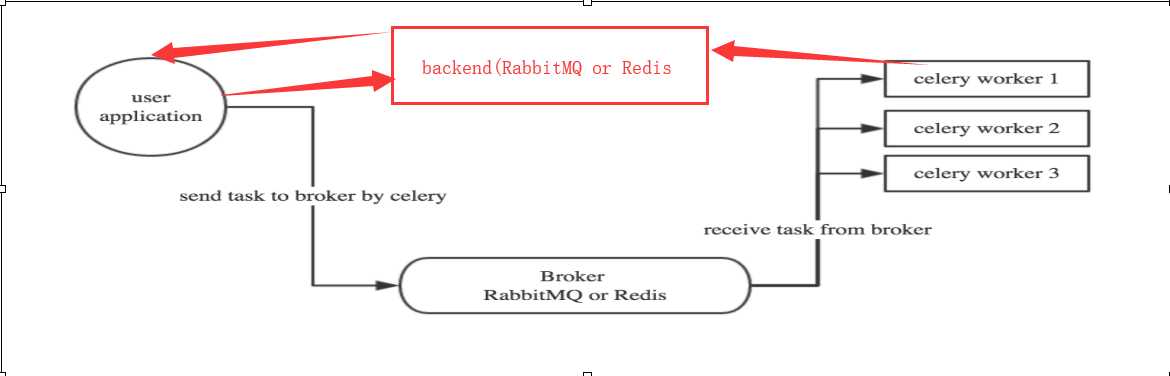
- user:用户程序,用于告知celery去执行一个任务。
- broker(中间件): 存放任务(依赖RabbitMQ或Redis,进行存储)
- worker:执行任务
celery需要rabbitMQ、Redis、Amazon SQS、Zookeeper(测试中) 充当broker来进行消息的接收,并且也支持多个broker和worker来实现高可用和分布式。
1.当celery收到用户请求后,它会立即返回给用户一个id,这时候用户就可以去干别的事情了.
2.celery把用户的请求放到broker中,
3.worker会从broker中拿用户请求进行处理.
4.worker把请求处理完了,会放到AsyncResult对象(backend)中,
5.用户根据id从backend中取值.
注意:用户需要亲自从backend中取值,如果不取的话,数据会一直在backend中待着.
应用场景:当处理一个任务很耗时的情况下.
调用任务的方式有两种
#第一种
task.delay(arg, kwarg=value) # task就是你的任务也就是你的函数名,括号里的参数就是你要给你的任务函数传的参数
#第二种task.apply_async()
#这个函数又包括好多的参数
# 1
task.apply_async(countdown=10)
executes in 10 seconds from now.
# 2
task.apply_async(eta=now + timedelta(seconds=10))
executes in 10 seconds from now, specified using eta
now = datetime.datetime.utcnow()
# 3
task.apply_async(countdown=60, expires=120)
executes in one minute from now, but expires after 2 minutes.
快速上手
1.建立worker. s1.py
import time
from celery import Celery
#执行celery的命令为:celery worker -A 文件名 -l info 注意不要加.py
#tasks任务名字,broker存放任务的,backend是一个存放worker处理完的结果的队列
app = Celery(‘tasks‘, broker=‘redis://127.0.0.1:6379‘, backend=‘redis://127.0.0.1:6379‘)
@app.task
def xxxxxx(x, y):
time.sleep(10)#用来模拟work的执行时间
return x + y
@app.task
def ooo(x,y):
time.sleep(8)
return x-y
2.调用者 s2.py
from s1 import xxxxxx
# 立即告知celery去执行xxxxxx任务,并传入两个参数
result = xxxxxx.delay(4, 4)
print(result.id)#返回celery返回的随机字符串即唯一标识
3.从存放结果的队列中拿数据 s3.py
from celery.result import AsyncResult
from s1 import app #导入实例化的Celery对象
from s2 import result #导入Celery返回的对象
async = AsyncResult(id=result.id, app=app)
if async.successful(): #如果这个任务执行完了
result = async.get() #从backend的队列中拿数据
print("结果为",result)
# result.forget() # 将结果从backend的队列中删除。
elif async.failed():
print(‘执行失败‘)
elif async.status == ‘PENDING‘:
print(‘任务正在等待被执行‘)
elif async.status == ‘RETRY‘:
print(‘任务异常后正在重试‘)
elif async.status == ‘STARTED‘:
print(‘任务正在执行,还没有执行完‘)
执行命令
#1把work运行起来用来接收数据,这个文件会夯住等待知道broker中任务,才执行
celery worker -A s1 -l info
#运行调用work中的函数的py文件
python3 s2.py
#3 运行文件从backend中拿数据的
python3 s3.py
定时调用
告诉celery10s后帮我执行任务.
修改s2文件为s4.py
from s1 import xxxxxx
import datetime
#把本地时间转换成utc时间
ctime_x = datetime.utcnow()+timedelta(seconds=10)
#告知celery,10s后帮我执行任务
result=xxxxxx.apply_async(args=[4,5] ,eta=ctime_x)#eta必须是utc时间
celery还有类似于crontab的功能,比如在每天8:42执行某项任务可以在celery.py中这么写
from celery import Celery
#tasks任务名字,broker存放任务的,backend存放结果的
cel_obj = Celery(‘tasks‘,
broker=‘redis://127.0.0.1:6379‘,
backend=‘redis://127.0.0.1:6379‘,
include=[‘celery_task.s1‘])#include里放要执行的任务
#第一种定时任务
cel_obj .conf.beat_schedule = {
‘add-every-12-seconds‘: {
‘task‘: ‘proj.s1.add1‘, #任务名称
‘schedule‘: crontab(minute=42, hour=8),#每天8:42执行该任务
‘args‘: (16, 16) #给该任务传递的参数
},
#第二种定时任务:
‘add-every-10-seconds‘: {
‘task‘: ‘proj.s1.add1‘, #任务名称
‘schedule‘: 10.0, #每隔10秒钟执行一次
‘args‘: (16, 16) #该任务需要的参数
},
应用场景:
每天网上22点统计这一天的销售数据,
celery在Flask中的应用
创建一个存放celery的目录结构,该结构中必须有一个名叫celery的py文件.
目录结构为:
celery_celery
....celery_task
celery.py
s1.py(这个就是worker)
....templates
add_task.html
index.html
....app.py
celery.py 这个其实是celery的配置文件,在这个文件里可以放置celery的定时任务
#一定要有一个celery文件
from celery import Celery
#tasks任务名字,broker存放任务的,backend存放结果的
cel_obj = Celery(‘tasks‘,
broker=‘redis://127.0.0.1:6379‘,
backend=‘redis://127.0.0.1:6379‘,
include=[‘celery_task.s1‘])#include里放要执行的任务
s1.py 执行任务
import time
from .celery import cel_obj
@cel_obj.task
def hello(*args, **kwargs):
"""
执行任务
:param args:
:param kwargs:
:return:
"""
return "hello"
app.py文件
from flask import Flask,render_template,request,redirect
from celery.result import AsyncResult
from celery_task.s1 import hello
from celery_task.celery import cel_obj
app=Flask(__name__)
TASK_LIST=[]
@app.route(‘/index‘,methods=[‘GET‘])
def index():
return render_template(‘index.html‘,tasks=TASK_LIST)
@app.route(‘/add_task‘,methods=[‘GET‘,"POST"])
def add_task():
"""
添加任务
:return:
"""
if request.method=="GET":
return render_template(‘add_task.html‘)
else:
title=request.form.get(‘title‘)
#在celery中添加一个定时+任务,10s后执行
ctime_x =datetime.utcnow() + datetime.timedelta(seconds=10)
result=hello.apply_async(args=[1,3 ],eta=ctime_x)
TASK_LIST.append({"id":result.id ,"title":title})
return redirect(‘/index‘)
@app.route(‘/status‘)
def status():
"""
查看celery中运行的结果
:return:
"""
id = request.args.get(‘id‘)
# 根据id查看任务状态
try:
async = AsyncResult(id=id, app=cel_obj)
# async.revoke(terminate=True) # 无论现在是什么时候,都要终止
# async.revoke(terminate=False) # 如果任务还没有开始执行呢,那么就可以终止。
if async.successful():
result = async.get()
return "执行完成,结果是:%s" %result
# async.forget() # 将结果删除
elif async.failed():
return ‘执行失败‘
elif async.status == ‘PENDING‘:
return ‘任务等待中被执行‘
elif async.status == ‘RETRY‘:
return ‘任务异常后正在重试‘
elif async.status == ‘STARTED‘:
return ‘任务已经开始被执行‘
except Exception as e:
return "执行异常"
if __name__ == ‘__main__‘:
app.run(debug=True)
index.html


<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge"> <!--IE浏览器最高渲染-->
<meta name="viewport" content="width=device-width, initial-scale=1"> <!--为了确保适当的绘制和缩放-->
<title>Title</title>
<link rel="stylesheet" href="../bootstrap-3.3.7-dist/css/bootstrap.min.css">
</head>
<body>
<a href="/add_task">创建任务</a>
<table border="1">
<thead>
<tr>
<th>任务ID</th>
<th>任务名称</th>
<th>查看执行状态</th>
</tr>
</thead>
<tbody>
{% for task in tasks %}
<tr>
<td>{{task.id}}</td>
<td>{{task.title}}</td>
<td><a href="/status?id={{task.id}}">点击查看</a></td>
</tr>
{% endfor %}
</tbody>
</table>
<script src="../jquery-3.2.1.min.js"></script>
</body>
</html>
index.htmladd_task.html
<html lang="en" xmlns="http://www.w3.org/1999/html">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge"> <!--IE浏览器最高渲染-->
<meta name="viewport" content="width=device-width, initial-scale=1"> <!--为了确保适当的绘制和缩放-->
<title>添加任务</title>
<link rel="stylesheet" href="../bootstrap-3.3.7-dist/css/bootstrap.min.css">
</head>
<body>
<form method="post">
<input type="text" name="title">
<input type="submit" value="提交">
</form>
<script src="../jquery-3.2.1.min.js"></script>
</body>
</html>
add_task.html
项目概述:
1.当你在add.html页面中添加一个任务后,celery会立即给你返回一个id和你要创建的title.

2.在celery返回用户请求id的同时他会把用户请求放到redis中,然后worker中redis中取用户请求,
3.worker执行hello函数期间,如果用户点击查看执行状态,会执行status函数会被告知

4.woker中把hello函数执行完放到backend中等待取.等待用户调用status函数来从backend中获取.
执行步骤:
1.进入项目中执行 celery -A task worker -P gevent -c 1000 #task是celery文件夹的名字
2.运行我们的项目
效果图:
(py36) Asaaron:test_celery gongsi$ celery -A task worker -P gevent -c 1000
-------------- celery@Asaaron v4.3.0 (rhubarb)
---- **** -----
--- * *** * -- Darwin-18.6.0-x86_64-i386-64bit 2019-09-20 11:38:38
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x10cfea860
- ** ---------- .> transport: redis://127.0.0.1:6379//
- ** ---------- .> results: redis://127.0.0.1:6379/
- *** --- * --- .> concurrency: 1000 (gevent)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
总结:
#1celery是一个基于python实现的用于完成任务处理和任务调度组件。
#2.celery的依赖
1. redis或rabbitmq
#要是用celery必须有两个程序
1 worker 处理任务
2.我们自己的程序或项目:
添加任务到broker中,获取任务id
检查任务状态和查看任务结果:通过任务id从backend中拿结果
#在真实项目中要先运行worker再运行项目文件
#
@shared_task和@app.task的区别
当你在一个py文件中有两个Celery,并且这两个实例都要用到下边的这两个方法,这时候你就可以用@share_task,而app.task只能有一个方法使用
from celery import Celery,shared_task
import time
app1 = Celery(‘tasks‘,broker=‘redis://122.114.182.64:6379‘,backend=‘redis://122.114.182.64:6379‘)
app2 = Celery(‘tasks‘,broker=‘redis://122.114.182.64:6379‘,backend=‘redis://122.114.182.64:6379‘)
@shared_task
def f1(x,y):
time.sleep(5)
return x + y
@shared_task
def f2(x,y):
time.sleep(3)
return x-y
详见博客
现实中使用celery的场景
1.生成报告的生成
2.售货机出货
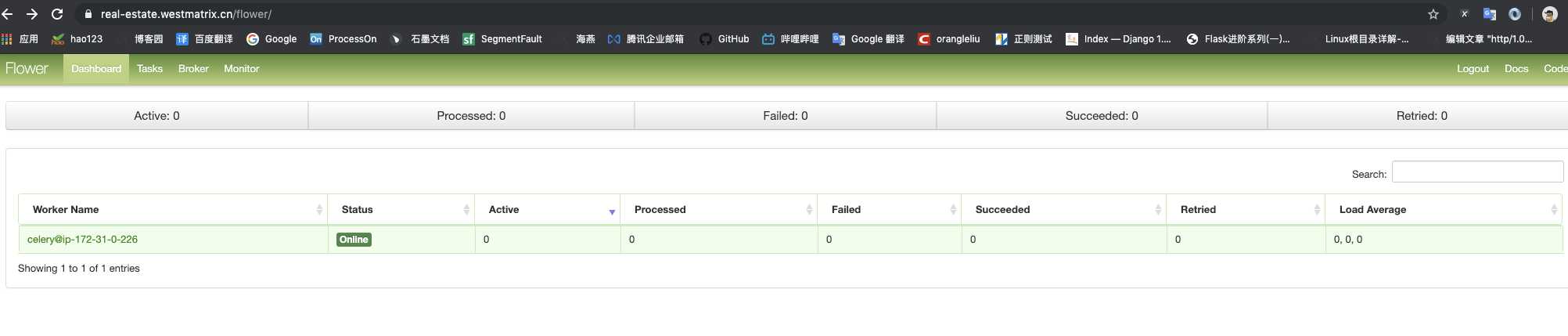
flower
官方文档
首先flower作为web页面来管理celery后台任务,和任务队列是隔离的,也就是flower的运行与否并不会影响到任务队列的真正执行,但是flower中可以通过API接口来管理celery中的任务执行。
1).查看任务历史,任务具体参数,开始时间等信息。
(2).提供图表和统计数据。
(3).实现全面的远程控制功能, 包括但不限于 撤销/终止任务, 关闭重启 worker, 查看正在运行任务。
(4).提供一个 HTTP API , 方便集成。
写的脚本
flower.py
import subprocess
cmd = [
‘flower‘,
‘--broker=redis://127.0.0.1:6379/0‘, # 监控的broker的地址
‘--basic_auth=root:123456‘, # 登录flower需要的用户名和密码
‘--port=5011‘, # flower需要的端口号
‘--url_prefix=flower‘ # 主页的路径前缀 比如:https://west.com/flower/
]
if __name__ == ‘__main__‘:
subprocess.run(cmd)
登录:127.0.0.1.:5011就可以看到