标签:process 多个 数据 session 时间 单位 认证 判断 set
为什么会有这些技术
什么是Cookie
Cookie具体指的是一段小信息,它是服务器发送出来存储在浏览器上的一组组键值对,下次访问服务器时浏览器会自动携带这些键值对,以便服务器提取有用信息。Cookie的原理
cookie的工作原理是:由服务器产生内容,浏览器收到请求后保存在本地;当浏览器再次访问时,浏览器会自动带上Cookie,这样服务器就能通过Cookie的内容来判断这个是“谁”了。保存在客户端浏览器上的键值对
cookie虽然是保存在客户端浏览器上的键值对
但是他是有服务端设置的
浏览器有权进制cookie的写入利用obj对象才可以操作cookie
obj = HTTPResponse()
return obj
obj = render()
return obj
obj = redirect()
return objset_cookie告诉浏览器设置cookie
obj.set_cookie('k1','k2')request.COOKIES.get(‘k1‘)request.COOKIES.get('k1')
获取浏览器携带过来的cookiemax_age = numobj.set_cookie('k1','k2',max_age=3)
obj.set_cookie('k1','k2',expires=3)
两个参数都是设置超时时间,并且都是以秒为单位
区别:
如果给IE浏览器设置cookie的超时时间只能使用expiresrequest.path_info 只获取urlrequest.get_full_path() 获取url+get请求的参数delete_cookie(‘k1‘)注销或退出登录
obj.delete_cookie('cookie名')简单版
def login(request):
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
if username == 'a' and password == '123':
# 登录成功,定位到主页home
obj = redirect('/home/')
# 设置cookie值,告诉浏览器保存键值对
obj.set_cookie('whoami','a')
return obj
return render(request,'login.html')
def home(request):
# 校验用户是否登录
if request.COOKIES.get('whoami'):
return HttpResponse('只有登录的用户才能访问')
# 否则返回登录界面
return redirect('/login/')
登录认证自动跳转
没有登录之前访问的界面,自动跳转到登录界面之后,登录成功直接跳转到登录之前界面
def login(request):
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
if username == 'a' and password == '123':
# 登录成功,获取登录之前的所在界面
old_path = request.GET.get('next')
# 也可能直接登录,存在则定向到old界面
if old_path:
obj = redirect(old_path)
else:
# 没有想要的网站直接跳转到主页
obj = redirect('/home/')
# 设置cookie值,告诉浏览器保存键值对
obj.set_cookie('whoami','a')
return obj
return render(request,'login.html')
# 装饰器函数
from functools import wraps
def login_auth(func):
@wraps(func)
def inner(request,*args,**kwargs):
# 判断当前用户是否登录
if request.COOKIES.get('whoami'):
res = func(request,*args,**kwargs)
return res
else:
# 获取用户的所输入地址
target_path = request.path_info
# 利用重定向携带参数
# http://127.0.0.1:8000/login/?next=/index/
return redirect('/login/?next=%s'%target_path)
return inner
@login_auth
def home(request):
return HttpResponse('登录之后才能查看')
@login_auth
def index(request):
return HttpResponse('index界面, 登录之后才能查看')
@login_auth
def reg(request):
return HttpResponse('reg界面, 登录之后才能查看')
保存在服务端上面的键值对
session的工作机制是依赖于cookie的
session流程解析

Cookie虽然在一定程度上解决了“保持状态”的需求,但是由于Cookie本身最大支持4096字节,以及Cookie本身保存在客户端,可能被拦截或窃取,因此就需要有一种新的东西,它能支持更多的字节,并且他保存在服务器,有较高的安全性。这就是Session。
问题来了,基于HTTP协议的无状态特征,服务器根本就不知道访问者是“谁”。那么上述的Cookie就起到桥接的作用。
我们可以给每个客户端的Cookie分配一个唯一的id,这样用户在访问时,通过Cookie,服务器就知道来的人是“谁”。然后我们再根据不同的Cookie的id,在服务器上保存一段时间的私密资料,如“账号密码”等等。
总结而言:Cookie弥补了HTTP无状态的不足,让服务器知道来的人是“谁”;但是Cookie以文本的形式保存在本地,自身安全性较差;所以我们就通过Cookie识别不同的用户,对应的在Session里保存私密的信息以及超过4096字节的文本。
另外,上述所说的Cookie和Session其实是共通性的东西,不限于语言和框架。
# 获取、设置、删除Session中数据
request.session['k1']
request.session.get('k1',None)
request.session['k1'] = 123
request.session.setdefault('k1',123) # 存在则不设置
del request.session['k1']
# 所有 键、值、键值对
request.session.keys()
request.session.values()
request.session.items()
request.session.iterkeys()
request.session.itervalues()
request.session.iteritems()
# 会话session的key
request.session.session_key
# 将所有Session失效日期小于当前日期的数据删除
request.session.clear_expired()
# 检查会话session的key在数据库中是否存在
request.session.exists("session_key")
# 删除当前会话的所有Session数据
request.session.delete()
# 删除当前的会话数据并删除会话的Cookie。
request.session.flush()
这用于确保前面的会话数据不可以再次被用户的浏览器访问
例如,django.contrib.auth.logout() 函数中就会调用它。
# 设置会话Session和Cookie的超时时间
request.session.set_expiry(value)
* 如果value是个整数,session会在些秒数后失效。
* 如果value是个datatime或timedelta,session就会在这个时间后失效。
* 如果value是0,用户关闭浏览器session就会失效。
* 如果value是None,session会依赖全局session失效策略。
session[k]=vrequest.session['k'] = 'v'
可以设置多个session,服务端数据库只有一条信息
获取时,明文获取即可
第一次设置的时候会报错,因为没有执行数据库的迁移命令,生成django需要用到的一些默认表(django_session)
django默认的session失效时间是14天 两周
django session在创建数据的时候,是针对浏览器,多条数据多个浏览器
执行的发生顺序
? 随机字符串 加密之后的数据 失效时间
? sfdfs dsdfsadfsdf 推延2周
将产生的随机字符串返回给客户端浏览器,让浏览器保存
以sessionid:随机字符串形式保存
session.getrequest.session.get('k')
发生的顺序
request.session中供程序员调用,如果没有就是一个空字典session.delete()只会根据浏览器的不同删除对应的数据
客户端和服务端全部删除,只会根据浏览器的不同删除对应的数据
request.session.delete()
只删除客户端的
request.session.flush()
set_expiry(value)request.session.set_expiry(value)
能够作为数据库的有哪些
数据库软件
关系型
非关系型
文件
内存
django中默认支持session,内部提供了5种类型的session供开发者使用
1. 数据库Session
SESSION_ENGINE = 'django.contrib.sessions.backends.db' # 引擎(默认)
2. 缓存Session
SESSION_ENGINE = 'django.contrib.sessions.backends.cache' # 引擎
SESSION_CACHE_ALIAS = 'default' # 使用的缓存别名(默认内存缓存,也可以是memcache),此处别名依赖缓存的设置
3. 文件Session
SESSION_ENGINE = 'django.contrib.sessions.backends.file' # 引擎
SESSION_FILE_PATH = None # 缓存文件路径,如果为None,则使用tempfile模块获取一个临时地址tempfile.gettempdir()
4. 缓存+数据库
SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db' # 引擎
5. 加密Cookie Session
SESSION_ENGINE = 'django.contrib.sessions.backends.signed_cookies' # 引擎
其他公用设置项:
SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串(默认)
SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径(默认)
SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名(默认)
SESSION_COOKIE_SECURE = False # 是否Https传输cookie(默认)
SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输(默认)
SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)(默认)
SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期(默认)
SESSION_SAVE_EVERY_REQUEST = False # 是否每次请求都保存Session,默认修改之后才保存(默认)
加密字符串
加密算法 xxx
username 》(xxx)》 随机字符串
username + 随机字符串
1、很久很久以前,Web 基本上就是文档的浏览而已, 既然是浏览,作为服务器, 不需要记录谁在某一段时间里都浏览了什么文档,每次请求都是一个新的HTTP协议, 就是请求加响应, 尤其是我不用记住是谁刚刚发了HTTP请求, 每个请求对我来说都是全新的。这段时间很嗨皮
2、但是随着交互式Web应用的兴起,像在线购物网站,需要登录的网站等等,马上就面临一个问题,那就是要管理会话,必须记住哪些人登录系统, 哪些人往自己的购物车中放商品, 也就是说我必须把每个人区分开,这就是一个不小的挑战,因为HTTP请求是无状态的,所以想出的办法就是给大家发一个会话标识(session id), 说白了就是一个随机的字串,每个人收到的都不一样, 每次大家向我发起HTTP请求的时候,把这个字符串给一并捎过来, 这样我就能区分开谁是谁了
3、这样大家很嗨皮了,可是服务器就不嗨皮了,每个人只需要保存自己的session id,而服务器要保存所有人的session id ! 如果访问服务器多了, 就得由成千上万,甚至几十万个。
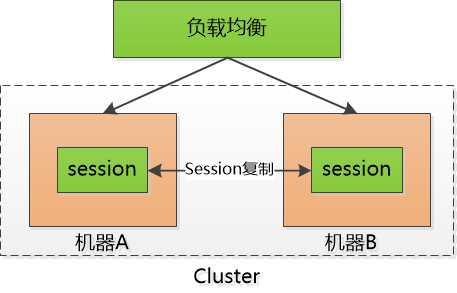
这对服务器说是一个巨大的开销 , 严重的限制了服务器扩展能力, 比如说我用两个机器组成了一个集群, 小F通过机器A登录了系统, 那session id会保存在机器A上, 假设小F的下一次请求被转发到机器B怎么办? 机器B可没有小F的 session id啊。
有时候会采用一点小伎俩: session sticky , 就是让小F的请求一直粘连在机器A上, 但是这也不管用, 要是机器A挂掉了, 还得转到机器B去。
那只好做session 的复制了, 把session id 在两个机器之间搬来搬去, 快累死了。
后来有个叫Memcached的支了招: 把session id 集中存储到一个地方, 所有的机器都来访问这个地方的数据, 这样一来,就不用复制了, 但是增加了单点失败的可能性, 要是那个负责session 的机器挂了, 所有人都得重新登录一遍, 估计得被人骂死。
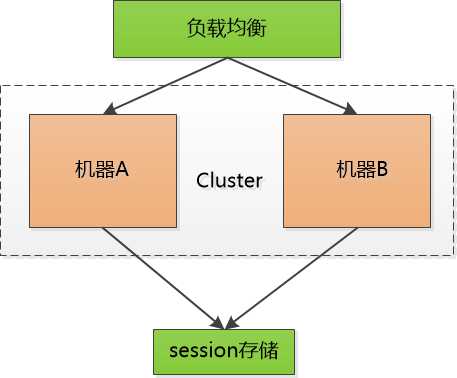
也尝试把这个单点的机器也搞出集群,增加可靠性, 但不管如何, 这小小的session 对我来说是一个沉重的负担
4 于是有人就一直在思考, 我为什么要保存这可恶的session呢, 只让每个客户端去保存该多好?
可是如果不保存这些session id , 怎么验证客户端发给我的session id 的确是我生成的呢? 如果不去验证,我们都不知道他们是不是合法登录的用户, 那些不怀好意的家伙们就可以伪造session id , 为所欲为了。
嗯,对了,关键点就是验证 !
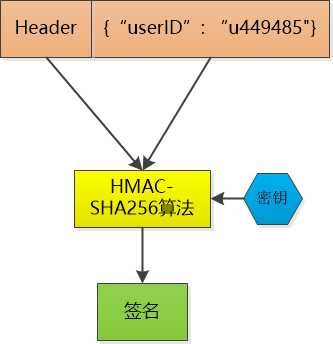
比如说, 小F已经登录了系统, 我给他发一个令牌(token), 里边包含了小F的 user id, 下一次小F 再次通过Http 请求访问我的时候, 把这个token 通过Http header 带过来不就可以了。
不过这和session id没有本质区别啊, 任何人都可以可以伪造, 所以我得想点儿办法, 让别人伪造不了。
那就对数据做一个签名吧, 比如说我用HMAC-SHA256 算法,加上一个只有我才知道的密钥, 对数据做一个签名, 把这个签名和数据一起作为token , 由于密钥别人不知道, 就无法伪造token了。
这个token 我不保存, 当小F把这个token 给我发过来的时候,我再用同样的HMAC-SHA256 算法和同样的密钥,对数据再计算一次签名, 和token 中的签名做个比较, 如果相同, 我就知道小F已经登录过了,并且可以直接取到小F的user id , 如果不相同, 数据部分肯定被人篡改过, 我就告诉发送者: 对不起,没有认证。
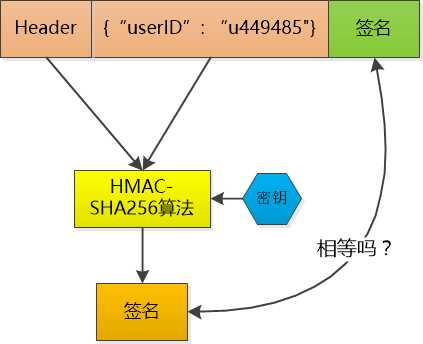
Token 中的数据是明文保存的(虽然我会用Base64做下编码, 但那不是加密), 还是可以被别人看到的, 所以我不能在其中保存像密码这样的敏感信息。
当然, 如果一个人的token 被别人偷走了, 那我也没办法, 我也会认为小偷就是合法用户, 这其实和一个人的session id 被别人偷走是一样的。
这样一来, 我就不保存session id 了, 我只是生成token , 然后验证token , 我用我的CPU计算时间获取了我的session 存储空间 !
解除了session id这个负担, 可以说是无事一身轻, 我的机器集群现在可以轻松地做水平扩展, 用户访问量增大, 直接加机器就行。 这种无状态的感觉实在是太好了!
https://www.cnblogs.com/Dominic-Ji/p/9229509.html
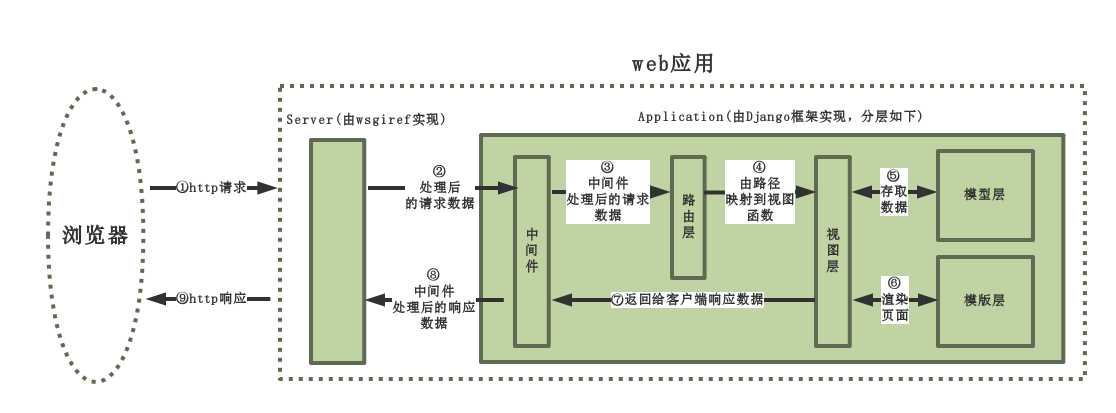
中间件是在request和response处理过程中的一个插件。
比如在request到达视图函数之前,我们可以使用中间件来做一些相关的事情,比如可以判断当前这个用户有没有登录,如果登录了,就绑定一个user对象到request上。
也可以在response到达浏览器之前,做一些相关的处理,比如想要统一在response上设置一些cookie信息等。
django中默认有七个中间件
只要想要做一些网站的全局性功能,应该考虑使用django的中间件
全局性的用户登录校验
全局的用户访问频率校验
全局的用户权限校验
django中间件是所有框架中做的最完善的
对象,字符串 === 反射
全局 === 中间件
并且支持用户自定义中间件,然后暴露给用户五个可以自定义的方法
需要掌握
需要了解
上面的五个方法,会在特定的阶段自动触发
如果形参中含有response,那么必须要返回
中间件所处的位置没有规定。只要是放到项目当中即可。
一般分为两种情况,如果中间件是属于某个app的,那么可以在这个app下面创建一个python文件用来存放这个中间件,也可以专门创建一个Python包,用来存放本项目的所有中间件。
创建中间件有两种方式,一种是使用函数,一种是使用类,接下来对这两种方式做个介绍:
# 自定义类中间件
class MyMdd1(MiddlewareMixin):
def process_request(self,request):
print('我是第一个中间件里的process_request方法')
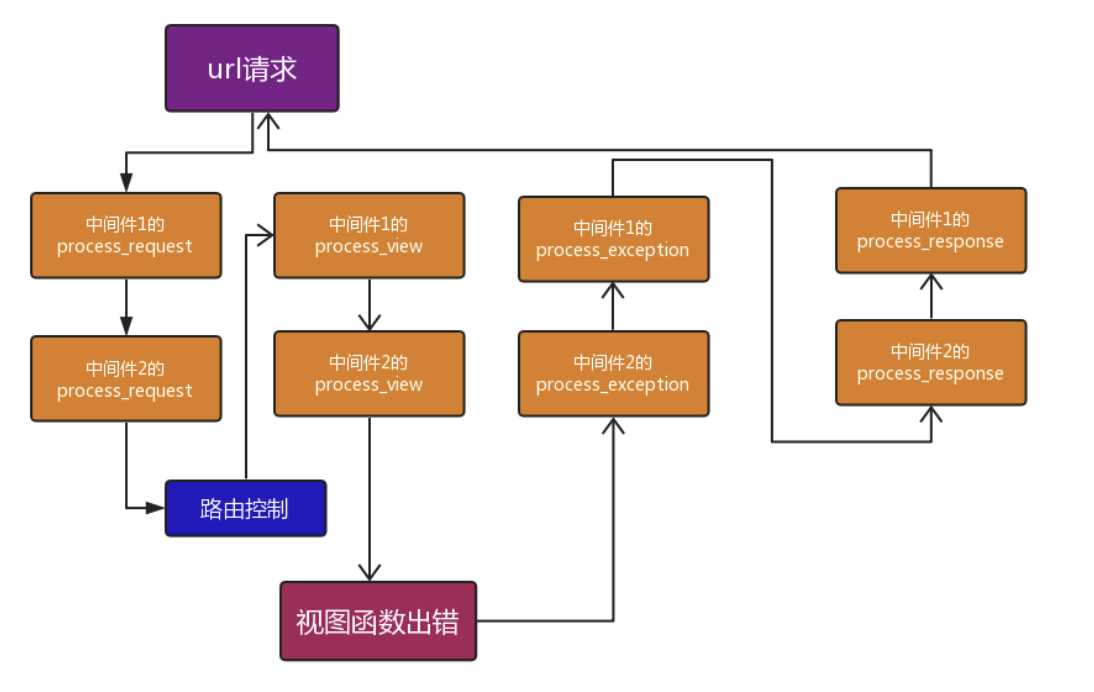
请求来的时候会按照settings配置文件中从上至下的顺序,依次执行每一个中间件内部定义的process_ request方法,如果中间件内部没有改方法,直接跳过执行下一个中间件
该方法一旦返回了HttpResponse对象,那么请求会立刻停止往后走,原路返回
当process_request方法直接返回HttpResponse对象之后
会直接从当前中间件里面的process_respone往回走
没有执行的中间件都不会再执行
自定义中间件
class MyMdd1(MiddlewareMixin):
def process_response(self,request,response):
print('我是第一个中间件里的process_response方法')
# 必须返回response
return response
process_response方法 def process_view(self,request,view_name,*args,**kwargs):
print('我是第一个中间件里面的process_view方法')
def process_exception(self,request,exception):
username
print('我是第一个中间件process_exception方法')
print(exception)
视图函数
def mdzz(request):
print('== 我的视图函数mdzz ==')
def render():
return HttpResponse('自定义一个render函数')
obj = HttpResponse('获取http对象')
# 给对象赋值了render属性
obj.render = render()
return obj
视图函数中,当你返回的对象中含有render属性指向的是一个render方法的时候才会触发,从下往上的顺序
process_template_response(self, request, response)
它的参数,一个HttpRequest对象,response是TemplateResponse对象(由视图函数或者中间件产生)。
process_template_response是在视图函数执行完成后立即执行,但是它有一个前提条件,那就是视图函数返回的对象有一个render()方法(或者表明该对象是一个TemplateResponse对象或等价方法)。
自定义中间件
1.app下创建文件夹,里面是保存中间件的.py文件
2.在py文件中新建中间件类,并且在settings中注册中间件的地址
-------------------------------------------------------
from django.utils.deprecation import MiddlewareMixin
# 自定义类中间件
class MyMdd1(MiddlewareMixin):
def process_request(self,request):
print('我是第一个中间件里的process_request方法')
def process_response(self,request,response):
print('我是第一个中间件里的process_response方法')
# 必须返回response
return response
def process_view(self,request,view_name,*args,**kwargs):
print(view_name)
print('我是第一个中间件里面的process_view方法')
def process_exception(self,request,exception):
print('我是第一个中间件process_exception方法')
print(exception)
class MyMdd2(MiddlewareMixin):
def process_request(self, request):
print('我是第二个中间件里的process_request方法')
def process_response(self,request,response):
print('我是第二个中间件里的process_response方法')
# 必须返回response
return response
def process_view(self,request,view_name,*args,**kwargs):
print(view_name)
print('我是第二个中间件里面的process_view方法')
def process_exception(self,request,exception):
print('我是第二个中间件process_exception方法')
print(exception)
标签:process 多个 数据 session 时间 单位 认证 判断 set
原文地址:https://www.cnblogs.com/fwzzz/p/11986431.html