标签:store 文件分割 快速 oca 分割 副本 cin 使用 block
大数据与云计算的关系就像一枚硬币的正反面一样密不可分,大数据是云计算非常重要的应用场景,而云计算则为大数据的处理和数据挖掘都提供了最佳的技术解决方案。云计算的快速供给、弹性扩展以及按用量付费的优势已经给IT行业带来了巨大变化,它已经日益成为企业IT的首选。在让企业通过数据洞察提升效率和效益的同时,如何降低大数据平台成本也是IT部门经常关心的问题。
为什么用Azure Blob作为Hadoop分布式文件系统管理大数据?
HDFS是Hadoop集群分布式文件系统,它将文件分割为数据块Block,默认设置为64M,存储于数据节点DataNode中。为了降低机架失效所带来的数据丢失风险,HDFS会保存3份副本。公有云提供的存储,无论是磁盘存储还是对象存储,都是通过多份冗余来提高数据的可靠访问和安全,通常是3份。讲到这里可能大家已经发现,基于公有云虚拟机和磁盘构建的Hadoop集群,存储层面将会叠加产生更多份的冗余;同时磁盘存储相较于Blob对象存储价格要高,因此这种方案的总体成本会比较高。如果能采用Blob对象存储作为Hadoop集群文件系统管理大量数据则可以大大降低成本。
Hadoop能不能用云计算对象存储作为分布式文件系统?可以。从2015年开始,微软Azure向Apache Hadoop社区提供了hadoop-azure模块,Hadoop可以通过此云存储连接器集成Azure Blob存储(包括Azure Data Lake),使其像用HDFS一样存储和管理海量大数据,同时获得比较低廉的成本。除了Apache Hadoop,合并之后的Cloudera和Hortonworks旗下的CHD和HDP都很早就支持这一特性。Hadoop通过WASB协议访问Azure Blob,通过ADLS协议访问Azure Data Lake。Azure HDInsight服务是微软与Hortonworks合作已久的全托管大数据分析服务,其自身也是用Azure Blob作为默认文件系统。
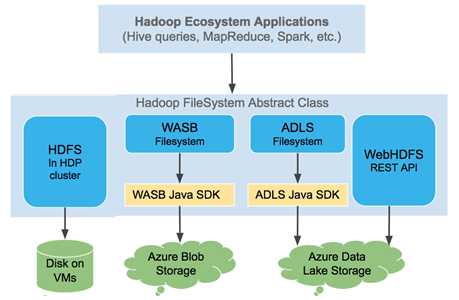
除了Azure Blob,AWS S3也可以作为Hadoop的分布式文件系统,GCP目前处于技术预览阶段。
下面通过HDP 2.6.5为例,简要介绍基于Azure Blob + VM搭建Hadoop集群方案。
1. 安装HDP 2.6.5
我们使用Ambari来安装配置HDP集群,步骤如下:
第一步:通过Azure ARM模板安装配置一个Ambari VM和若干个Hadoop VM. 这里要用到Azure CLI环境,请根据文档自行安装。
$ az group create -n rg-ryhdp01 -l westus2
$ az group deployment create -g rg-ryhdp01 --template-uri https://raw.githubusercontent.com/yongboyang/arm-templates/master/deployhdp26/azuredeploy.json
当虚拟机创建结束后,自定义脚本会在Ambari Server VM上执行如下操作:
. 下载Ambari Server软件包,并安装在Ambari VM
. 在所有部署VM的/etc/hosts中增加 IP 地址、FQDN和主机名
. 禁用所有VM的 iptables 和 Transparent Huge Page;iptables开启会导致服务不能启动
. 配置 ssh 密钥免密登录
第二步:使用Ambari 部署HDP 2.6.5集群
当ARM模板部署结束后,登录Ambari管理门户 http://ry-ambarisrv-n2.westus2.cloudapp.azure.com:8080/ 用户密码都是:admin
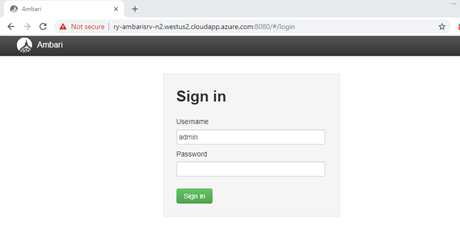
登录后点击 “Launch Install Wizard” 进入安装界面。
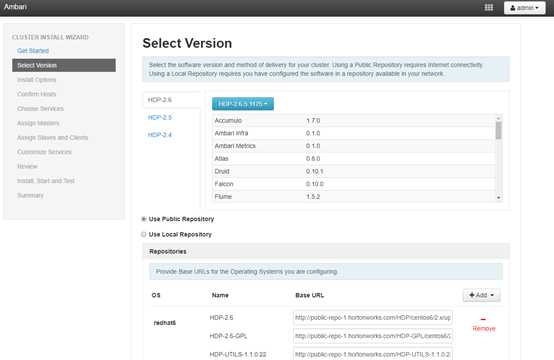
通过ssh登录 ry-ambarisrv-n2.westus2.cloudapp.azure.com,获取FQDN服务器列表以及私钥。用户密码:linuxadmin/MSLovesLinux!
$ sudu -s
$ cat /etc/hosts
$ cat /root/.ssh/id_rsa
将相关信息填写至安装页面,然后一路默认向下即可。过程中需要填写几个元数据服务管理和用户的密码。
2. 修改参数,配置Hive和HBase使用Azure Blob
创建一个GPv2存储账号,名称为:ryhdp。实际生产要考虑容量和性能,根据存储账号配额限制来使用一个或多个存储账号。
在Ambari管理门户中,选择HDFS->Configs->Advanced->Custom core-site,
#配置 HDFS Custom core-site
按照命名规则增加存储账号和访问密钥,fs.azure.account.key.<account name>.blob.core.windows.net=<key>,如果账号位于Azure中国,则使用Azure China对应域名fs.azure.account.key.<account name>.blob.core.chinacloudapi.cn=<key>
这里配置如下(可以增加多个存储账号):
fs.defaultFS=wasb://data@ryhdp.blob.core.windows.net
fs.azure.account.key.ryhdp.blob.core.windows.net=exyVpVnuBXXKcilWi2KBrCNtm9bGsyHbKsu1hdgNkJePqjQ+sDsllOoAJhR0MyqpokC2AFNpC256PkVQ8VJgQ==
fs.azure.page.blob.dir=/WALs,/oldWALs
fs.azure.page.blob.size=262144000
fs.azure.page.blob.extension.size=262144000
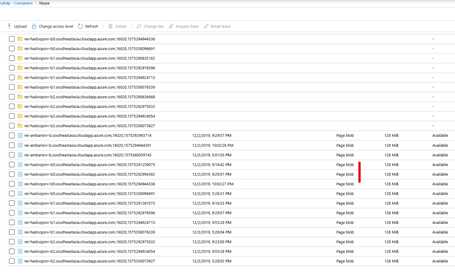
Azure Blob分Block Blob和Page Blob,二者不同,适用于不同场景。Block Blob为默认类型,适用于Hive, Pig,Map/Reduce任务等,每个文件最大200GB,单个文件吞吐带宽60MB/s;Page Blob最大可以为1TB,适合随机读写,适合HBase WAL。这里的fs.azure.page.blob.* 参数是用于配置Page Blob,HBase会将WAL和oldWAL日志写入page blob。默认是每个RegionServer有1个WAL,生产环境还可以根据需要通过配置hbase.wal.provider=multiwall 使用多个管道来并行写入多个WAL流,增加写入期间的总吞吐量。
#配置 hive-site.xml
fs.azure.account.key.ryhdp.blob.core.windows.net=nz3iBFEiW9dG+cfVut65cLV8m3ISMndYXUbvIgJZyl4WcqGypPzkq36sZQdCbaSV/kLoCD5apbrWvOUdl8mLxQ==
[hbase-site.xml]
hbase.rootdir=wasb://hbase@ryhdp.blob.core.windows.net/
然后重启HDFS,Hive和HBase服务。
3. 验证
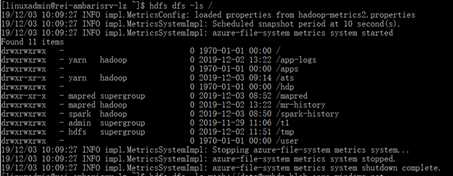
#通过HDFS 验证
设置fs.defaultFS=wasb://data@ryhdp.blob.core.windows.net,Hadoop FS将Azure Storage作为默认文件系统,因此hdfs dfs -ls / 查询结果为Azure Blob。
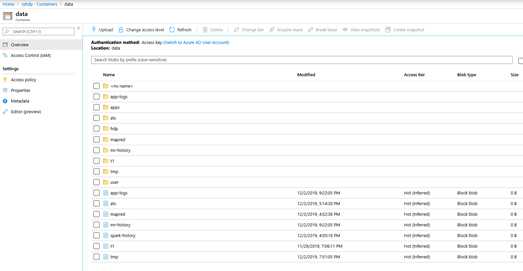
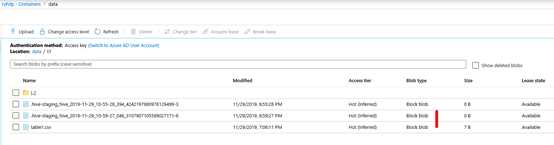
#通过Hive View验证工作正常,然后到存储账号中检查文件类型
CREATE EXTERNAL TABLE t1 (t1 string, t2 string, t3 string, t4 string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ STORED AS TEXTFILE
LOCATION ‘wasb://data@ryhdp.blob.core.windows.net/t1‘;
load data inpath ‘wasb://data@ryhdp.blob.core.windows.net/table1.csv‘ into table t1;
SELECT * FROM t1
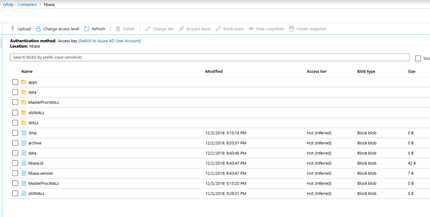
# 通过HBase Shell验证工作正常,然后到存储账号中检查文件类型
create ‘emp‘,‘personal data‘,‘professional data‘
put ‘emp‘,‘1‘,‘personal data:name‘,‘raju‘
put ‘emp‘,‘1‘,‘personal data:city‘,‘hyderabad‘
put ‘emp‘,‘1‘,‘professional data:designation‘,‘manager‘
put ‘emp‘,‘1‘,‘professional data:salary‘,‘50000‘
scan ‘emp‘
get ‘emp‘, ‘1‘
总结:
通过VM自建Hadoop集群,采用Azure Blob或Azure Data Lake管理大数据可以获得更高的性价比。如何将数据从HDFS迁移到Azure Blob?下回分解。
附录:
https://blogs.msdn.microsoft.com/cindygross/2015/02/03/why-wasb-makes-hadoop-on-azure-so-very-cool/
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-use-blob-storage
标签:store 文件分割 快速 oca 分割 副本 cin 使用 block
原文地址:https://www.cnblogs.com/royang/p/11978733.html